

1.概述
Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理
大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka 适合离线和在
线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构
建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用
于实时流式数据分析。
1.1 优点
可靠性 - Kafka 是分布式,分区,复制和容错的。
可扩展性 - Kafka 消息传递系统轻松缩放,无需停机。
耐用性 - Kafka 使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,
因此它是持久的。
性能 - Kafka 对于发布和订阅消息都具有高吞吐量。 即使存储了许多 TB 的消息,
它也保持稳定的性能。
Kafka 非常快,执行 2 百万写/秒,并保证零停机和零数据丢失。
2.基础
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能
力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计
中起到解耦、削峰、异步处理的作用。
2.1 关键术语
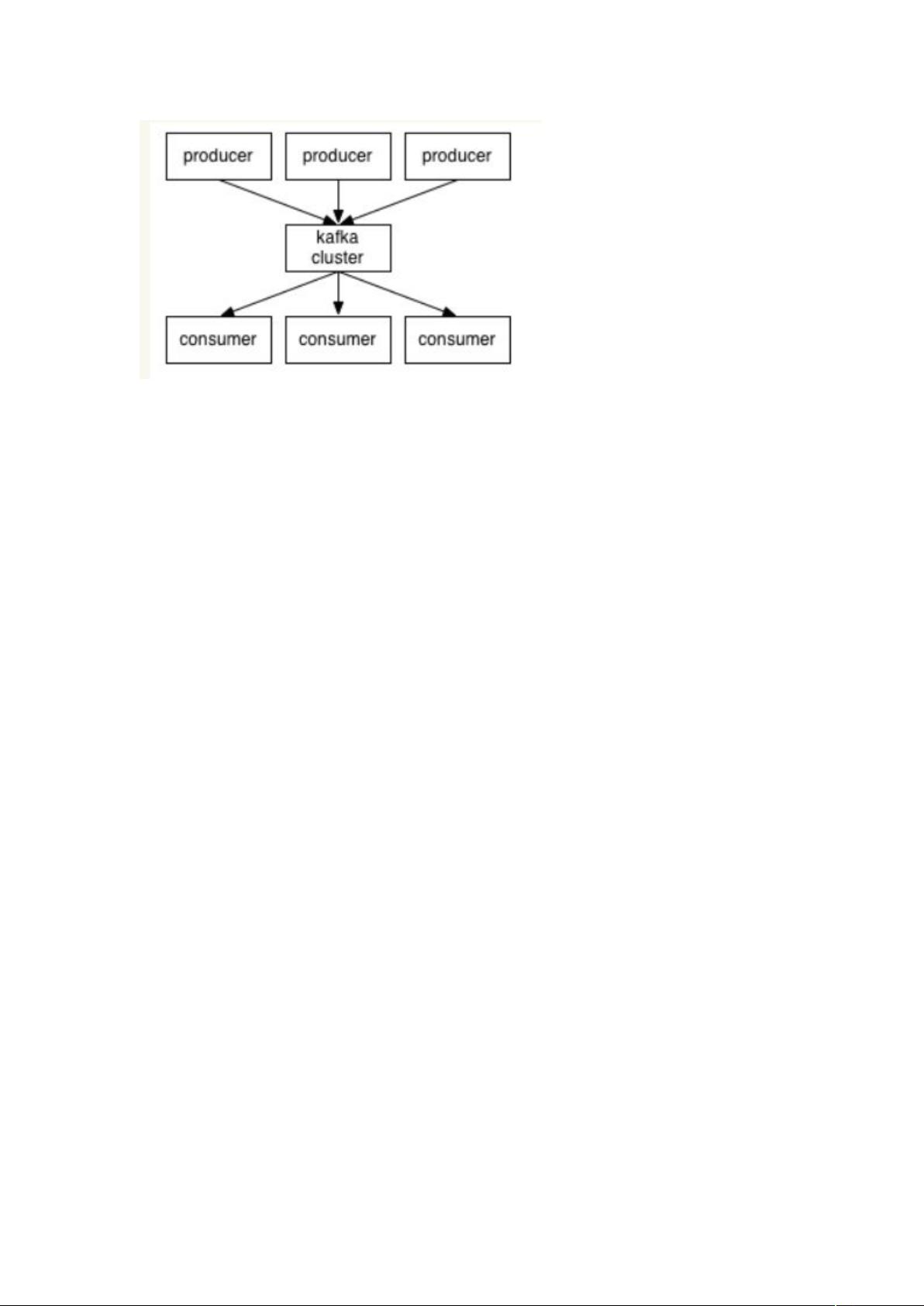
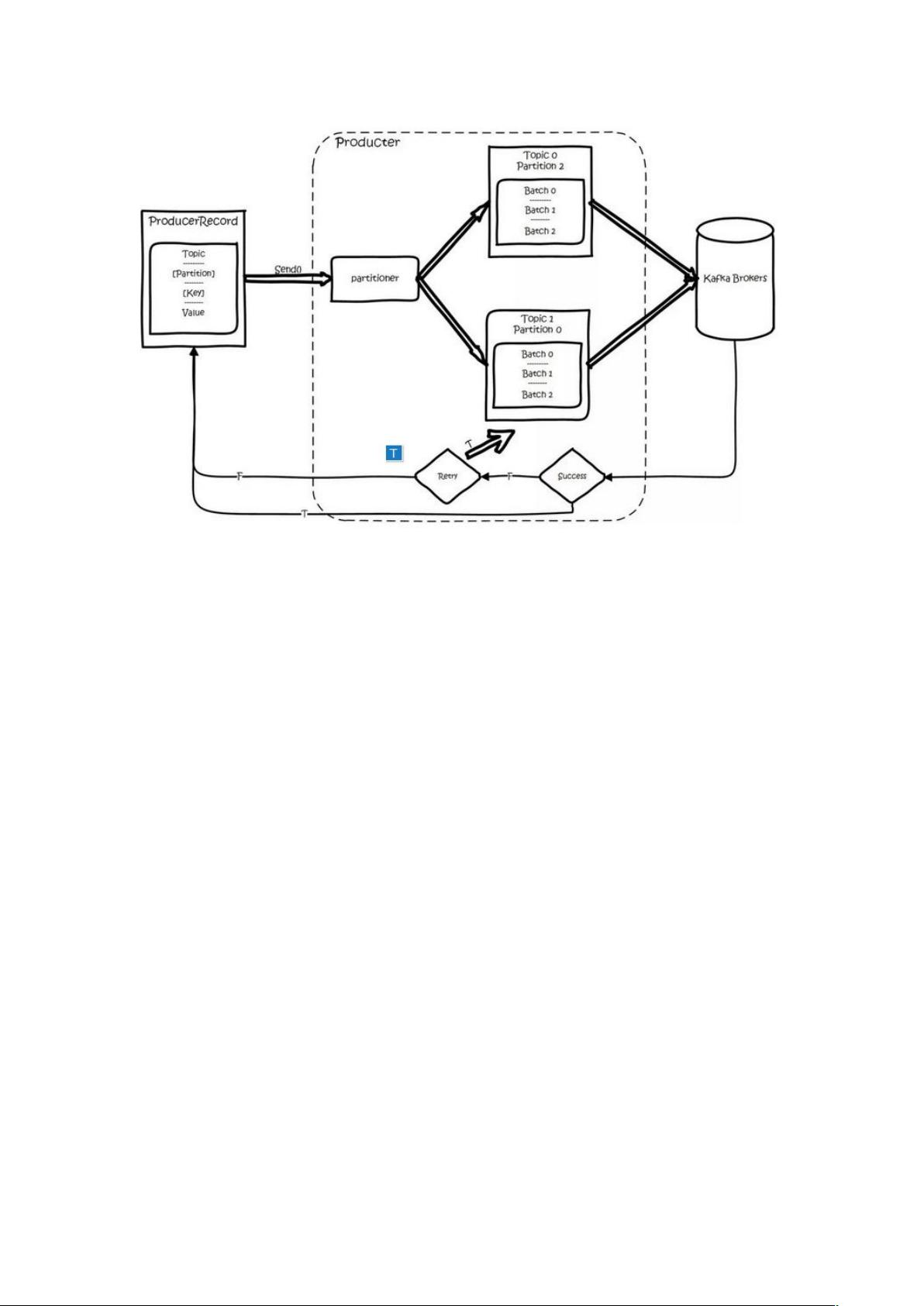
生产者和消费者(producer 和 consumer):消息的发送者叫 Producer,消息
的使用者和接受者是 Consumer,生产者将数据保存到 Kafka 集群中,消费者从
中获取消息进行业务的处理。


剩余20页未读,继续阅读

若水如斯
- 粉丝: 3
- 资源: 7









最新资源
- 基于java+ssm+mysql的大学生社团管理系统任务书.docx
- 客户流失预测/产品推荐算法介绍
- 基于java+ssm+mysql的蛋糕甜品店管理系统开题报告.doc
- 应急响应实战笔记:入侵分析、日志分析、权限维持、windows实战篇、LInux实战篇、WEB实战篇
- 基于java+ssm+mysql的点餐系统开题报告.docx
- 工作汇报ppt模板(黑色主题)
- 基于java+ssm+mysql的点餐系统任务书.docx
- python-7.纪念品分组-我的啦.py
- 基于java+ssm+mysql的公交车信息管理系统开题报告.doc
- python-8.统计数字-但是很大.py
- 基于java+ssm+mysql的公交车信息管理系统任务书.docx
- python-9.字符串的展开-领域!展开!.py
- browser-protocol
- 良人啊_Signed.apk
- 数智化时代医院临床试验人才培养的创新路径与实践探索.pdf
- KUKA OMNIMOVE重载型移动式运输平台工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0