
字典树(trie tree)
trie 的性质真的是相当的好,而且实现比较简单。它使在字符串集合中查找某个字符串的操
作的复杂度降到最大只需 O(n),其中 n 为字符串的长度。trie 是典型的将时间置换为空间的
算法,好在 ACM 中一般对空间的要求很宽松。
trie 的原理是利用字符串集合中字符串的公共前缀来降低时间开销以达到提高效率的目
的。
它具有以下性质:1,根结点不包含任何字符信息;2,如果字符的种数为 n,则每个结点的出度为
n(这样必然会导致浪费很多空间,这也是 trie 的缺点,我还没有想到好点的办法避免);3,查找,
插入复杂度为 O(n),n 为字符串长度。
举一个例子,给 50000 个由小写字母构成的长度不超过 10 的单词,然后问某个公共前缀是
否出现过。如果我们直接从字符串集中从头往后搜,看给定的字符串是否为字符串集中某
个字符串的前缀,那样复杂度为 O(50000^2),这样显然会 TLE。又或是我们对于字符串集
中的每个字符串,我们用 MAP 存下它所有的前缀。然后询问时可以直接给出结果。这样
复杂度为 O(50000*len),最坏情况下 len 为字符串最长字符串的长度。而且这没有算建立
MAP 存储的时间,也没有算用 MAP 查询的时间,实际效率会更低。但如果我们用 trie 的
话,当查询如字符串 abcd 是否为某字符串的前缀时,显然以 b,c,d....等不是以 a 开头的字符
串就不用查找了。实际查询复杂度只有 O(len),建立 trie 的复杂度为 O(50000).这是完全可
以接受的。
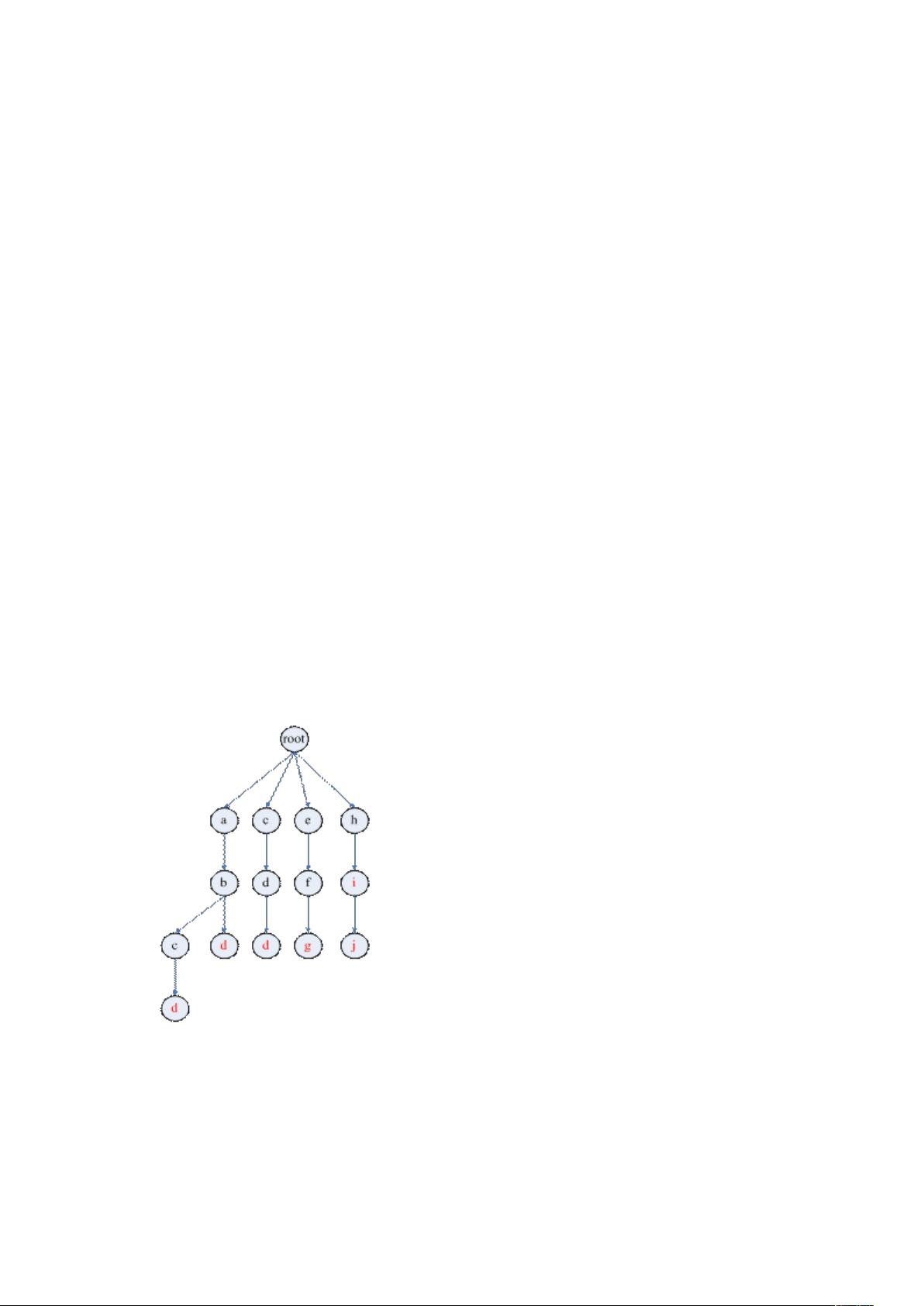
如给定字符串集合 abcd,abd,cdd,efg,hij,hi 六个字符串建立的 trie tree 如下图所示:
查找一个字符串时,我们只需从根结点按字符串中字符出现顺序依次往下走。如果到最后
字符串结束时,对应的结点标记为红色,则该字符串存在;否则不存在。
插入时也只需从根结点往下遍历,碰到已存在的字符结点就往下遍历,否则,建立新结
点;最后标记最后一个字符的结点为红色即可。






评论0
最新资源