# LogiReg
Python 机器学习实战:根据成绩预测大学生能否被高校录取
博客连接:https://blog.csdn.net/qq_40938646/article/details/95046637
**1、首先,导入库,并且读取数据集。原来数据集是 .txt 结尾的。**
由于原始数据中并没有给出每一列的列的名字,所以,我们自己加一个 “Exam 1”、"“Exam 2”、"Admitted",我们最好列举前几行数据,确认一下是否读入了数据,并且,看一下数据的维度:
```py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
# 路径
path = 'LogiReg_data.txt'
# 原文件没有表头,加一个表头:'Exam1','Exam2','Admitted'
pdData = pd.read_csv(path, header=None, names=['Exam 1', 'Exam 2', 'Admitted'])
# 输出读取数据
print(pdData)
pdData.head()
pdData.shape
```
结果:
: 
**2.将数据分成正负样本,利用散点图,大致看一下数据分布**(不是必要步骤,而且因为数据只有两个维度,才添加了此步骤)
```py
# 录取
positive = pdData[pdData['Admitted'] == 1]
# 未录取
negative = pdData[pdData['Admitted'] == 0]
# fig表示窗口,ax表示坐标轴
fig, ax = plt.subplots(figsize=(10, 5))
# 散布点,c='b'表示蓝色。 marker='x'表示标记 label左为左上角的标签
ax.scatter(positive['Exam 1'], positive['Exam 2'], s=30, c='b', marker='o', label='Admitted')
ax.scatter(negative['Exam 1'], negative['Exam 2'], s=30, c='r', marker='x', label='Not Admitted')
ax.legend()
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
# 绘图
plt.show()
```
绘图结果:
: 
补充说明一下:Admitted 是标签,当标签为 1 时,认为是正样本;标签为 0 时,认为是负样本。而 pd Data['Admitted'] == 1,是一堆 True 和 false
**3、逻辑回归**
此部分,我们主要建立一个分类器:也就是求解 theta 值。然后设定阈值,根据阈值,判断是否被录取。
**主要步骤如下:**
> (1)、定义 sigmoid 函数
```py
# 定义sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
```
sigmoid 函数是将预测值(比如线性回归中的结果),映射为概率的一个函数。形式为:

```py
# creates a vector containing 20 equally spaced values from -10 to 10
nums = np.arange(-10, 10, step=1)
fig, ax = plt.subplots(figsize=(12, 4))
ax.plot(nums, sigmoid(nums), 'r')
# 绘图
plt.show()
```
其中,自变量 z 为任意值,而 g(z) 的值域为 (0,1),(0,1)也就是对应着概率的大小。曲线图如下

>(2)定义模型,也就是预测函数
```py
# 定义模型函数
# X 是样本数据,它的每一行都是一个样本,每一列为样本的某一个特征。
# theta 表示参数,它是我们通过学习获得的,其中,对于每一个特征,都对应一个 theta
def model(X, theta):
return sigmoid(np.dot(X, theta.T))
```
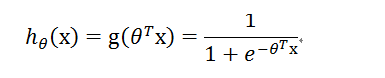
将 sigmoid () 函数的自变量 z 变成上式。其中,X 是样本数据,它的每一行都是一个样本,每一列为样本的某一个特征。theta 表示参数,它是我们通过学习获得的,其中,对于每一个特征,都对应一个 theta ,即
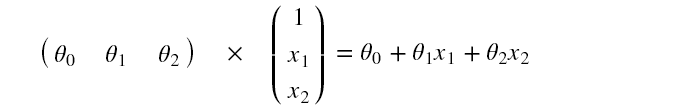
其中,为偏置项,因此,要在原始数据上补上一列,值为 1 ,是为了形式上的统一,方便矩阵运算,
```py
# 在第 0 列,插入一列,名称为"Onces",数值全为 1
pdData.insert(0, 'Onces', 1)
# X:训练数据 Y:目标值
# 将数据的panda表示形式转换为对进一步计算有用的数组
# 这个方法过时会有警告
orig_data = pdData.as_matrix()
cols = orig_data.shape[1]
X = orig_data[:, 0:cols - 1]
y = orig_data[:, cols - 1:cols]
# 初始化theta
theta = np.zeros([1, 3])
X.shape, y.shape, theta.shape
```
>(3) 定义损失函数
损失函数是将对数似然函数,乘以一个负号。乘以负号是为了将求解梯度上升转换为求解梯度下降
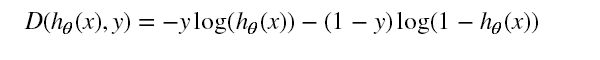
这是整体的一个损失,但是,不同的样本量,总损失肯定是不同的,因此,为了确定一个统一标准,使用平均损失,即将总损失除以样本个数,

```py
# 定义损失函数
def cost(X, y, theta):
left = np.multiply(-y, np.log(model(X, theta)))
right = np.multiply((1 - y), np.log(1 - model(X, theta)))
return np.sum(left - right) / (len(X))
```
使用print输出下面结果,结果是0.69314718055994529
```py
# 将数值带入计算损失值
cost(X, y, theta)
```
> (4)梯度的计算与参数的更新
计算梯度的目的是寻找极值,确定损失函数如何进行优化,使损失函数的值越来越小。
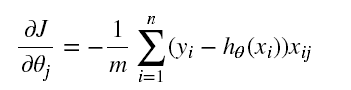
参数的更新策略为:

我们需要通过迭代来计算梯度,然后,梯度的计算什么时候停止呢?这里有三种停止策略:
1、设置固定的迭代次数
2、设置损失函数的阈值,当达到一定阈值时,就停止迭代。
3、通过梯度的变化率来判断:设置前后两次梯度相差的阈值,如果小于该阈值,停止迭代。
相关代码如下:
```py
# 计算梯度
# 计算每个参数的梯度方向
def gradient(X, y, theta):
grad = np.zeros(theta.shape)
error = (model(X, theta) - y).ravel()
for j in range(len(theta.ravel())): # for each parmeter
term = np.multiply(error, X[:, j])
grad[0, j] = np.sum(term) / len(X)
return grad
# 设置三种策略
STOP_ITER = 0
STOP_COST = 1
STOP_GRAD = 2
def stopCriterion(type, value, threshold):
# 设定三种停止策略
if type == STOP_ITER:
return value > threshold
elif type == STOP_COST:
return abs(value[-1] - value[-2]) < threshold
elif type == STOP_GRAD:
# linalg=linear(线性)+algebra(代数),norm则表示范数
return np.linalg.norm(value) < threshold
import numpy.random
# 洗牌
def shuffleData(data):
np.random.shuffle(data)
cols = data.shape[1]
X = data[:, 0:cols - 1]
y = data[:, cols - 1:]
return X, y
import time
def descent(data, theta, batchSize, stopType, thresh, alpha):
# 梯度下降
init_time = time.time()
# 迭代次数
i = 0
# batch
k = 0
X, y = shuffleData(data)
# 计算的梯度
grad = np.zeros(theta.shape)
# 损失值
costs = [cost(X, y, theta)]
while True:
grad = gradient(X[k:k + batchSize], y[k:k + batchSize], theta)
# 取batch数量个数据
k += batchSize
# 这个 n 是在运行的时候指定的,为样本的个数
if k >= n:
k = 0
# 重新洗牌
X, y = shuffleData(data)
# 参数更新
theta = theta - alpha * grad
# 计算新的损失
costs.append(cost(X, y, theta))
i +=
Python 机器学习实战:根据成绩预测大学生能否被高校录取.zip

需积分: 5 137 浏览量
2024-04-28
22:27:47
上传
评论
收藏 10KB ZIP 举报
 Python 机器学习实战:根据成绩预测大学生能否被高校录取.zip (3个子文件)
Python 机器学习实战:根据成绩预测大学生能否被高校录取.zip (3个子文件)  content
content  LogiReg_data.txt 4KB
LogiReg_data.txt 4KB logiReg.py 6KB README.md 13KB
logiReg.py 6KB README.md 13KB资源评论


生瓜蛋子
- 粉丝: 3794
- 资源: 4173









最新资源
- 关于数据分析工具的问题 (Excel、PowerBI-Tableau、R-Python)-教程案例分享.zip
- jqueryUI管理后台+WeiXinApp微信小程序+uni例子内容 参数例子,学习用
- 基于聚类分析分批训练的BP神经网络回归分析
- 计算机大类学生课程实验心得、案例-基于Python 的图像处理实验.zip
- CocosDashboard-v2.1.3-win-042311.exe
- vue3-admin-master-后台管理平台模板.zip
- 基于yolov5和deepsort算法的车辆检测项目源码+数据集(高分项目).zip
- 使用Python的requests库和BeautifulSoup库进行网页爬取的示例案例
- 蓝色个人主页接单HTML源码.zip
- 基于YOLOv5+Deepsort实现车辆行人追踪和计数(完整源码+说明文档+数据).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


