

Fully-Convolutional Siamese Networks
for Object Tracking
Luca Bertinetto
?
Jack Valmadre
?
Jo˜ao F. Henriques
Andrea Vedaldi Philip H. S. Torr
Department of Engineering Science, University of Oxford
{name.surname}@eng.ox.ac.uk
Abstract. The problem of arbitrary object tracking has traditionally
been tackled by learning a model of the object’s appearance exclusively
online, using as sole training data the video itself. Despite the success of
these methods, their online-only approach inherently limits the richness
of the model they can learn. Recently, several attempts have been made
to exploit the expressive power of deep convolutional networks. How-
ever, when the object to track is not known beforehand, it is necessary
to perform Stochastic Gradient Descent online to adapt the weights of
the network, severely compromising the speed of the system. In this pa-
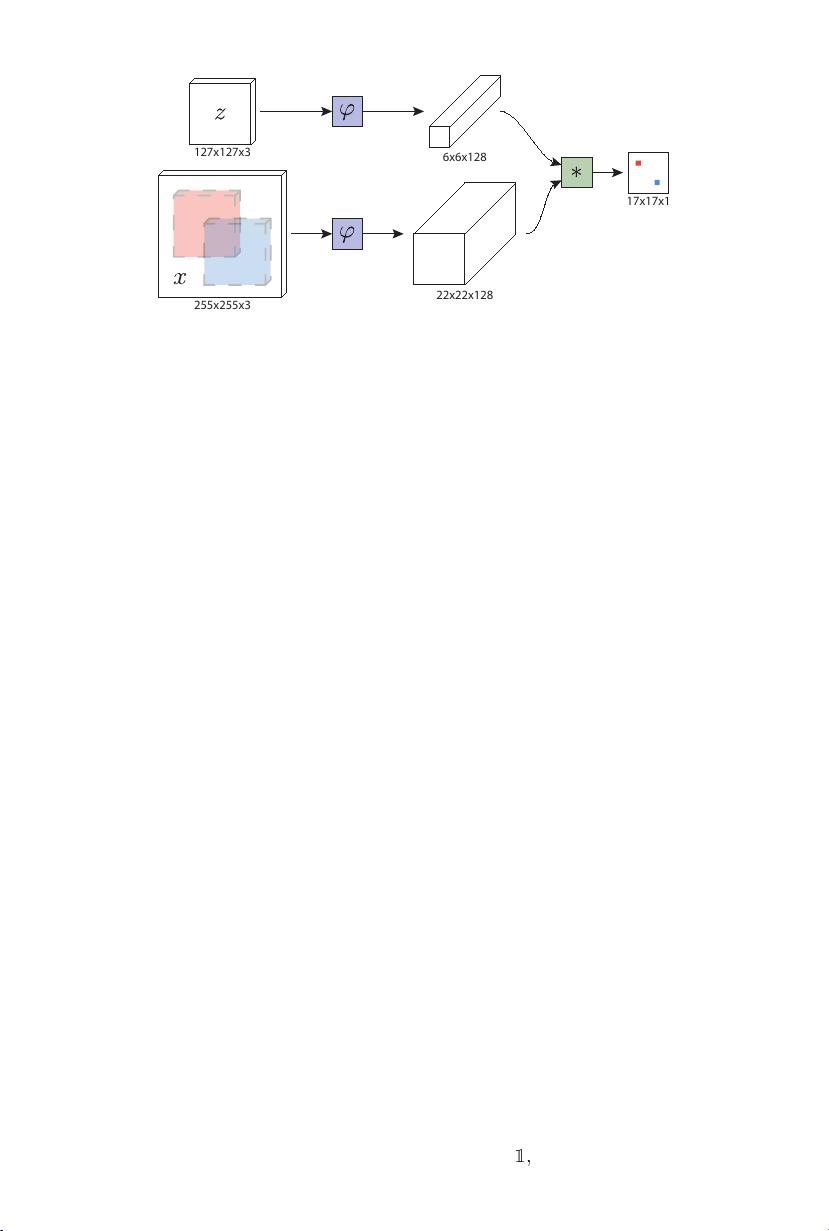
per we equip a basic tracking algorithm with a novel fully-convolutional
Siamese network trained end-to-end on the ILSVRC15 dataset for object
detection in video. Our tracker operates at frame-rates beyond real-time
and, despite its extreme simplicity, achieves state-of-the-art performance
in multiple benchmarks.
Keywords: object-tracking, Siamese-network, similarity-learning, deep-
learning
1 Introduction
We consider the problem of tracking an arbitrary object in video, where the
object is identified solely by a rectangle in the first frame. Since the algorithm
may be requested to track any arbitrary object, it is impossible to have already
gathered data and trained a specific detector.
For several years, the most successful paradigm for this scenario has been to
learn a model of the object’s appearance in an online fashion using examples ex-
tracted from the video itself [1]. This owes in large part to the demonstrated abil-
ity of methods like TLD [2], Struck [3] and KCF [4]. However, a clear deficiency of
using data derived exclusively from the current video is that only comparatively
simple models can be learnt. While other problems in computer vision have seen
an increasingly pervasive adoption of deep convolutional networks (conv-nets)
trained from large supervised datasets, the scarcity of supervised data and the
constraint of real-time operation prevent the naive application of deep learning
within this paradigm of learning a detector per video.
?
The first two authors contributed equally, and are listed in alphabetical order.
arXiv:1606.09549v3 [cs.CV] 1 Dec 2021

剩余15页未读,继续阅读
资源评论













