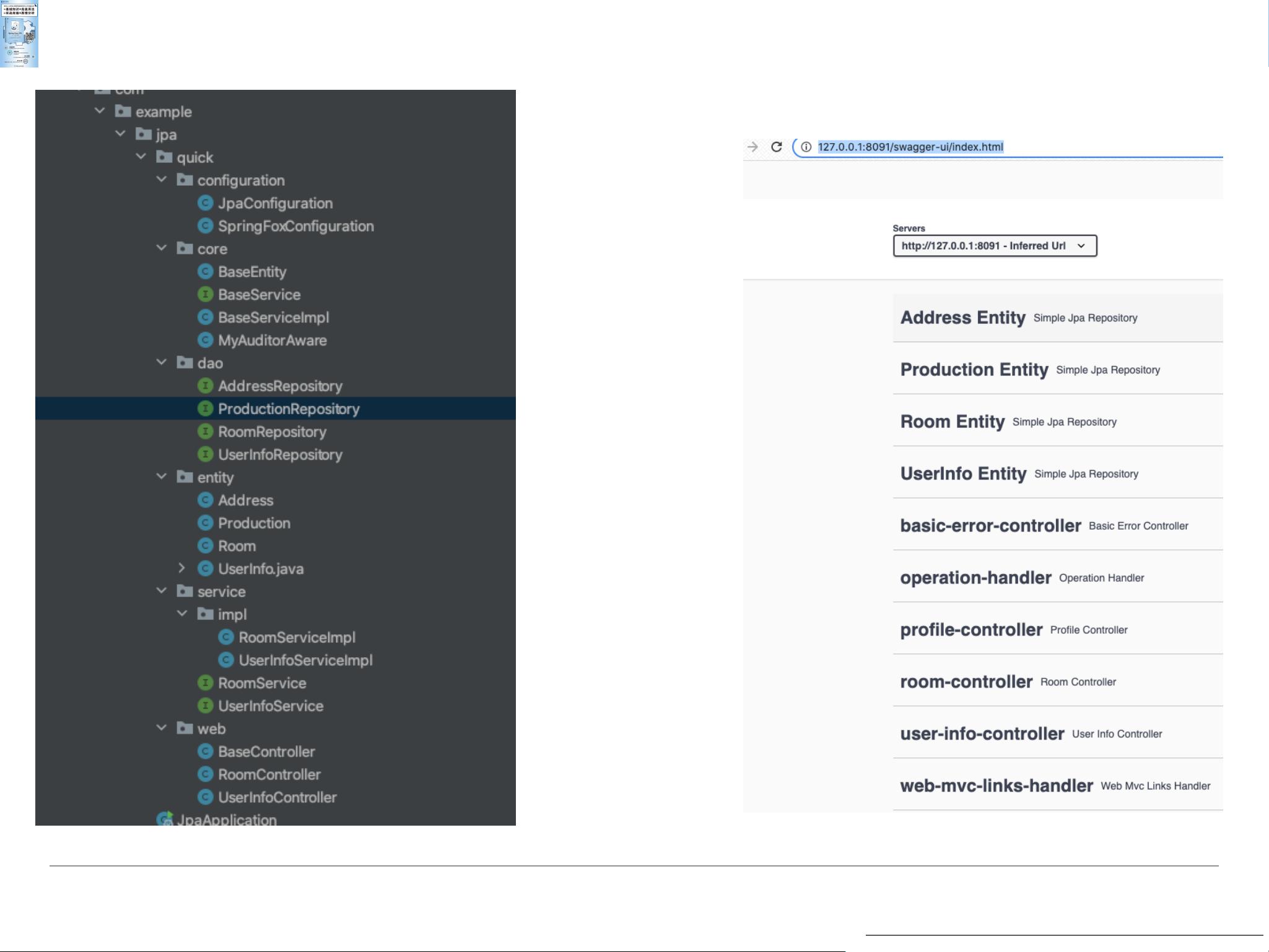
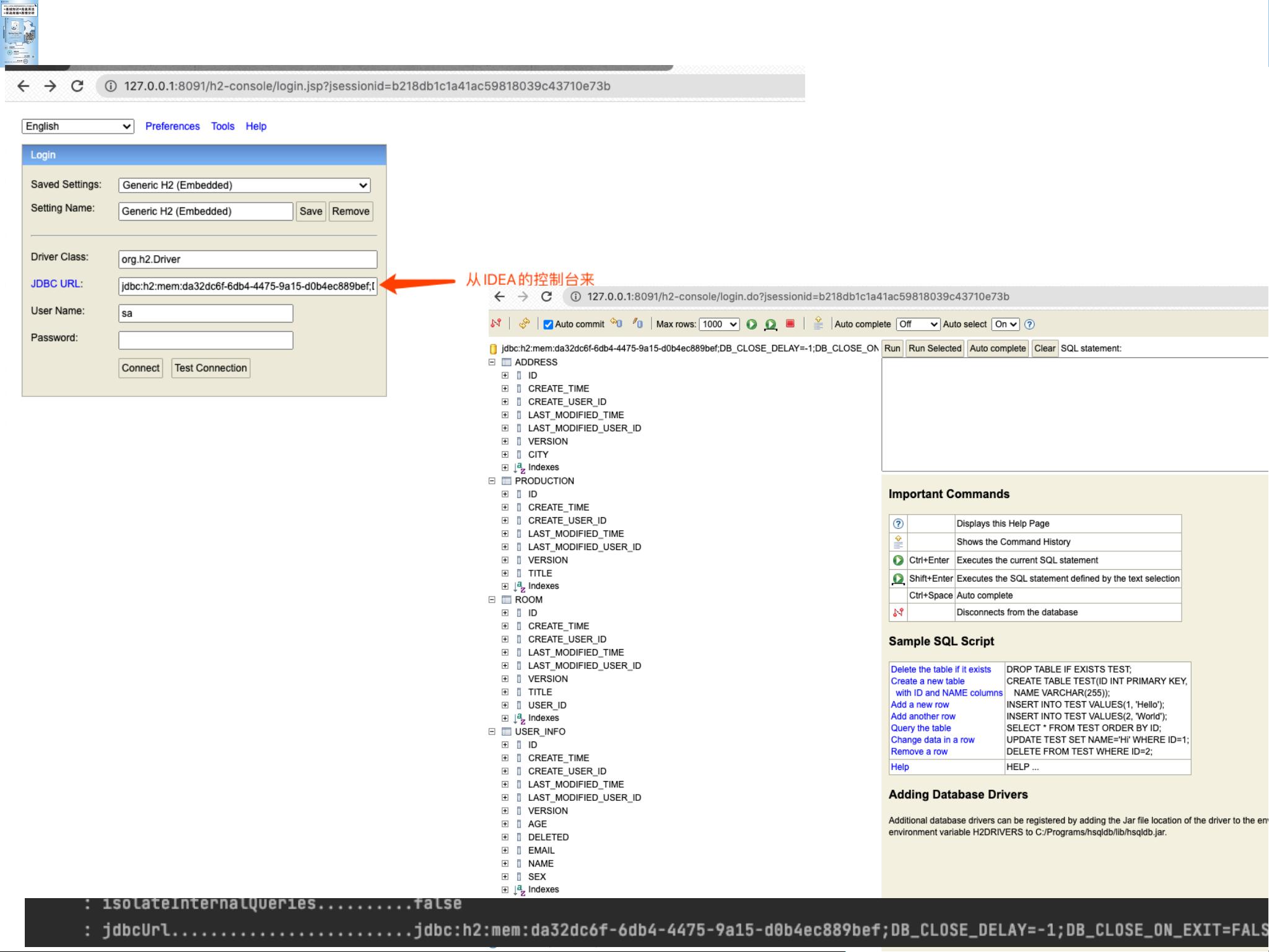
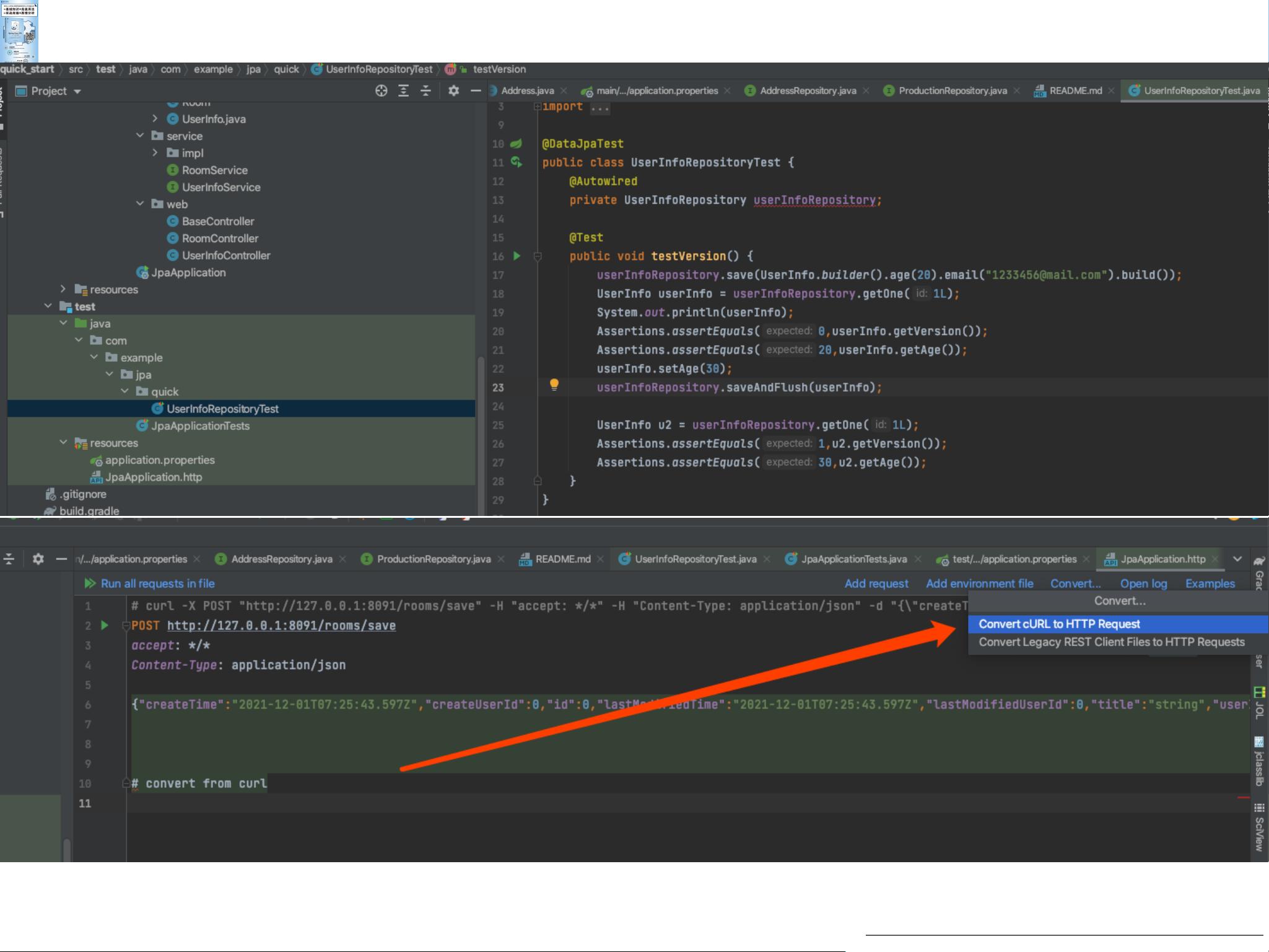
1. 开发效率极⾼: 2. 成熟的语法结构: 3. 与Spring全家桶结合紧密: 4. 成熟的框架和架构 常⻅的SQL性能问题,如何优雅处理? 2. 错综复杂的关联关系如何应对? 3. 万恶的LazyException本质是什么? 4. ⾼并发⾼性能要求的API服务要⽤JPA吗? Spring Data JPA是Spring生态中的一个强大ORM框架,它极大地提高了Java开发者在处理数据库操作时的效率。Spring Data JPA的主要优点在于其高度的开发效率、成熟的语法结构以及与Spring框架的紧密集成。 1. **开发效率极高**: - Spring Data JPA通过提供自动化的 Repository 实现,减少了大量手动编写SQL和DAO层代码的工作。开发者只需定义Repository接口,通过简单的查询方法名即可实现复杂的数据库查询。例如,`findByEmailAddressAndLastname`方法将自动构建出基于电子邮件地址和姓氏的联接查询。 2. **成熟的语法结构**: - Spring Data JPA支持DQL(Domain Query Language)风格的方法命名,使得查询语句的编写变得直观且易于理解。例如,`findByLastnameIgnoreCase` 方法会忽略大小写进行查询,`findByLastnameAndFirstnameAllIgnoreCase` 则同时对姓氏和名字忽略大小写进行等值匹配。 - 它还支持排序(`OrderBy`)、分页(`Pageable` 和 `Slice`)和限制结果(`First` 和 `Top`)等功能,使得数据操作更加灵活。 3. **与Spring全家桶结合紧密**: - Spring Data JPA可以无缝地与Spring Boot、Spring MVC、Spring Transaction管理等组件集成,为开发者提供了完整的解决方案,降低了系统的复杂性。 然而,尽管Spring Data JPA带来了诸多便利,但在实际使用中也会遇到一些挑战和难点: 1. **SQL性能问题**: - Spring Data JPA虽然简化了查询编写,但可能导致生成的SQL不够优化,尤其是在处理大数据量或复杂查询时。开发者需要熟悉JPA的内部工作原理,适时使用`@Query`注解自定义SQL,以提升性能。 2. **关联关系的处理**: - 在处理多对一、一对多、多对多等复杂关联关系时,可能会出现懒加载(LazyInitializationException)问题。为了避免这种情况,开发者需要合理设置fetch策略,比如选择eager loading或使用`@Transactional`注解确保在一个事务内完成关联数据的加载。 3. **高并发高性能要求**: - 对于需要高并发和高性能的API服务,单纯依赖JPA可能不是最佳选择,因为它在某些场景下可能不如直接使用JDBC或MyBatis等工具高效。在这种情况下,需要考虑缓存策略、数据库设计优化、分库分表等技术手段。 总结来说,Spring Data JPA作为一个强大的ORM工具,能够显著提高开发效率,简化数据库操作。然而,要充分发挥其优势并克服潜在问题,开发者需要深入理解JPA的工作机制,合理调整查询策略,以及适当地与其他优化技术相结合。在面对复杂业务需求和性能挑战时,灵活运用各种技术和策略是关键。
剩余29页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~
















- 1
- 2
前往页