***************/
第三章习题参考答案
P64–7
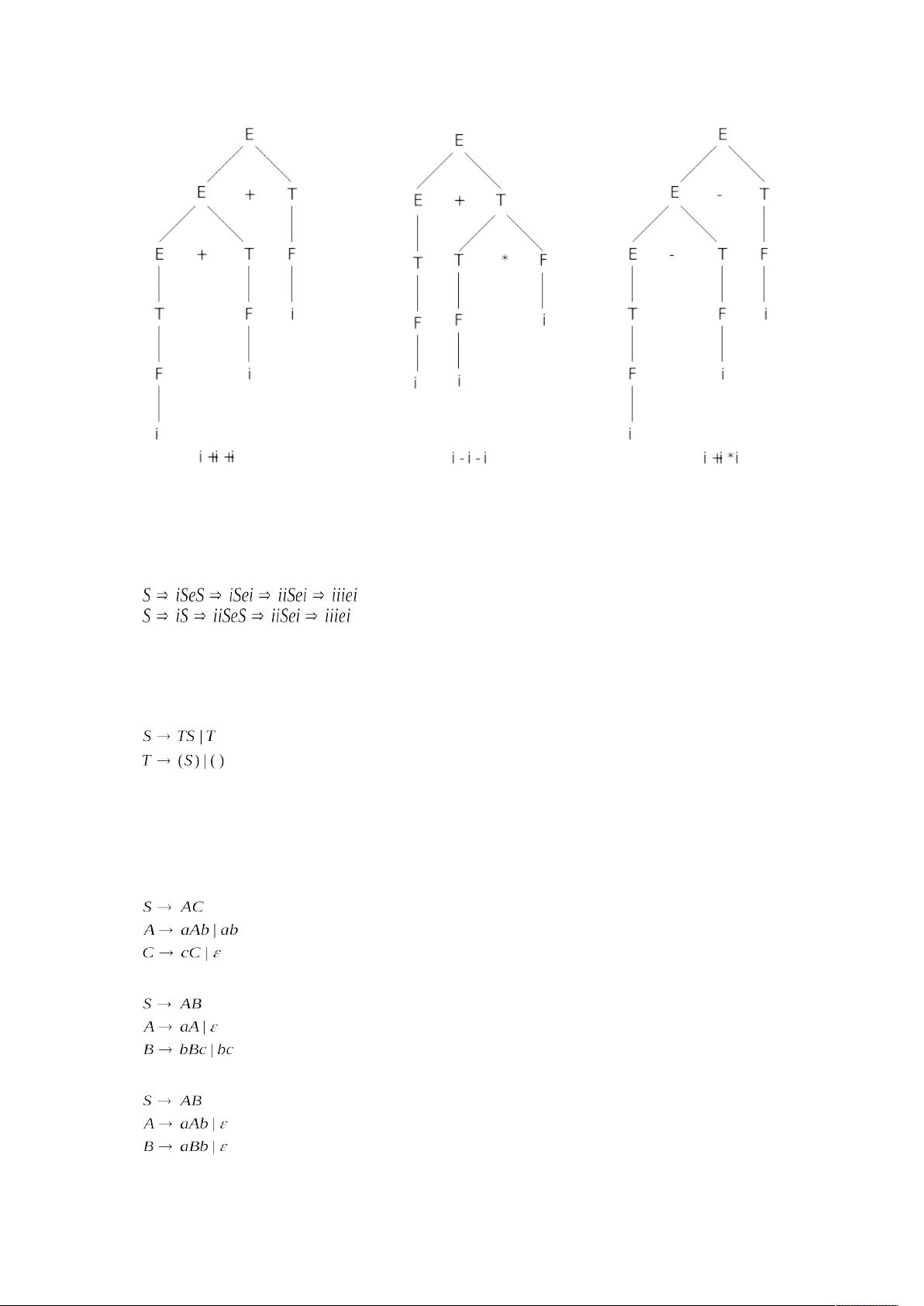
(1)
0
1 1 0 1
1
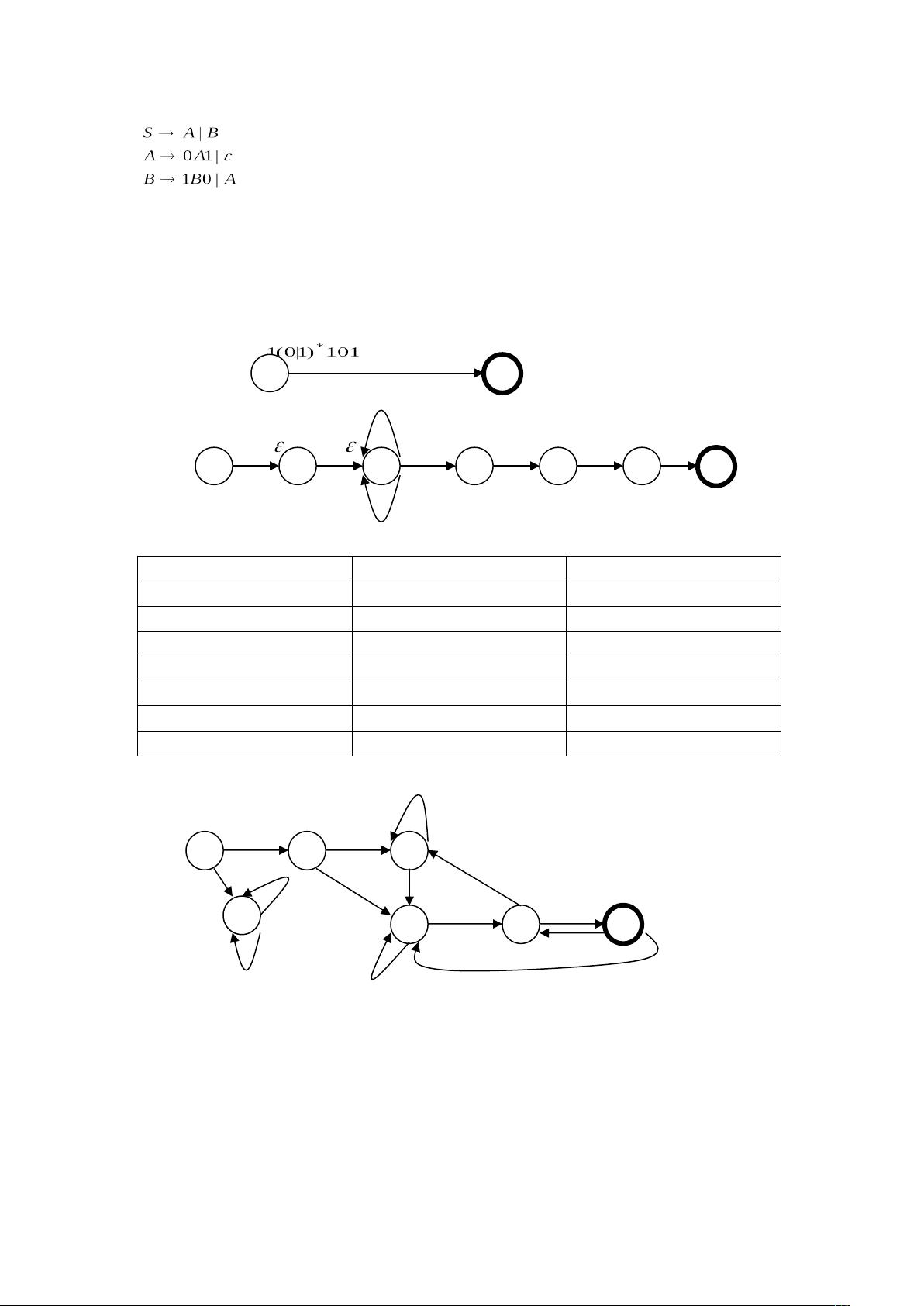
确定化:
0 1
{X} φ {1,2,3}
φ φ φ
{1,2,3} {2,3} {2,3,4}
{2,3} {2,3} {2,3,4}
{2,3,4} {2,3,5} {2,3,4}
{2,3,5} {2,3} {2,3,4,Y}
{2,3,4,Y} {2,3,5} {2,3,4,}
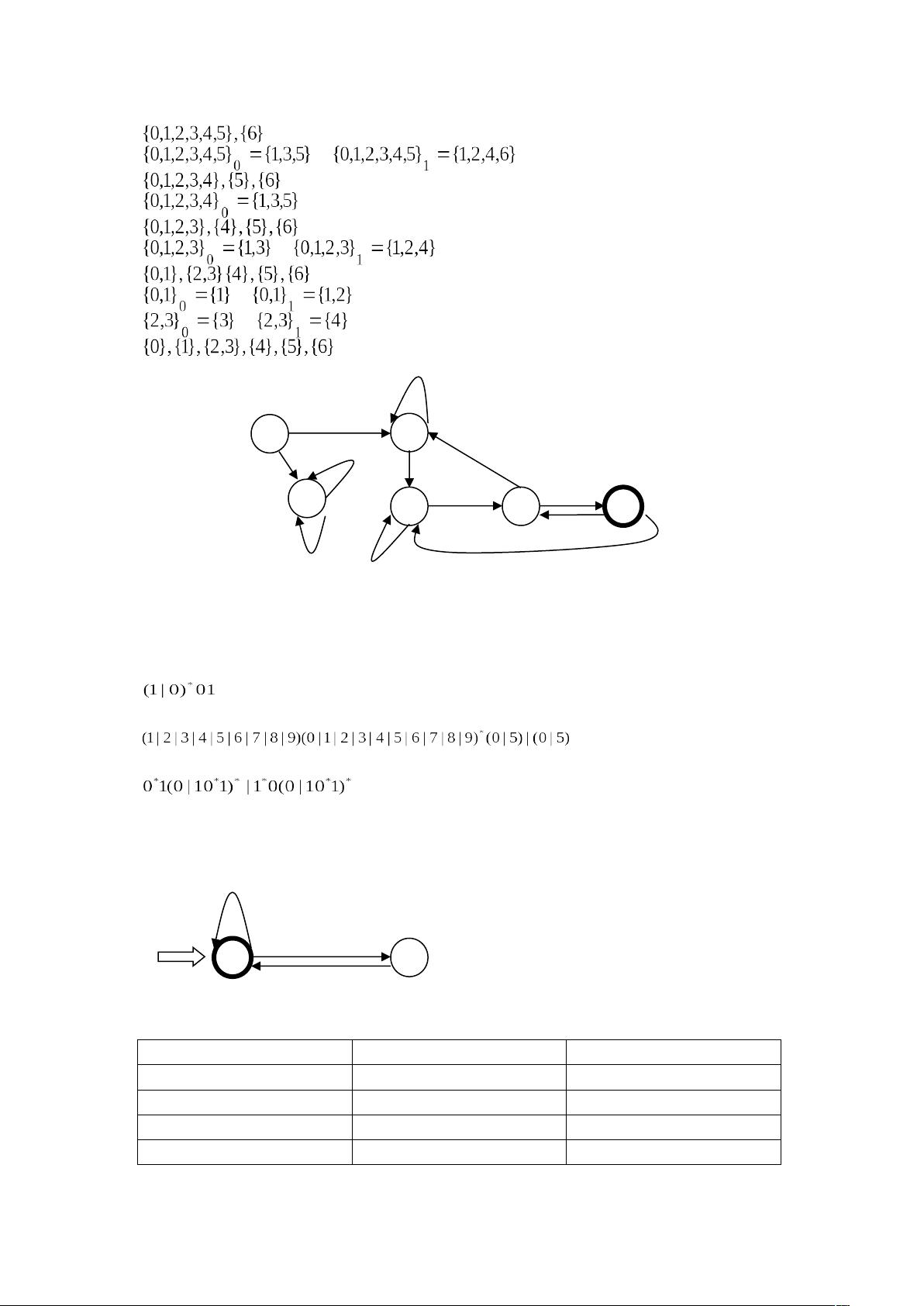
0
1 0
0 0 1 1 0
0 1
0
1
1 1
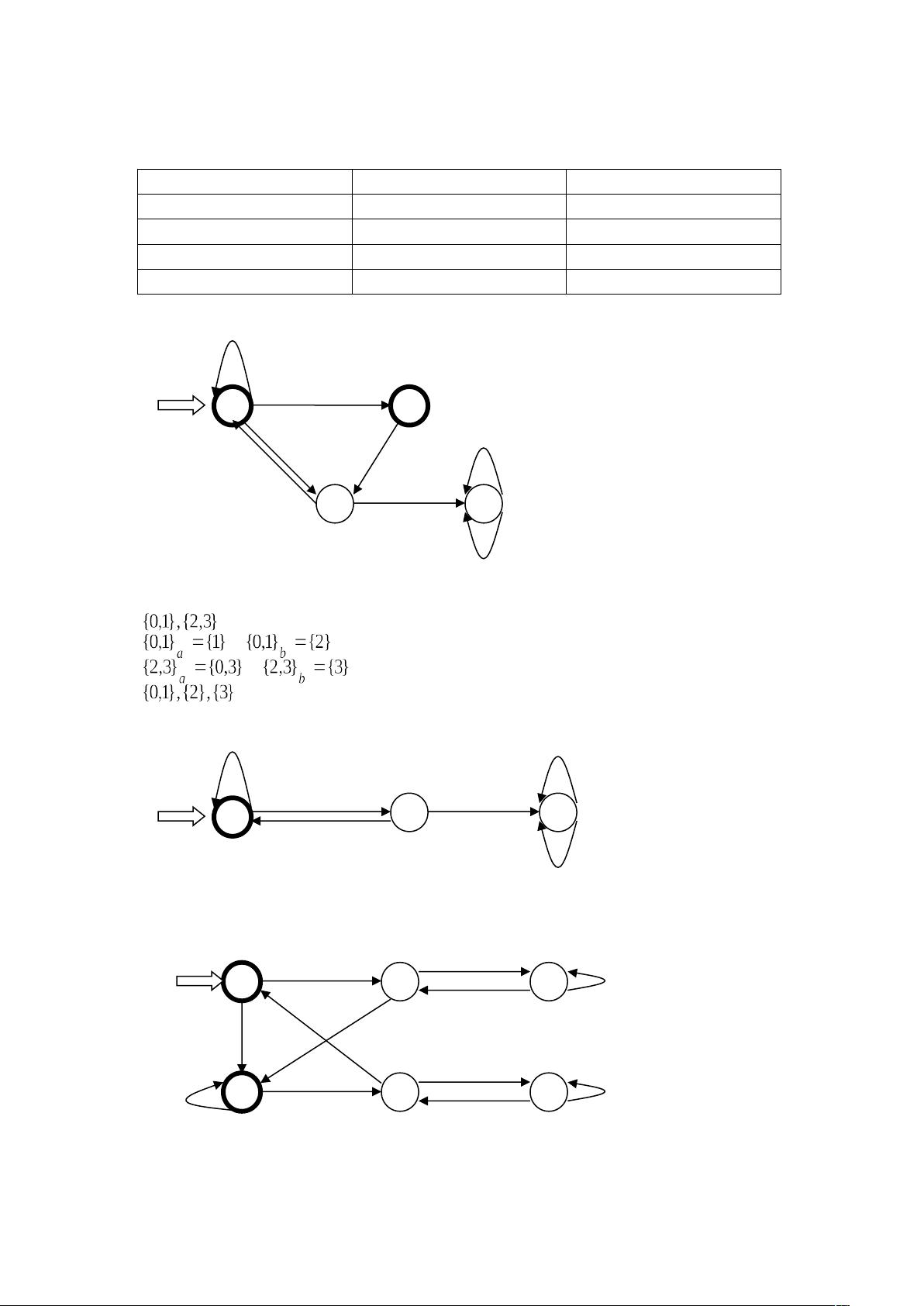
最小化:
X 1 2 3 4
Y
5
X Y
6
0
1
2 3
54