Recurrent DETR: Transformer-Based Object Detection for Crowded S
148 浏览量
2023-11-25
15:45:34
上传
评论
收藏 5.88MB PDF 举报


Received 17 June 2023, accepted 5 July 2023, date of publication 10 July 2023, date of current version 2 August 2023.
Digital Object Identifier 10.1109/ACCESS.2023.3293532
Recurrent DETR: Transformer-Based Object
Detection for Crowded Scenes
HYEONG KYU CHOI
1
, CHONG KEUN PAIK
2
, HYUN WOO KO
1,3
, MIN-CHUL PARK
1,3
,
AND HYUNWOO J. KIM
1
1
Department of Computer Science and Engineering, Korea University, Seoul 02841, Republic of Korea
2
Samsung Electro-Mechanics, Suwon 16674, Republic of Korea
3
Center for Opto-Electronic Materials and Device, Korea Institute of Science and Technology, Seoul 02792, Republic of Korea
Corresponding author: Hyunwoo J. Kim (hyunwoojkim@korea.ac.kr)
This work was supported in part by the Korea Institute of Planning and Evaluation for Technology in Food, Agriculture and Forestry (IPET)
and the Korea Smart Farm Research and Development Foundation (KosFarm) through the Smart Farm Innovation Technology
Development Program by the Ministry of Agriculture, Food and Rural Affairs (MAFRA), and Ministry of Science and ICT (MSIT),
Rural Development Administration (RDA), under Grant 421025-04; in part by the Grant of the Korea Health Technology Research and
Development Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health and Welfare,
Republic of Korea, under Grant HR20C0021; and in part by the Neubla.
ABSTRACT Recent Transformer-based object detectors have achieved remarkable performance on
benchmark datasets, but few have addressed the real-world challenge of object detection in crowded scenes
using transformers. This limitation stems from the fixed query set size of the transformer decoder, which
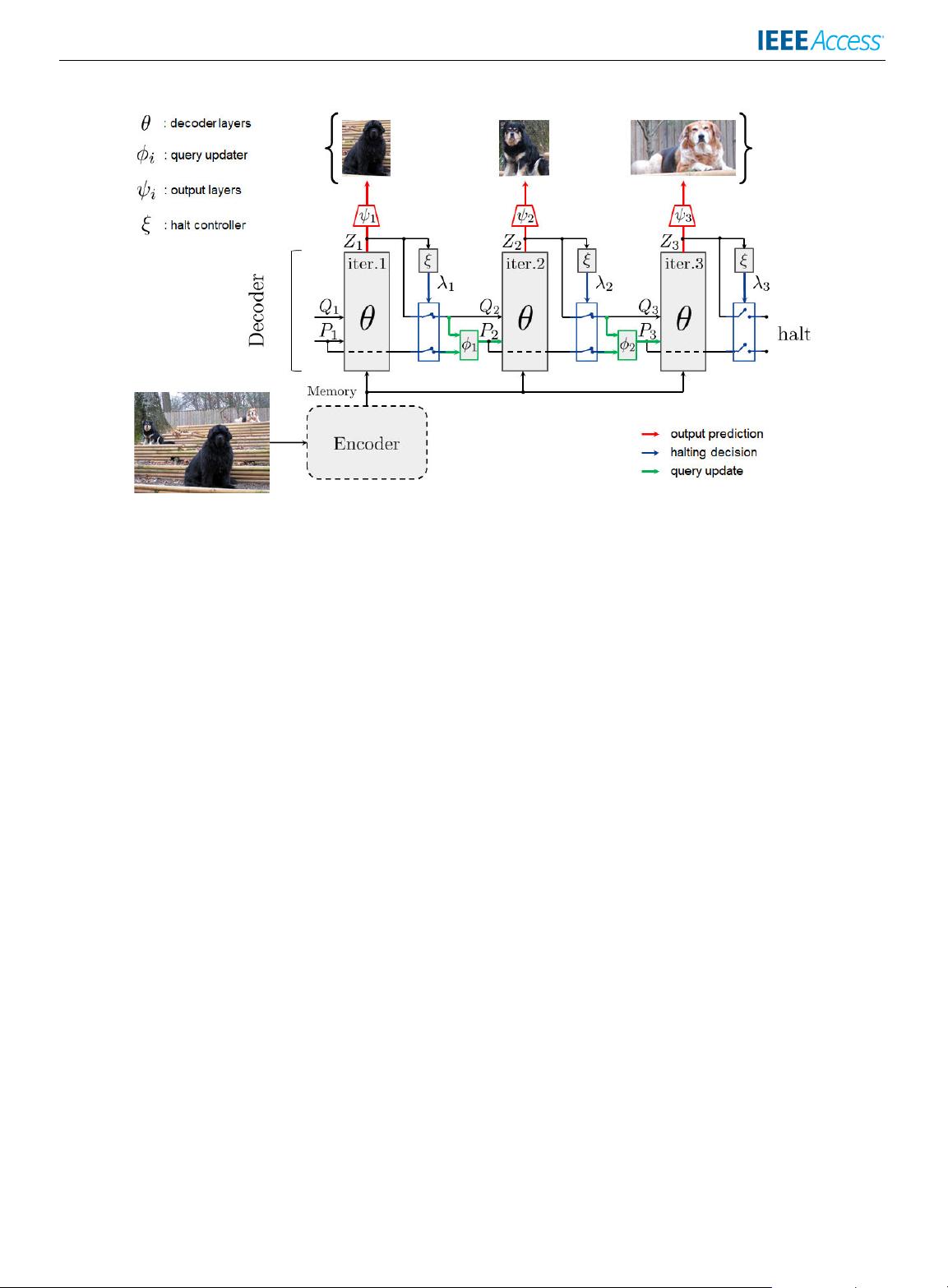
restricts the model’s inference capacity. To overcome this challenge, we propose Recurrent Detection
Transformer (Recurrent DETR), an object detector that iterates the decoder block to render more predictions
with a finite number of query tokens. Recurrent DETR can adaptively control the number of decoder
block iterations based on the image’s crowdedness or complexity, resulting in a variable-size prediction
set. This is enabled by our novel Pondering Hungarian Loss, which helps the model to learn when additional
computation is required to identify all the objects in a crowded scene. We demonstrate the effectiveness
of Recurrent DETR on two datasets: COCO 2017, which represents a standard setting, and CrowdHuman,
which features a crowded setting. Our experiments on both datasets show that Recurrent DETR achieves
significant performance gains of 0.8 AP and 0.4 AP, respectively, over its base architectures. Moreover,
we conduct comprehensive analyses under different query set size constraints to provide a thorough
evaluation of our proposed method.
INDEX TERMS Computer vision, object detection, detection transformers, dynamic computation.
I. INTRODUCTION
Object detection is a fundamental task in computer vision that
involves both recognizing and localizing objects within an
image. Several CNN-based methods have introduced models
to first locate probable objects and then categorize their
types [1], [2], [3], whereas others have tried to locate and
classify objects simultaneously in a single stage [4], [5], [6].
While convolutional neural networks (CNNs) have achieved
outstanding performance on this task, recent works have
explored the use of Transformer [7] architectures to further
The associate editor coordinating the review of this manuscript and
approving it for publication was Varuna De Silva
.
improve model performance. The self-attention mechanism
in Transformers allows for a wider receptive field per layer,
while the architecture’s high capacity yields outstanding
performance.
One of the main challenges with transformer-based object
detectors is their high computational overhead. The burden
stems from the large number of spurious tokens input into the
decoder blocks, which do not necessarily query foreground
objects. Several works have attempted to address this issue
by pruning tokens to improve computational efficiency [8],
[9]. However, few have addressed the real-world challenge of
object detection in crowded scenes, where there are too many
objects to identify with a fixed number of query tokens and
VOLUME 11, 2023
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 License.
For more information, see https://creativecommons.org/licenses/by-nc-nd/4.0/
78623
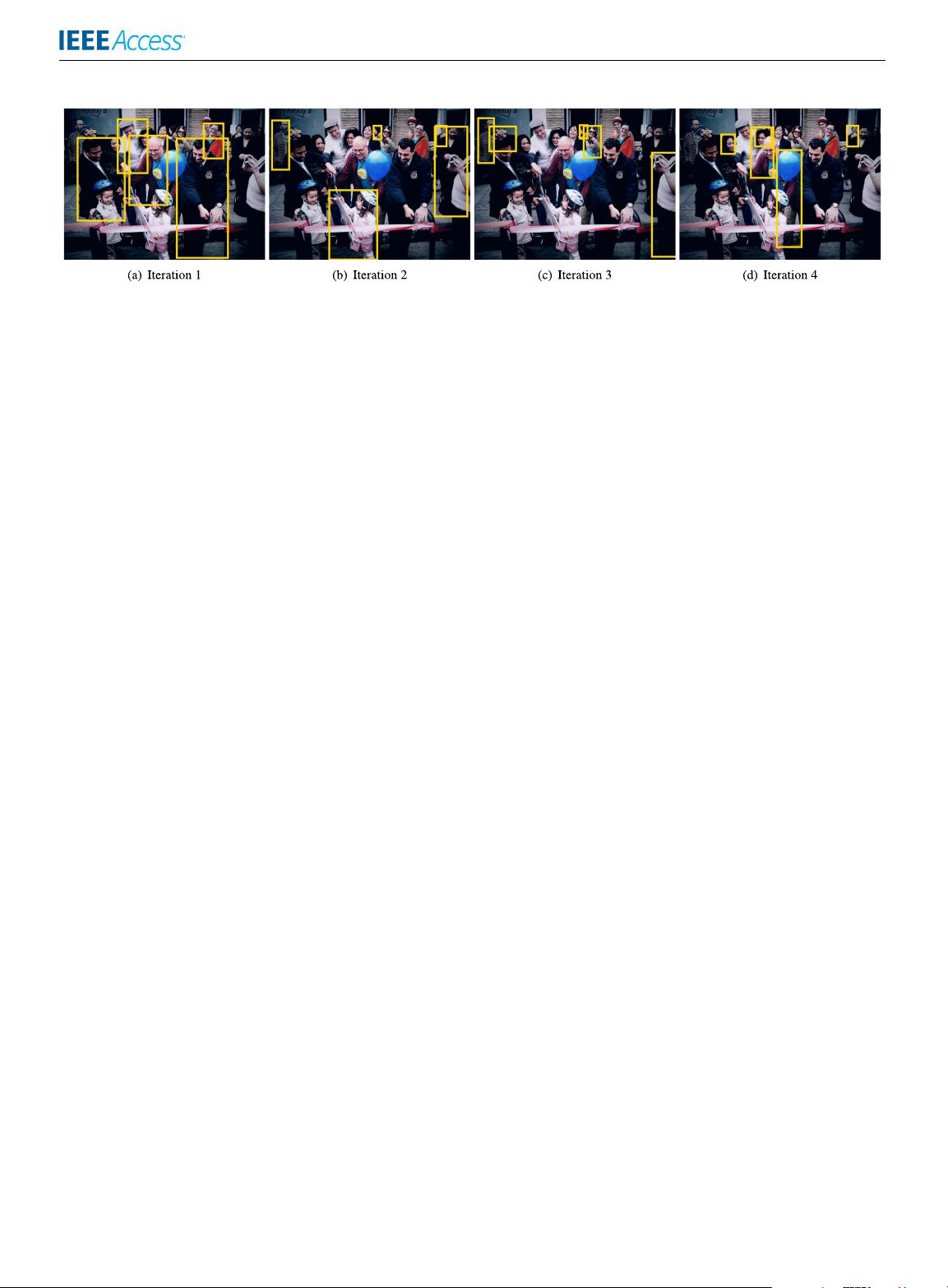


剩余20页未读,继续阅读
资源评论


DrYJ
- 粉丝: 40
- 资源: 24









最新资源
- 基于matlab实现配电网三相潮流计算方法,对几种常用的配电网潮流计算方法进行了对比分析.rar
- 基于matlab实现配电网潮流 经典33节点 前推回代法潮流计算 回代电流 前推电压 带注释.rar
- 基于matlab实现模拟退火遗传算法的车辆调度问题研究,用MATLAB语言加以实现.rar
- 基于matlab实现蒙特卡洛的的移动传感器节点定位算法仿真代码.rar
- 华中数控系统818用户说明书
- 基于matlab实现卡尔曼滤波器完成多传感器数据融合 对多个机器人的不同传感器数据进行融合估计足球精确位置.rar
- 基于matlab实现进行简单车辆识别-车辆检测.rar
- 基于JSP物流信息网的设计与实现
- 基于matlab实现车牌识别程序,和论文,自己做的,做毕业设计的可以看看 .rar
- Windows系统下安装与配置Neo4j的步骤
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


