
深入浅出 linux 内核源代码之双向链表 list_head
原创文章,转载请注明出处,谢谢!
作者:清林,博客名:飞空静渡
范金宝
email:fjb2080@163.com
blog:http://blog.csdn.net/fjb2080
前言:在 linux 源代码中有个头文件为 list.h。很多 linux 下的源代码都会使用这个头文件,它里面定义
了一个结构,以及定义了和其相关的一组函数,这个结构是这样的:
struct list_head{
struct list_head *next, *prev;
};
那么这个头文件又是有什么样的作用呢,这篇文章就是用来解释它的作用,虽然这是 linux 下的源代码,但对
于学习 C 语言的人来说,这是算法和平台没有什么关系。
一、双向链表
学习计算机的人都会开一门课程《数据结构》,里面都会有讲解双向链表的内容。
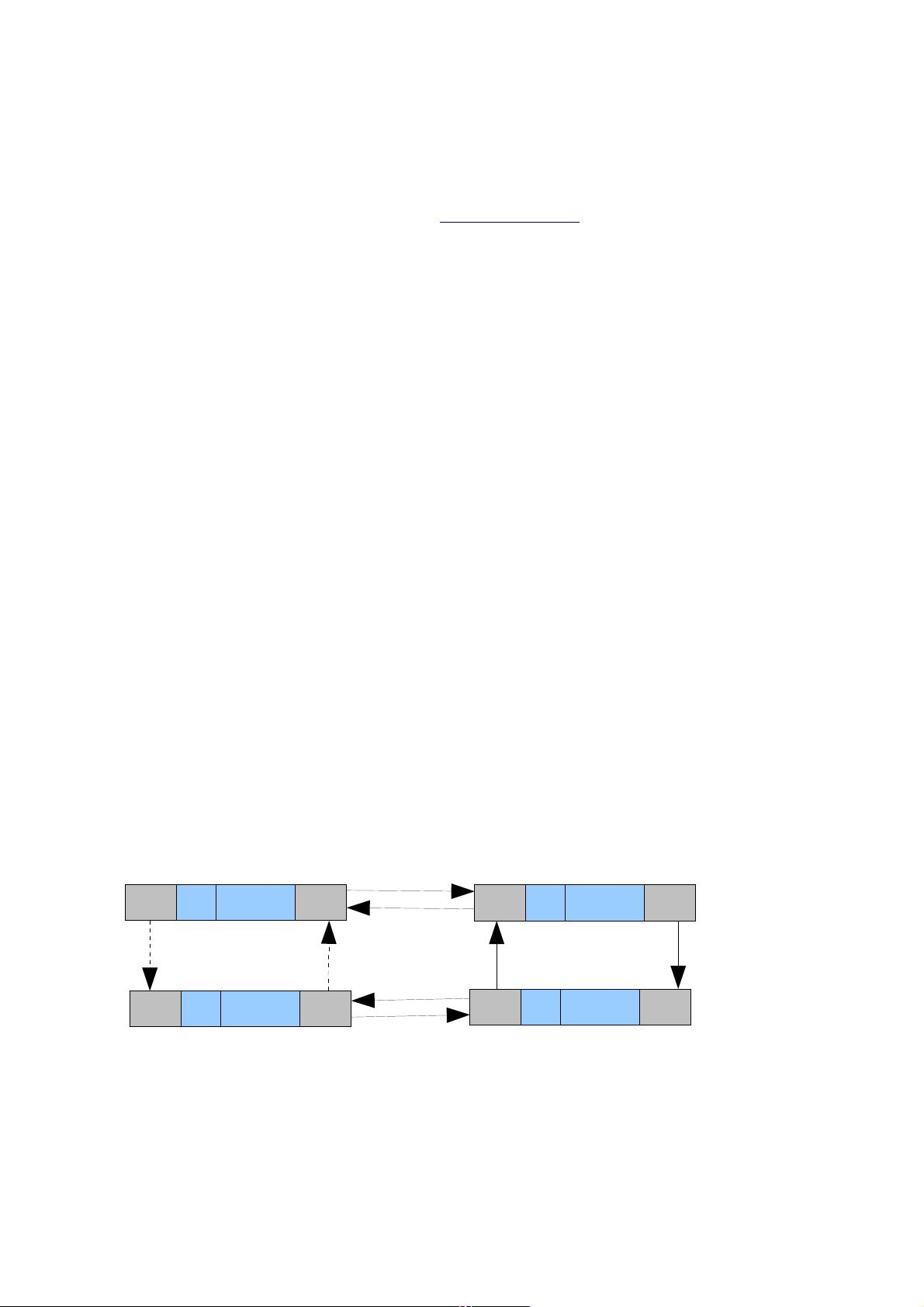
什么是双向链表,它看起来是这样的:
struct dlist
{
int no;
void* data;
struct dlist *prev, *next;
};
它的图形结构图如下:
如果是双向循环链表,那么就加上虚线所示。
现在有几个结构体,它们是:
表示人的:
struct person
{
nextprev no data
nextprev no data
nextprev no data
nextprev no data
http://blog.csdn.net/fjb2080


剩余14页未读,继续阅读
资源评论

 win32_msblast2013-08-12pdf文档,很详细。实用教材。
win32_msblast2013-08-12pdf文档,很详细。实用教材。- 死神在世2013-09-05很不错,讲解的很详细...











