14. regcomp(®,pattern,cflags);//编译正则模式
15. status=regexec(®,buf,nmatch,0);//执行正则表达式和缓存的比较
16. if(status==REG_NOMATCH)
17. printf("Nomatch\n");
18. elseif(0==status)
19. {
20. printf("比较成功:");
21. for(i=pmatch[0].rm_so;i<pmatch[0].rm_eo;++i)putchar(buf[i]);
22. printf("\n");
23. }
24. regfree(®);
25. return0;
26. }
正则表达式由一些普通字符和一些元字符(#"##!)组成。普通字
符包括大小写的字母和数字,而元字符则具有特殊的含义。
在最简单的情况下,一个正则表达式看上去就是一个普通的查找串。
例 如 , 正 则 表 达 式 I!I 中 没 有 包 含 任 何 元 字 符 , 它 可 以 匹
配I!I和I!I等字符串,但是不能匹配I/!I。
元字符描述如下:
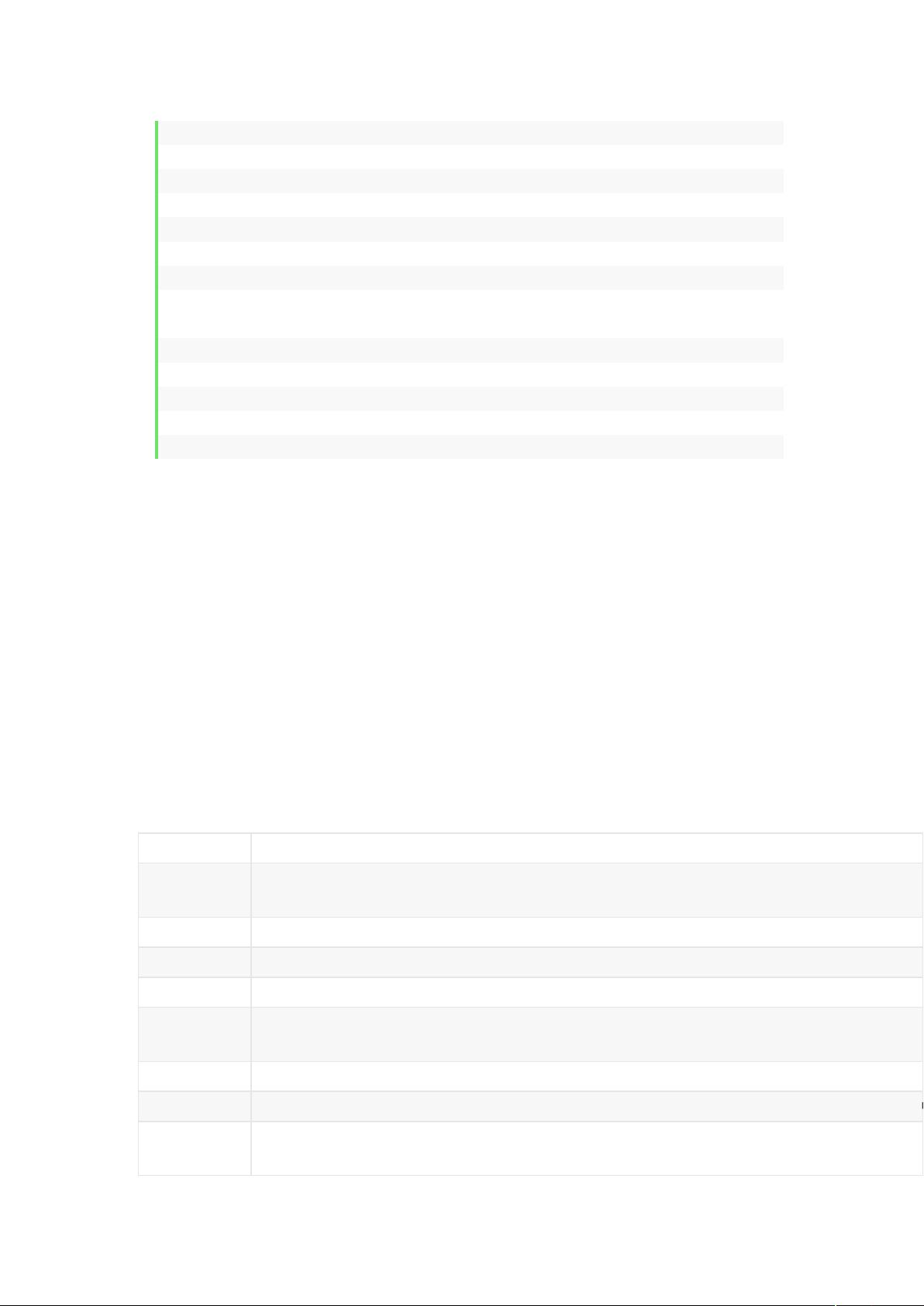
元字符 描述
\
将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“
匹配\n。“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。
^
匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^也匹配“\n”或“\r”之后的位置。
$
匹配输入字符串的结束位置。如果设置了 RegExp 对象的 Multiline 属性,$也匹配“\n”或“\r”之前的位置。
*
匹配前面的子表达式零次或多次(大于等于 0 次)。例如,zo*能匹配“z”,“zo”以及“zoo”。*等价于
+
匹配前面的子表达式一次或多次(大于等于 1 次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“
于{1,}。
?
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}
{n}
n 是一个非负整数。匹配确定的 n 次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个
{n,}
n 是一个非负整数。至少匹配 n 次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有
o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。