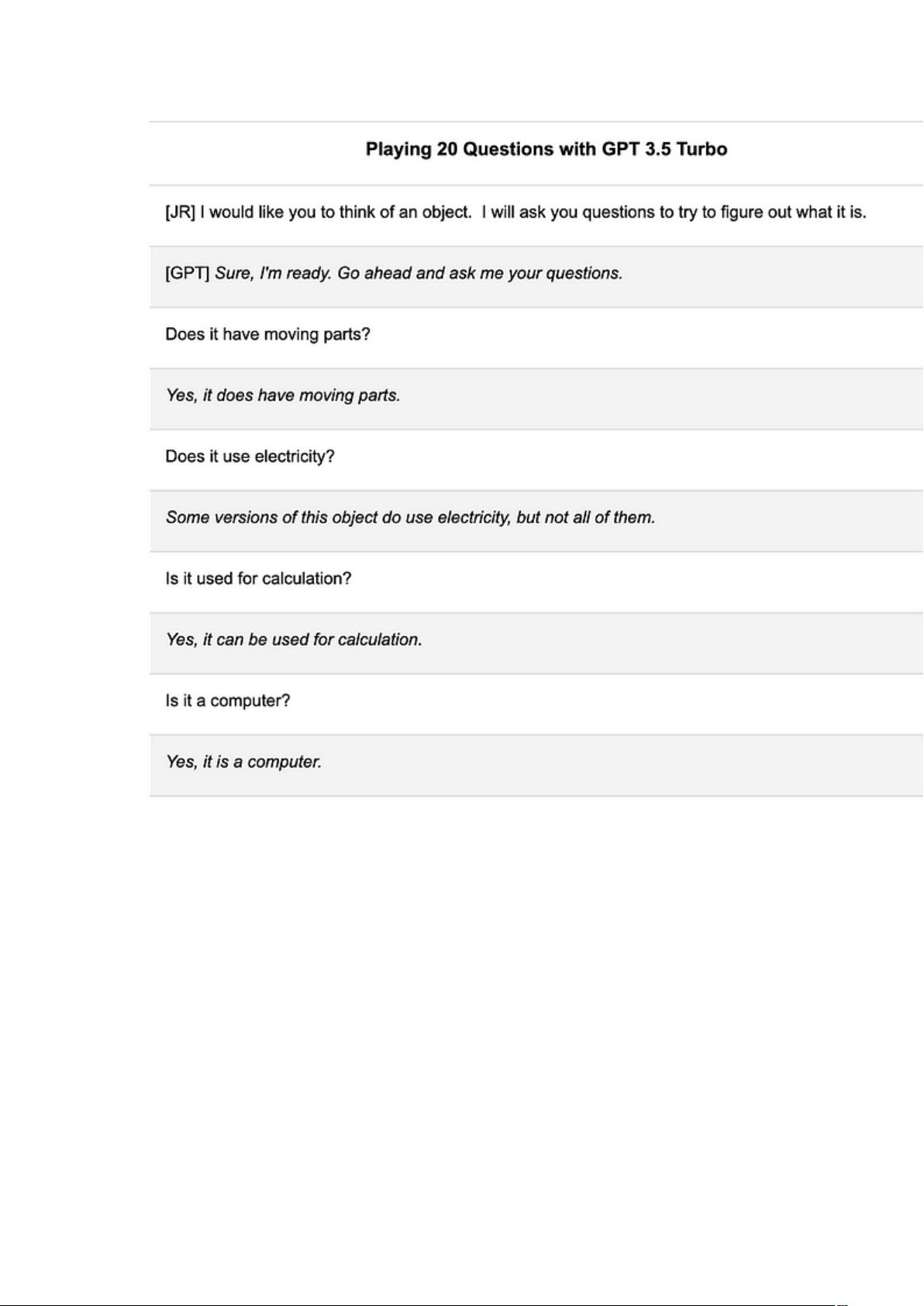
迄今为止,GPT-4 仅在 ChatGPT 界面中公开可用,无法控制
导致其输出具有确定性的设置,因此模型可以对相同的输入做出
不同的响应。然而,GPT-3.5 Turbo 可通过 API [ 7 ] 在其令牌
选择中使用可配置的“top_p”获得,当设置为较小的数字时,可
确保模型始终返回单个最可能的令牌预测,因此始终返回相同的
输出对特定成绩单的回应²。这让我们可以问“如果我有呢?” 问
题以重新运行之前的对话并在早期阶段提供不同的问题——比如
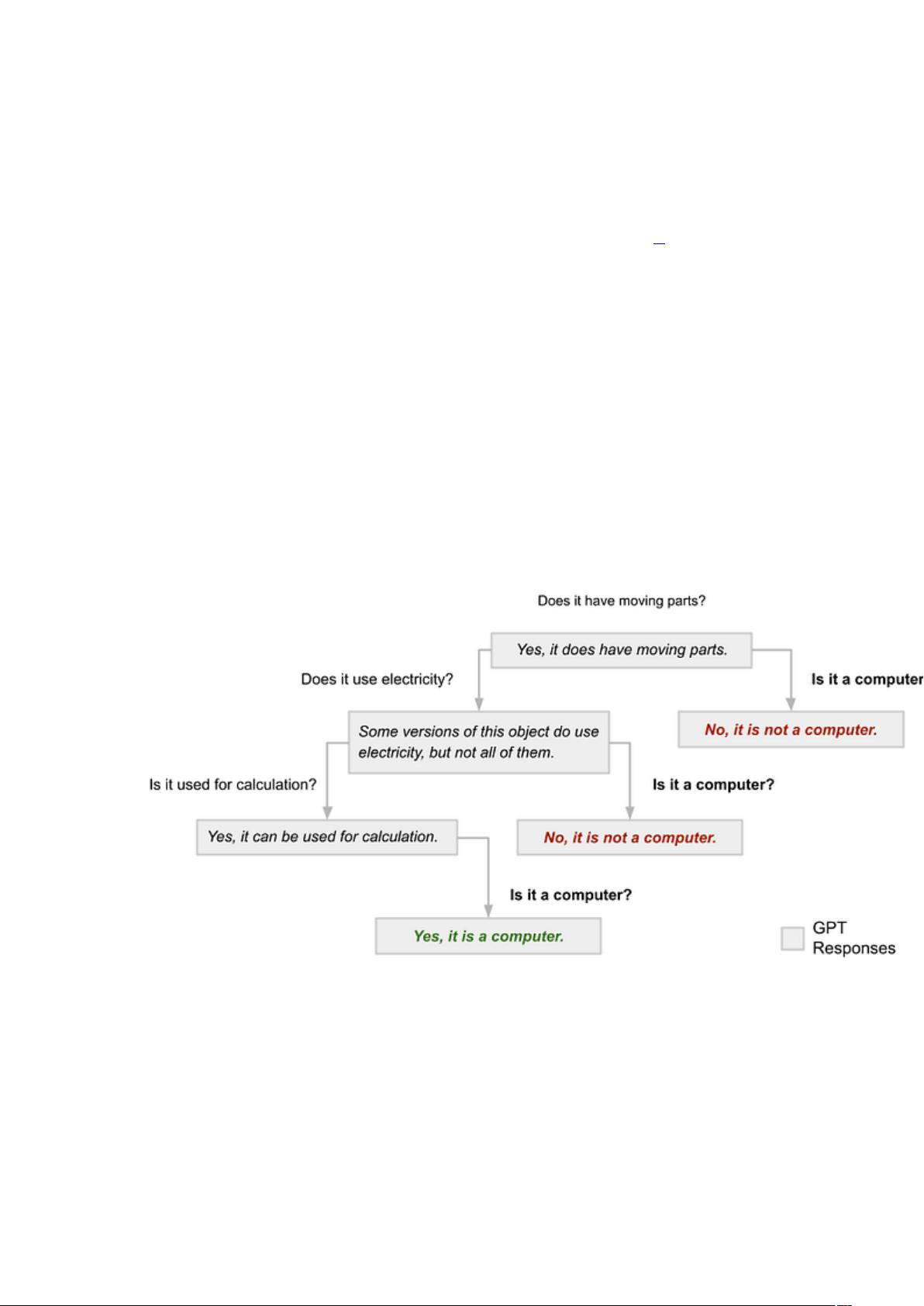
时间旅行。我在下面绘制了三个可能的对话框,最左边的是上面
共享的变体:
与 GPT-3.5 Turbo 的三个不同对话设置为产生确定性输出。其回答的
不一致表明模型直到原始对话的最后一个问题(最左边的分支)才“决
定”接受计算机作为正确答案。