# Create new entityset
es = ft.EntitySet(id = 'customers')
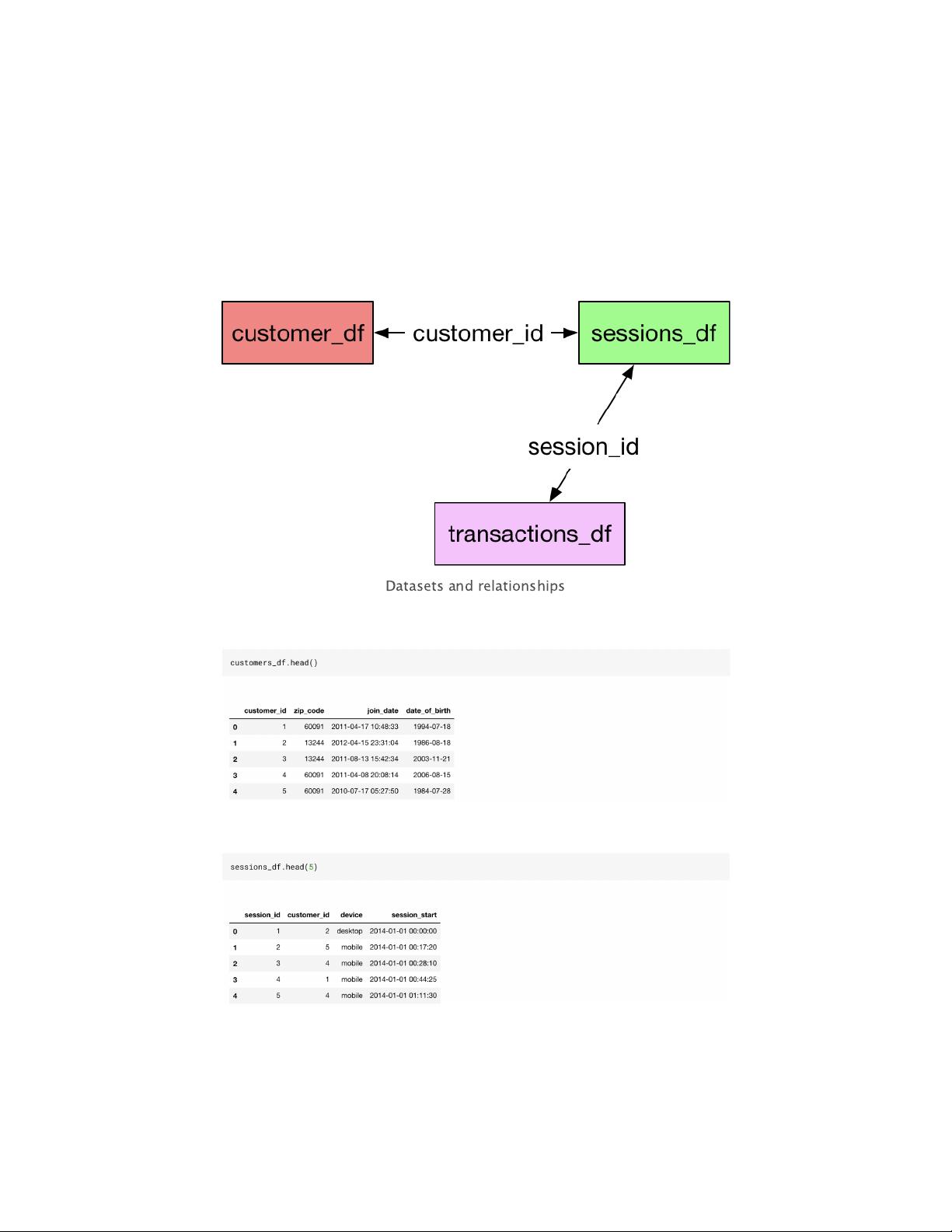
Let us add our dataframes to it. The order of adding dataframes is not
important. To add a dataframe to an existing entityset, we do the
below operation.
# Create an entity from the customers dataframe
es = es.entity_from_dataframe(entity_id = 'customers',
dataframe = customers_df, index = 'customer_id',
time_index = 'join_date' ,variable_types =
{"zip_code": ft.variable_types.ZIPCode})
So here are a few things we did here to add our dataframe to the
empty entityset bucket.
Provided a entity_id : This is just a name. Put it as customers.
dataframe name set as customers_df
index : This argument takes as input the primary key in the
table
time_index : The timeindex is defined as the first time that
any information from a row can be used. For customers, it is the
joining date. For transactions, it will be the transaction time.
variable_types : This is used to specify if a particular variable
must be handled differently. In our Dataframe, we have the
zip_code variable, and we want to treat it differently, so we use
this. These are the different variable types we could use:
[featuretools.variable_types.variable.Datetime,
featuretools.variable_types.variable.Numeric,
featuretools.variable_types.variable.Timedelta,
featuretools.variable_types.variable.Categorical,
featuretools.variable_types.variable.Text,
featuretools.variable_types.variable.Ordinal,
featuretools.variable_types.variable.Boolean,
1.
2.
3.
4.
5.