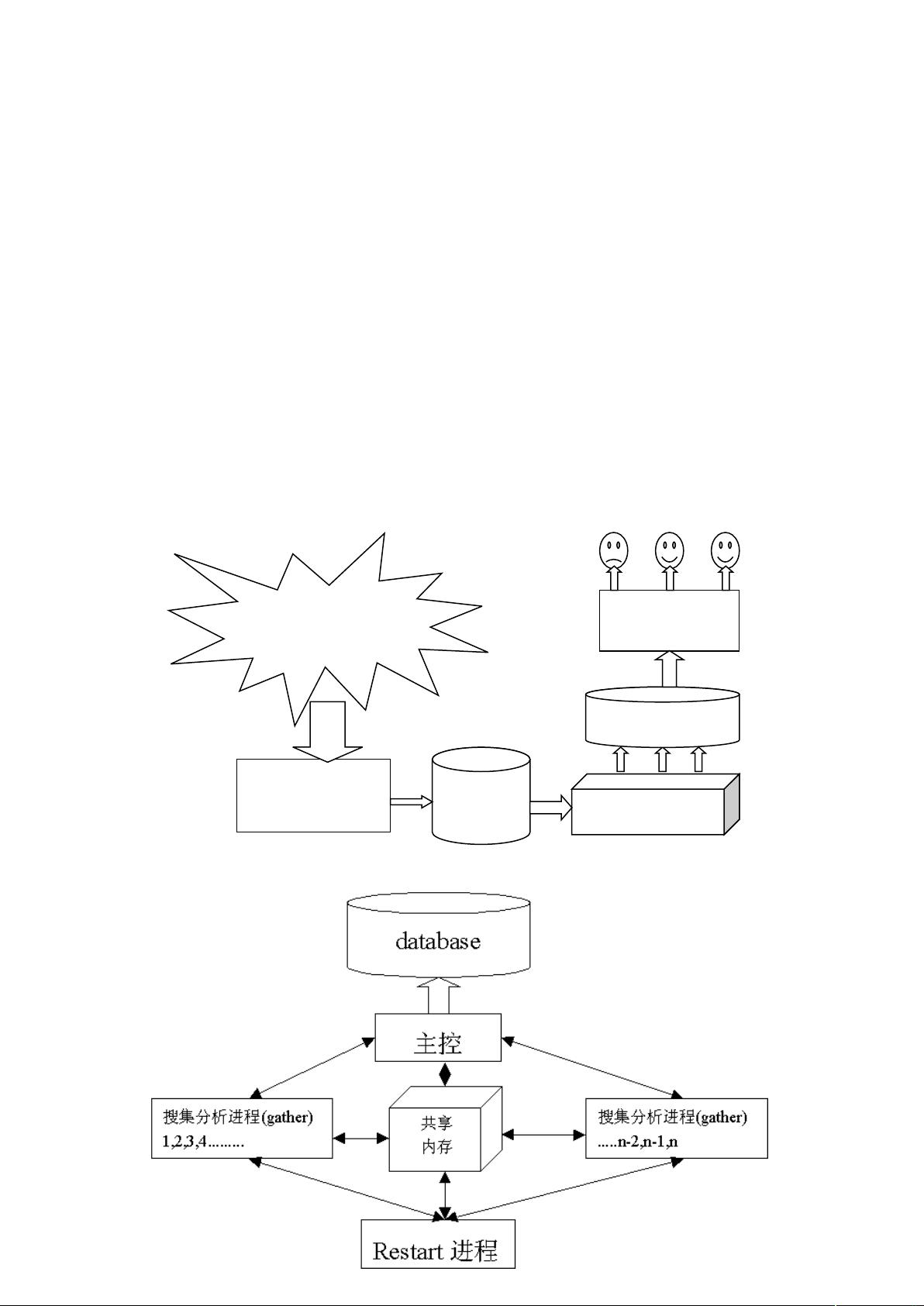
网搜索引擎”由两个主要部分组成,分别是搜索端和检索端[refer]。搜索端从
WWW 上抓取网页,经过分析提取出必要的信息存放到数据库中去(天网目前
使用的是 informix 数据库),当数据库完成一次更新后检索端便可依据数据库
中存放的信息对用户的检索请求做出答复了,也就是把用户想要的网页例出。
从检索的效率上考虑(数据库往往把功能作得很完善,我们宁可扔掉一部分于
我们无用的功能,来换取高速的读取),搜集端不是直接从 informix 数据库中
读取信息,而是从由数据库生成的中间文件中读取信息的。结构如图 2.1。
本文讨论的搜集端的各部分组件及其功能如图 2.2。
搜集端按如下方式工作,先由主控启动多个 gather 进程,并给它们逐一分配
一个网上的 URL,由它们负责去网上抓取网页。Gather 对取得的网页进行分析,
把结果送给主控,由主控对数据库进行操作,主控可以从 gather 送来的结果中
获得新的 URL,再分配给 gather。由于网络有时可能不能正常工作,gather 把
自己在某一时刻的工作状态纪录在共享内存里面,restart 进程负责巡视共享内
存,处理 gather 遇到的各种问题,改进程为什么被称作”restart”,是因为当它发
现有 gather 进程由于一些网络上的原因不能正常工作时(如分配的 URL 不存在,
我们称之为“死链”),由他结束该 gather 的本次任务,分配新的任务后重新开始。
为了协调网络速度和 CPU 处理能力的差异,在一台主机上启动多个 gather,并且
gather 数目可以调节。
§2.2 技术特点
搜索引擎最早只针对于对西文,西文(如英文,法文)又一个特点是,有
天然的分割语义的最小单位—词的分割符‘ ’(空格),而中文词与词之间没有
空格。在现代汉语中,大部分的词都是双字节、多字节词,其中单个字的意思
与整个词的意思相差甚远,尤其对大量涌入的音译外来词,如因特尔,迪士高,
麦当劳等,单个字与整个词的意思基本一点关系都没有。既然词是表达意思的
最小单位,“天网”通过一些切词程序,把词从网页中提取出来,网页信息以词
的形式被储存。在处理用户查询时,也从词的角度对用户输入作某种理解,再
去数据库中查找。这些词被称为关键词,要求能反映文章的内容。现代汉语词
类有名词、时间词、方位词、数词、量词,代词、动词、形容词、副词、介词、
连词、助词、拟声词,成语等等[ref]。这些词中,助词、连词、介词等词类是
不具有这种功能的,一大堆的“但是”、“虽然”、“的”、“呢”、“最”是不能让我们猜
出文章的任何内容的。这些词不能代表文章的内容,却在文章中以极高的词频
出现。我们把它们叫做“stop word”,在提取关键词时把这些词滤掉。
这一点是“天网”的基本特点,也是本文将要提到的基于关键词的“相似网页
发现算法”的基础。