
Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC
简称 Cabac,H264 中的一种熵编码方式:基于上下文的自适应二进制算术编码
内容安排:1,介绍算术编码 2,介绍二进制算术编码 3 介绍 Cabac 及其一些实
用的实现方式(参考 JSVM 代码,也可以参考 JM) ---张新发
一,算术编码
算术编码是一种常用的变字长编码,它是利用信源概率分布特性、能够趋
近熵极限的编码方法。它与 Huffman 一样,也是对出现概率大的符号赋予短码,
对概率小的符号赋予长码。但它的编码过程与 Huffman 编码却不相同,而且在
信源概率分布比较均匀的情况下其编码效率高于 Huffman 编码。它和 Huffman
编码最大的区别在于它不是使用整数码。Huffman 码是用整数长度的码字来编
码的最佳方法,而算法编码是一种并不局限于整数长度码字的最佳编码方法。
算术编码是把各符号出现的概率表示在单位概率 [0,1] 区间之中,区间的宽度
代表概率值的大小。符号出现的概率越大对应于区间愈宽,可用较短码字表示;
符号出现概率越小对应于区间愈窄,需要较长码字表示。 举例如下:
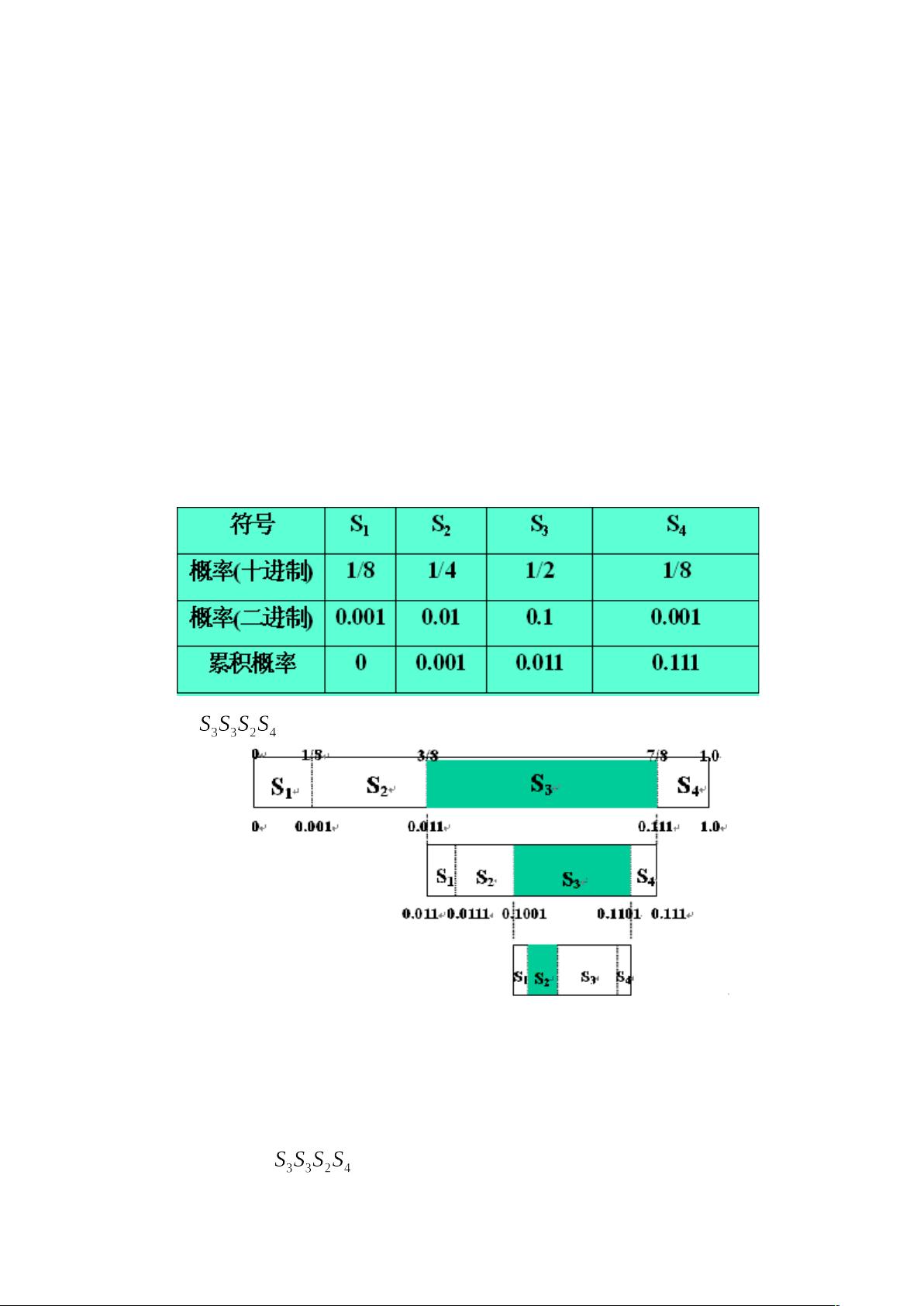
以符号 为例
在算术编码中通常采用二进制分数表示概率,每个符号所对应的概率区间
都是半 开 区 间,即该 区 间 包括左端 点 , 而不包括右端 点 , 如 S1 对应 [0,
0.001),S2 对应 [0.001, 0.01) 等。
算术编码产生的码字实际上是一个二进制数值的指针,指向所编的符号对
应的概率区间。
符号序列 …… 的第一个符号 S3 用指向第 3 个子区间的指针来


剩余16页未读,继续阅读
资源评论

 子非鱼_s2015-08-20对于算术编码的理解很与帮助
子非鱼_s2015-08-20对于算术编码的理解很与帮助













