

1
Self-supervised Visual Feature Learning with
Deep Neural Networks: A Survey
Longlong Jing and Yingli Tian
∗
, Fellow, IEEE
Abstract—Large-scale labeled data are generally required to train deep neural networks in order to obtain better performance in visual
feature learning from images or videos for computer vision applications. To avoid extensive cost of collecting and annotating
large-scale datasets, as a subset of unsupervised learning methods, self-supervised learning methods are proposed to learn general
image and video features from large-scale unlabeled data without using any human-annotated labels. This paper provides an extensive
review of deep learning-based self-supervised general visual feature learning methods from images or videos. First, the motivation,
general pipeline, and terminologies of this field are described. Then the common deep neural network architectures that used for
self-supervised learning are summarized. Next, the schema and evaluation metrics of self-supervised learning methods are reviewed
followed by the commonly used image and video datasets and the existing self-supervised visual feature learning methods. Finally,
quantitative performance comparisons of the reviewed methods on benchmark datasets are summarized and discussed for both image
and video feature learning. At last, this paper is concluded and lists a set of promising future directions for self-supervised visual
feature learning.
Index Terms—Self-supervised Learning, Unsupervised Learning, Convolutional Neural Network, Transfer Learning, Deep Learning.
F
1 INTRODUCTION
1.1 Motivation
D
UE to the powerful ability to learn different levels of
general visual features, deep neural networks have
been used as the basic structure to many computer vision
applications such as object detection [1], [2], [3], semantic
segmentation [4], [5], [6], image captioning [7], etc. The mod-
els trained from large-scale image datasets like ImageNet
are widely used as the pre-trained models and fine-tuned
for other tasks for two main reasons: (1) the parameters
learned from large-scale diverse datasets provide a good
starting point, therefore, networks training on other tasks
can converge faster, (2) the network trained on large-scale
datasets already learned the hierarchy features which can
help to reduce over-fitting problem during the training of
other tasks, especially when datasets of other tasks are small
or training labels are scarce.
The performance of deep convolutional neural networks
(ConvNets) greatly depends on their capability and the
amount of training data. Different kinds of network ar-
chitectures were developed to increase the capacity of net-
work models, and larger and larger datasets were collected
these days. Various networks including AlexNet [8], VGG
[9], GoogLeNet [10], ResNet [11], and DenseNet [12] and
• L. Jing is with the Department of Computer Science, The Graduate
Center, The City University of New York, NY, 10016. E-mail:
ljing@gradcenter.cuny.edu
• Y. Tian is with the Department of Electrical Engineering, The City
College, and the Department of Computer Science, the Graduate
Center, the City University of New York, NY, 10031. E-mail:
ytian@ccny.cuny.edu
∗
Corresponding author
This material is based upon work supported by the National Science Founda-
tion under award number IIS-1400802.
large scale datasets such as ImageNet [13], OpenImage [14]
have been proposed to train very deep ConvNets. With
the sophisticated architectures and large-scale datasets, the
performance of ConvNets keeps breaking the state-of-the-
arts for many computer vision tasks [1], [4], [7], [15], [16].
However, collection and annotation of large-scale
datasets are time-consuming and expensive. As one of the
most widely used datasets for pre-training very deep 2D
convolutional neural networks (2DConvNets), ImageNet
[13] contains about 1.3 million labeled images covering
1, 000 classes while each image is labeled by human workers
with one class label. Compared to image datasets, collection
and annotation of video datasets are more expensive due
to the temporal dimension. The Kinetics dataset [17], which
is mainly used to train ConvNets for video human action
recognition, consists of 500, 000 videos belonging to 600
categories and each video lasts around 10 seconds. It took
many Amazon Turk workers a lot of time to collect and
annotate a dataset at such a large scale.
To avoid time-consuming and expensive data anno-
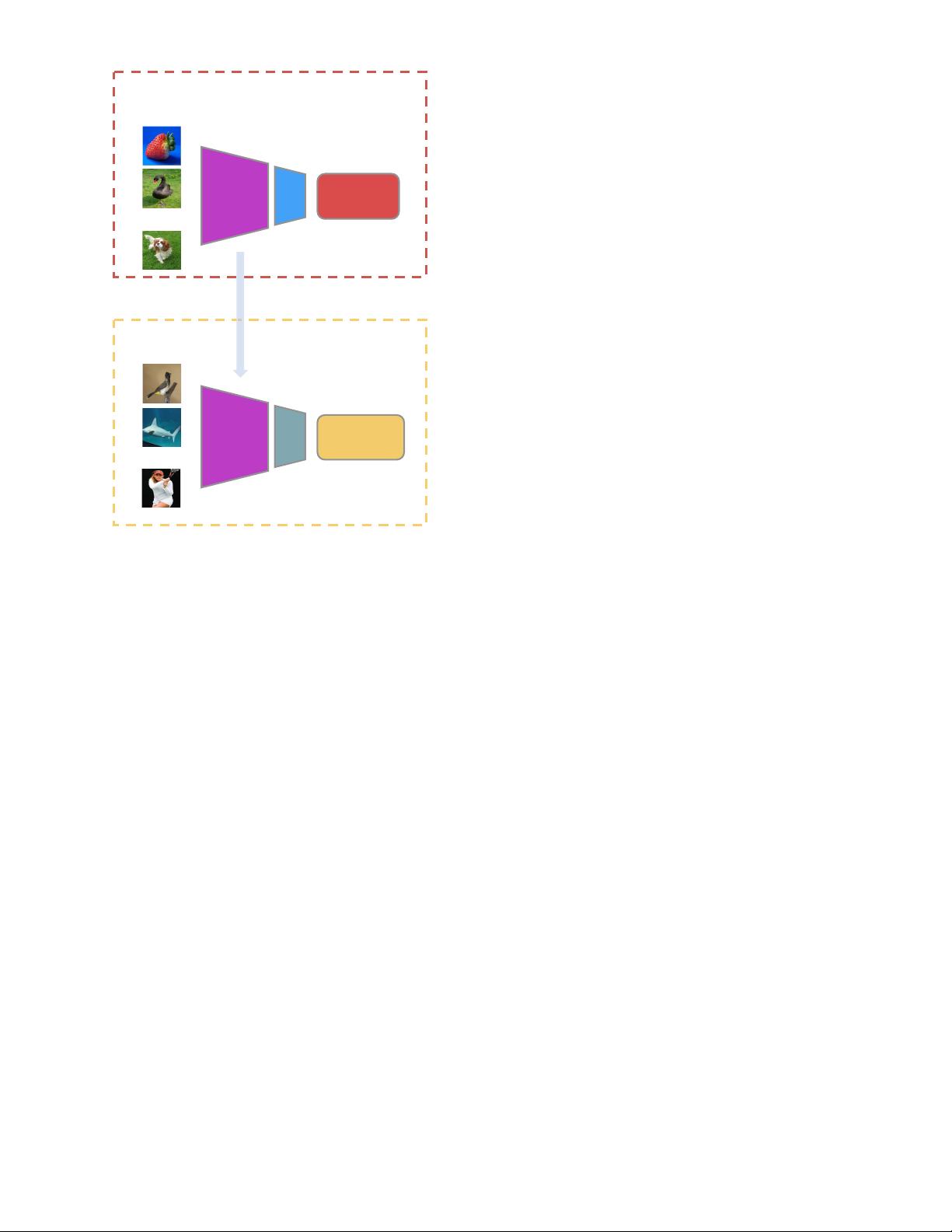
tations, many self-supervised methods were proposed to
learn visual features from large-scale unlabeled images or
videos without using any human annotations. To learn
visual features from unlabeled data, a popular solution is to
propose various pretext tasks for networks to solve, while
the networks can be trained by learning objective functions
of the pretext tasks and the features are learned through this
process. Various pretext tasks have been proposed for self-
supervised learning including colorizing grayscale images
[18], image inpainting [19], image jigsaw puzzle [20], etc.
The pretext tasks share two common properties: (1) visual
features of images or videos need to be captured by Con-
vNets to solve the pretext tasks, (2) pseudo labels for the
pretext task can be automatically generated based on the
attributes of images or videos.
arXiv:1902.06162v1 [cs.CV] 16 Feb 2019

剩余23页未读,继续阅读
资源评论


syp_net
- 粉丝: 158
- 资源: 1187









最新资源
- 利用网页设计语言制作的一款简易打地鼠小游戏
- PromptSource: 自然语言提示的集成开发环境与公共资源库
- PCAN UDS VI,用于UDS诊断
- BD网盘不限速补丁+最新进程修改脚本亲测有效
- 利用网页设计语言制作的一款简易的时钟网页,可供初学者借鉴,学习 语言:html+css+script
- 学习threejs,通过设置纹理属性来修改纹理贴图的位置和大小,贴图
- _root_license_license_8e0ac649-0626-408f-881c-6603da48ce72.lrf
- 基于 SpringBoot 的 JavaWeb 宠物猫认养系统:功能设计与领养体验优化
- CAN Get Value String
- CAN Get Value Integer
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


