© 2009 Cloudera, Inc.
Hadoop as Enterprise Data
Warehouse
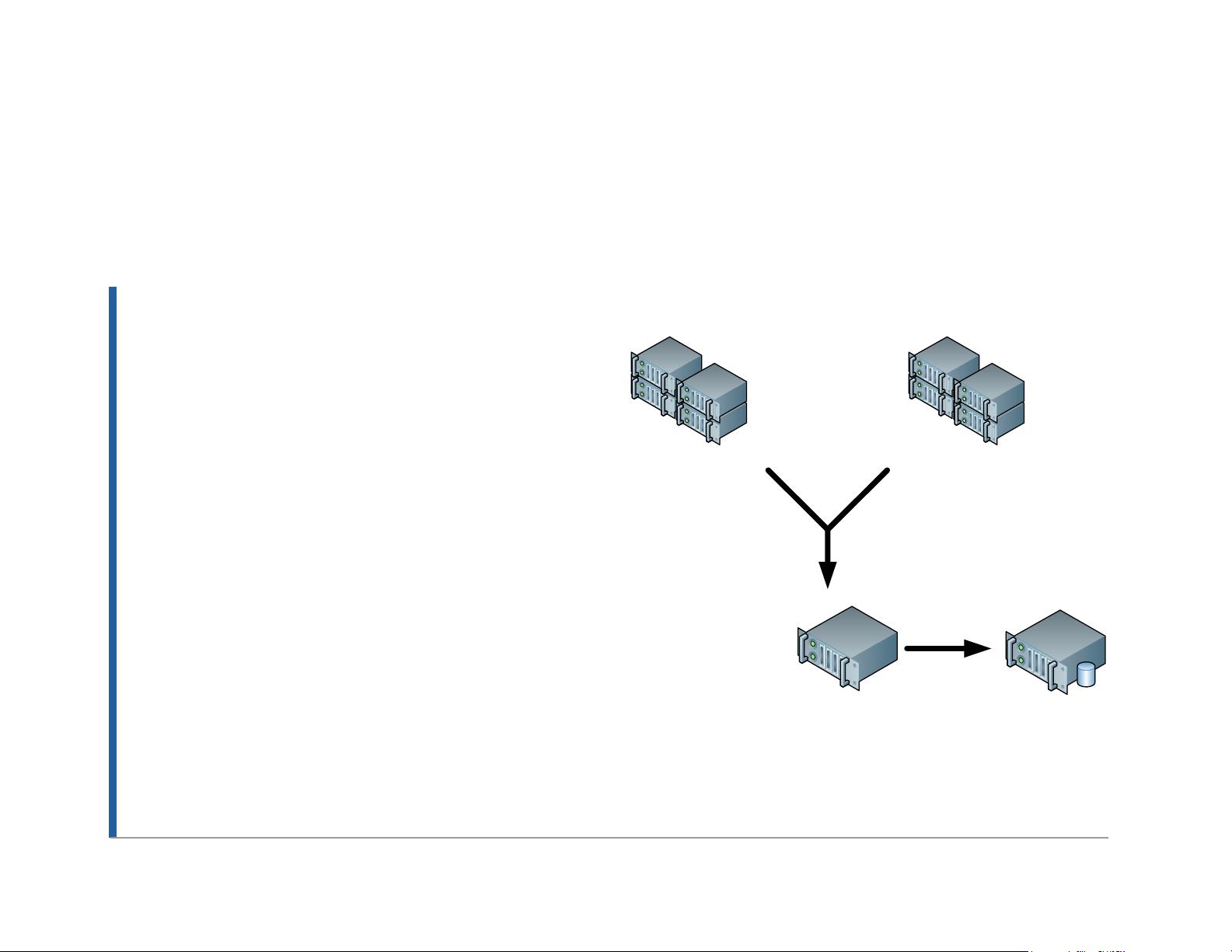
• Scribe and MySQL data loaded into
Hadoop HDFS
• Hadoop MapReduce jobs to process data
• Missing components:
– Command-line interface for “end users”
– Ad-hoc query support
• … without writing full MapReduce jobs
– Schema information