





ISODATA 算法汇报文档
ISODATA 算法汇报文档
一. 算法介绍
1.背景
ISODATA(迭代自组织数据分析算法)来自模糊数学领域,是统计模式识别
中非监督动态聚类算法的一种。
在许多科学实验、经济管理和日常生活中,往往需要对某些指标(或
事物)按一定的标准(相似的程度、亲疏关系等)进行分类处理。例如,
根据生物的某些形态对其进行分类,图像识别中对图形的分类等。这种对
客观事物按一定要求和规律进行分类的数学方法主要就是聚类分析法,聚
类分析是数理统计中研究“物以类聚”的一种多元分析方法,而模糊聚类分析
法是通过数学工具根据事物的某些模糊性质进行定量地确定、合理地分型
划类的数学方法。
2、算法基本思想
J . C. Bezdek 在普通分类基础上, 利用模糊集合的概念提出了模糊分类问
题。认为被分类对象集合X 中的样本x [i] 以一定的隶属度属于某一类,即所
有的样本都分别以不同的隶属度属于某一类。因此,每一类就被认为是样本
集X 上的一个模糊子集,于是,每一种这样的分类结果所对应的分类矩阵,就是
一个模糊矩阵。ISODA TA 聚类方法预先确定样本应该分成几类,从先给出的
一个初始分类出发,根据目标函数, 用数学迭代计算的方法反复修改模糊矩阵,
直到合理为止。
3、算法基本原理
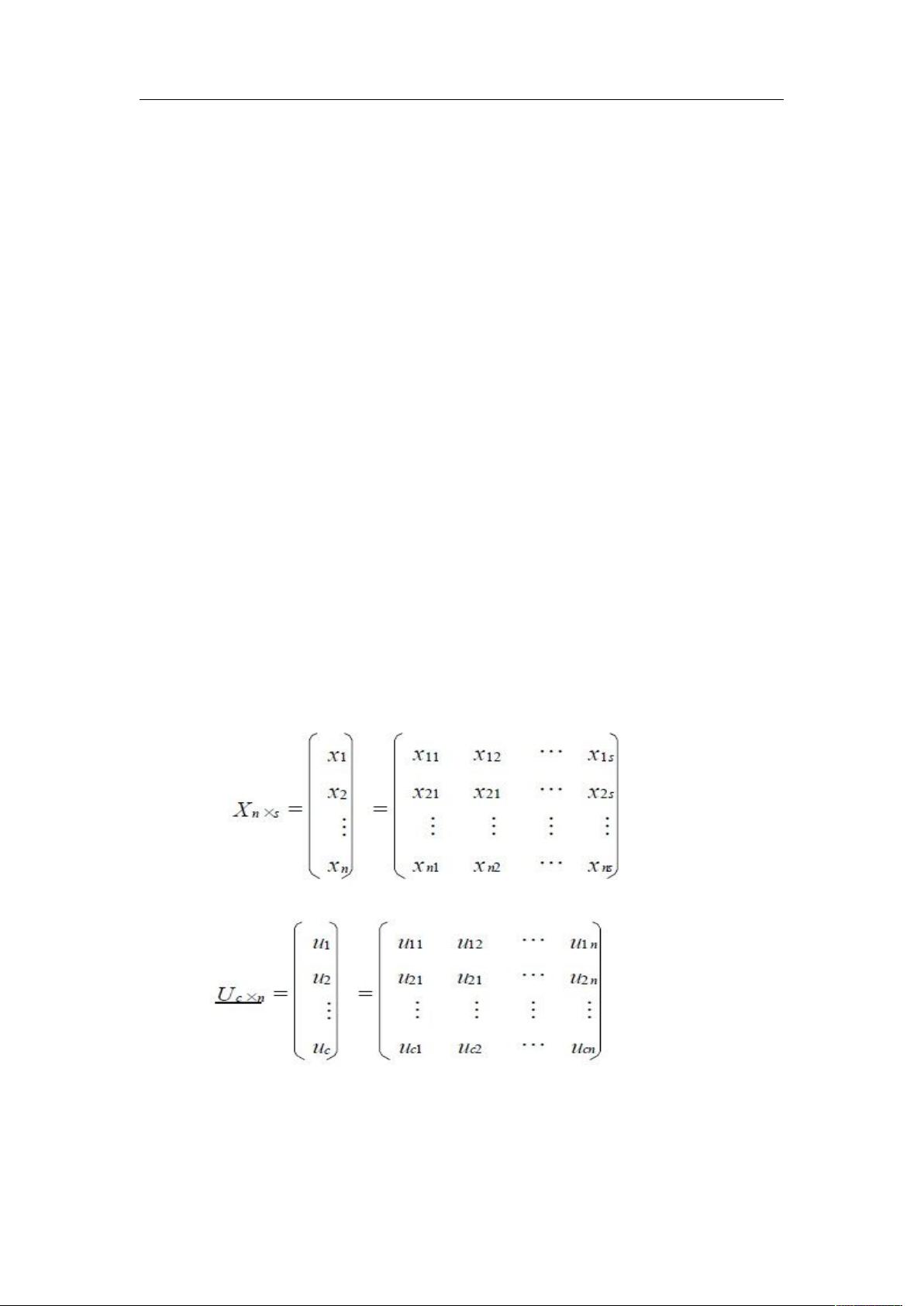
设 有限样本集( 论域 ) X={ X1,X2,…Xn } , 每 一 个样 本 有 s 个 指标 ,
Xj=( xj1,xj2,…xjs) ,j=1,2,…n.
及样本的特征矩阵:
欲把它分为 c 类(2<c<n),则 n 个样本划分为 c 类的模糊分类矩阵为:
其满足三个条件:(i=1,2,…c;j=1,2,…n)
1















- 1
- 2
前往页