

引言
我们都听过 cache,当你问他们是什么是缓存的时候,他们会给你一个完美的答案,可是他们不知道缓
存是怎么构建的,或者没有告诉你应该采用什么标准去选择缓存框架。在这边文章,我们会去讨论缓存,
缓存算法,缓存框架以及哪个缓存框架会更好。
面试
“缓存就是存贮数据(使用频繁的数据)的临时地方,因为取原始数据的代价太大了,所以我可以取得
快一些。”
这就是 programmer one (programmer one 是一个面试者)在面试中的回答(一个月前,他向公
司提交了简历,想要应聘要求在缓存,缓存框架,大规模数据操作有着丰富经验的 java 开发职位)。
programmer one 通过 hash table 实现了他自己的缓存,但是他知道的只是他的缓存和他那存储着
150 条记录的 hash table,这就是他认为的大规模数据(缓存 = hashtable,只需要在 hash table
查找就好了),所以,让我们来看看面试的过程吧。
面试官:你选择的缓存方案,是基于什么标准的?
programmer one:呃,(想了 5 分钟)嗯,基于,基于,基于数据(咳嗽……)
面试官:excese me ! 能不能重复一下?
programmer one:数据?!
面试官:好的。说说几种缓存算法以及它们的作用
programmer one:(凝视着面试官,脸上露出了很奇怪的表情,没有人知道原来人类可以做出这种表
情 )
面试官:好吧,那我换个说法,当缓存达到容量时,会怎么做?
programmer one:容量?嗯(思考……hash table 的容量时没有限制的,我能任意增加条目,它会
自动扩充容量的)(这是 programmer one 的想法,但是他没有说出来)
面试官对 programmer one 表示感谢(面试过程持续了 10 分钟),之后一个女士走过来说:谢谢你
的时间,我们会给你打电话的,祝你好心情。这是 programmer one 最糟糕的面试(他没有看到招聘
对求职者有丰富的缓存经验背景要求,实际上,他只看到了丰厚的报酬 )。
说到做到
programmer one 离开之后,他想要知道这个面试者说的问题和答案,所以他上网去查,
programmer one 对缓存一无所知,除了:当我需要缓存的时候,我就会用 hash table。
在他使用了他最爱的搜索引擎搜索之后,他找到了一篇很不错的关于缓存文章,并且开始去阅读……
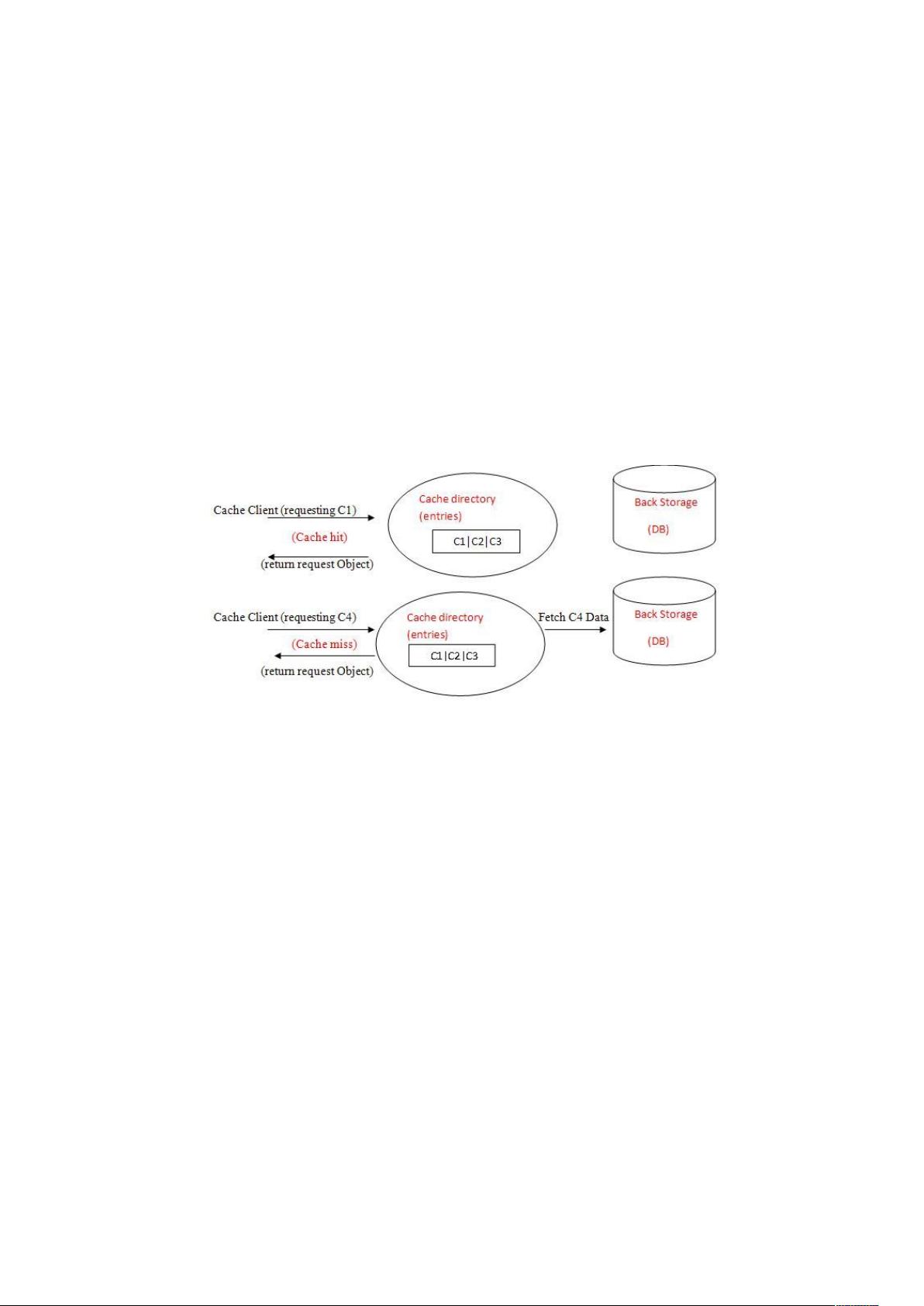
为什么我们需要缓存?
很久很久以前,在还没有缓存的时候……用户经常是去请求一个对象,而这个对象是从数据库去取,然
后,这个对象变得越来越大,这个用户每次的请求时间也越来越长了,这也把数据库弄得很痛苦,他无
时不刻不在工作。所以,这个事情就把用户和数据库弄得很生气,接着就有可能发生下面两件事情:

剩余13页未读,继续阅读
资源评论













