最新《生成式对抗网络异常检测》综述论文
需积分: 0 169 浏览量
2021-09-16
17:28:52
上传
评论 2
收藏 1.17MB PDF 举报


A Survey on GANs for Anomaly Detection
Federico Di Mattia
1 *
Paolo Galeone
1 *
Michele De Simoni
1 *
Emanuele Ghelfi
1 *
Abstract
Anomaly detection is a significant problem faced
in several research areas. Detecting and correctly
classifying something unseen as anomalous is
a challenging problem that has been tackled in
many different manners over the years. Gener-
ative Adversarial Networks (GANs) and the ad-
versarial training process have been recently em-
ployed to face this task yielding remarkable re-
sults. In this paper we survey the principal GAN-
based anomaly detection methods, highlighting
their pros and cons. Our contributions are the
empirical validation of the main GAN models
for anomaly detection, the increase of the experi-
mental results on different datasets and the public
release of a complete Open Source toolbox for
Anomaly Detection using GANs.
1. Introduction
Anomalies are patterns in data that do not conform to a
well-defined notion of normal behavior (Chandola et al.,
2009). Generative Adversarial Networks (GANs) and the
adversarial training framework (Goodfellow et al., 2014)
have been successfully applied to model complex and high
dimensional distribution of real-world data. This GAN char-
acteristic suggests they can be used successfully for anomaly
detection, although their application has been only recently
explored. Anomaly detection using GANs is the task of
modeling the normal behavior using the adversarial training
process and detecting the anomalies measuring an anomaly
score (Schlegl et al., 2017). To the best of our knowledge,
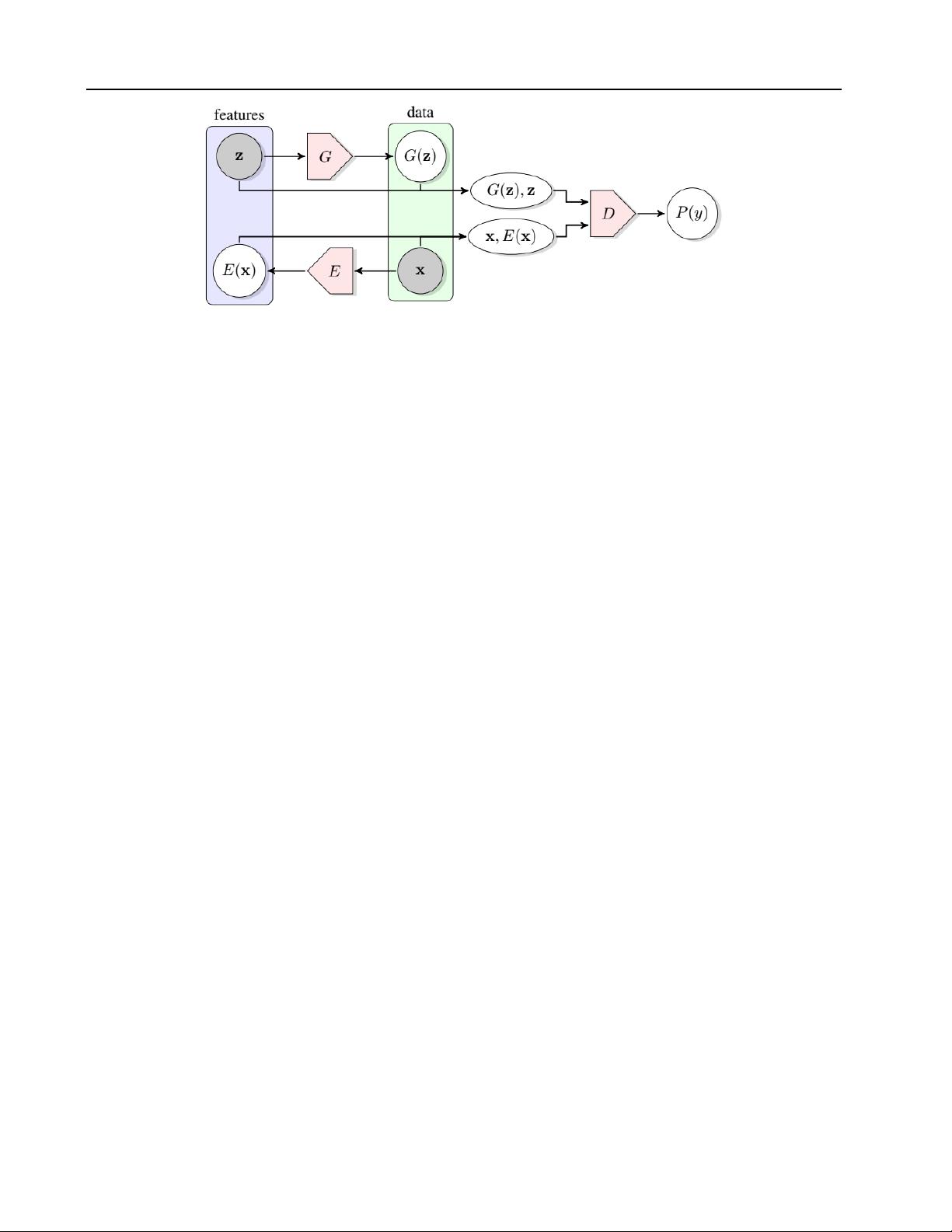
all the GAN-based approaches to anomaly detection build
upon on the Adversarial Feature Learning idea (Donahue
et al., 2016) in which the BiGAN architecture has been
proposed. In their original formulation, the GAN frame-
work learns a generator that maps samples from an arbitrary
latent distribution (noise prior) to data as well as a discrimi-
nator which tries to distinguish between real and generated
samples. The BiGAN architecture extended the original for-
*
Equal contribution
1
Zuru Tech, Modena, Italy. Correspon-
dence to: Federico Di Mattia <federico.d@zuru.tech>.
mulation, adding the learning of the inverse mapping which
maps the data back to the latent representation. A learned
function that maps input data to its latent representation to-
gether with a function that does the opposite (the generator)
is the basis of the anomaly detection using GANs.
The paper is organized as follows. In Section 1 we introduce
the GANs framework and, briefly, its most innovative exten-
sions, namely conditional GANs and BiGAN, respectively
in Section 1.2 and Section 1.3. Section 2 contains the state
of the art architectures for anomaly detection with GANs.
In Section 3 we empirically evaluate all the analyzed archi-
tectures. Finally, Section 4 contains the conclusions and
future research directions.
1.1. GANs
GANs are a framework for the estimation of generative
models via an adversarial process in which two models, a
discriminator
D
and a generator
G
, are trained simultane-
ously. The generator
G
aim is to capture the data distribu-
tion, while the discriminator
D
estimates the probability that
a sample came from the training data rather than
G
. To learn
a generative distribution
p
g
over the data
x
the generator
builds a mapping from a prior noise distribution
p
z
to a data
space as
G(z; θ
G
)
, where
θ
G
are the generator parameters.
The discriminator outputs a single scalar representing the
probability that
x
came from real data rather than from
p
g
.
The generator function is denoted with
D(x; θ
D
)
, where
θ
D
are discriminator parameters.
The original GAN framework (Goodfellow et al., 2014)
poses this problem as a min-max game in which the two
players (
G
and
D
) compete against each other, playing the
following zero-sum min-max game:
min
G
max
D
V (D, G) = E
x∼p
data
(x)
[log D(x)]+
E
z∼p
z
(z)
[log (1 − D(G(z)))] .
(1)
1.2. Conditional GANs
GANs can be extended to a conditional model (Mirza &
Osindero, 2014) conditioning either
G
or
D
on some ex-
tra information
y
. The
y
condition could be any auxiliary
information, such as class labels or data from other modal-
ities. We can perform the conditioning by feeding
y
into
arXiv:1906.11632v2 [cs.LG] 14 Sep 2021

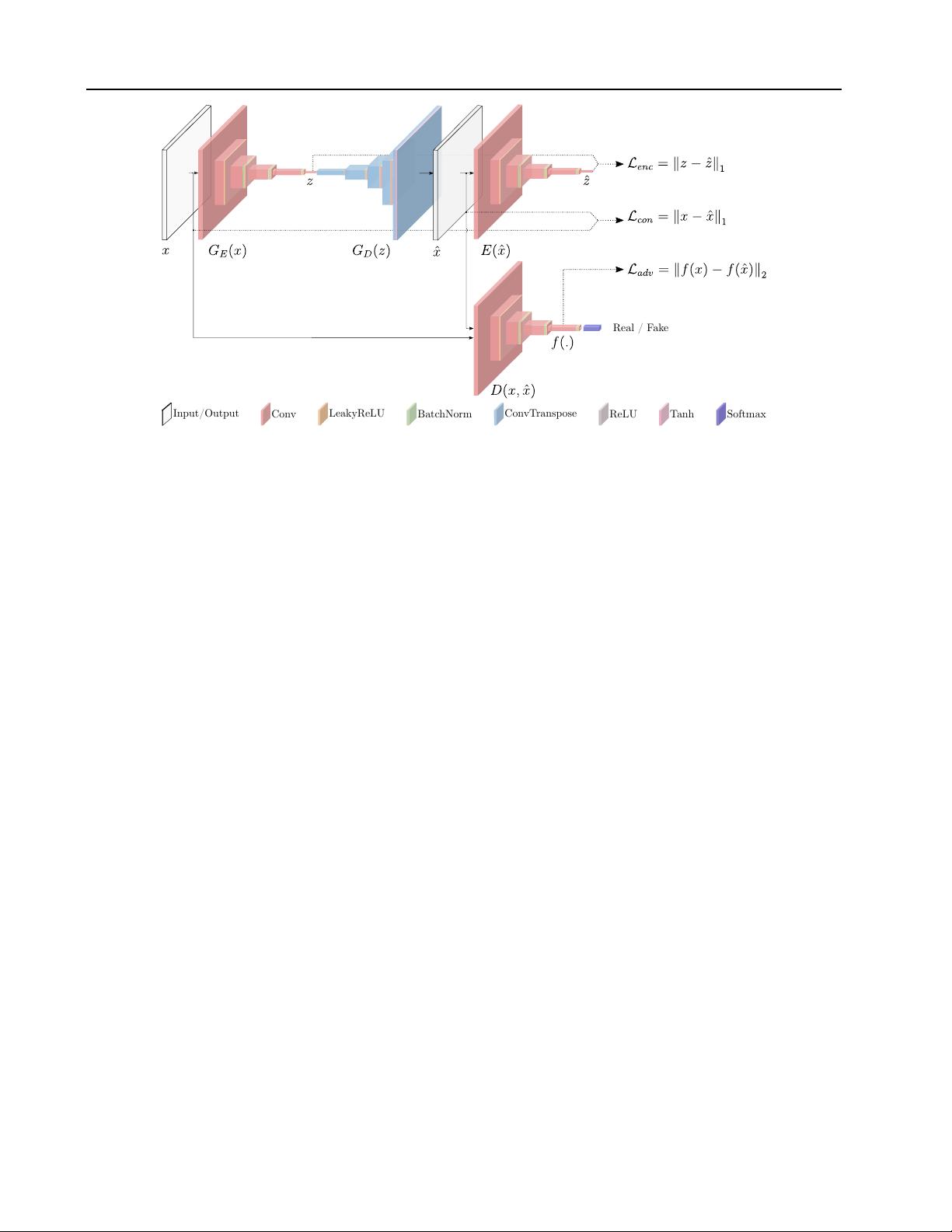
剩余15页未读,继续阅读
资源评论


syp_net
- 粉丝: 158
- 资源: 1196









最新资源
- 2%EF%BC%9A%E9%99%95%E8%A5%BF%E
- yyspdz62_944.apk
- SAP公司间采购EDI配置-如何触发自动MIRO.docx
- python197基于图像识别的仪表实时监控系统.rar
- I2C驱动SHT30温湿度传感器和LCD12864使用例程(RSCG12864B)
- python193中学地理-中国的江河湖泊教学网(django).rar
- python191基于时间序列分析的大气污染预测软件(django).rar
- python190基于人脸识别智能化小区门禁管理系统.rar
- python189某医院体检挂号系统.rar
- python179的企业物流管理系统(django).rar
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


