### 深度学习-Transformer解读
#### Transformer简介与架构特点
Transformer模型是近年来自然语言处理(NLP)领域的一项重大突破,它摒弃了传统的循环神经网络(RNN)结构,采用了一种全新的机制——自注意力(Self-Attention),从而极大地提升了模型的效率和性能。相较于RNN,Transformer的主要优势在于能够实现并行计算,这意味着模型可以在处理序列数据时避免逐个元素的串行处理,大大减少了训练时间。
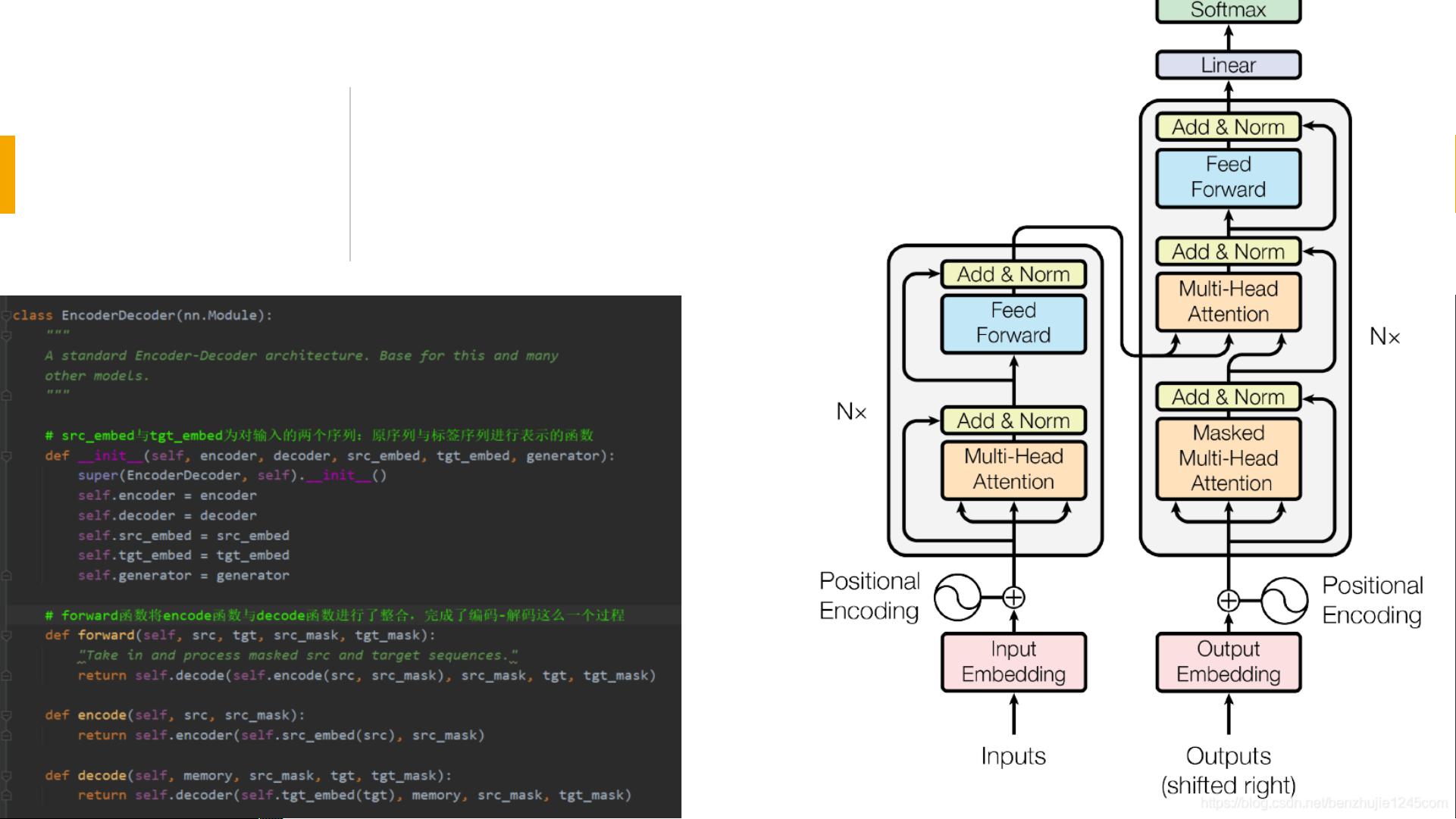
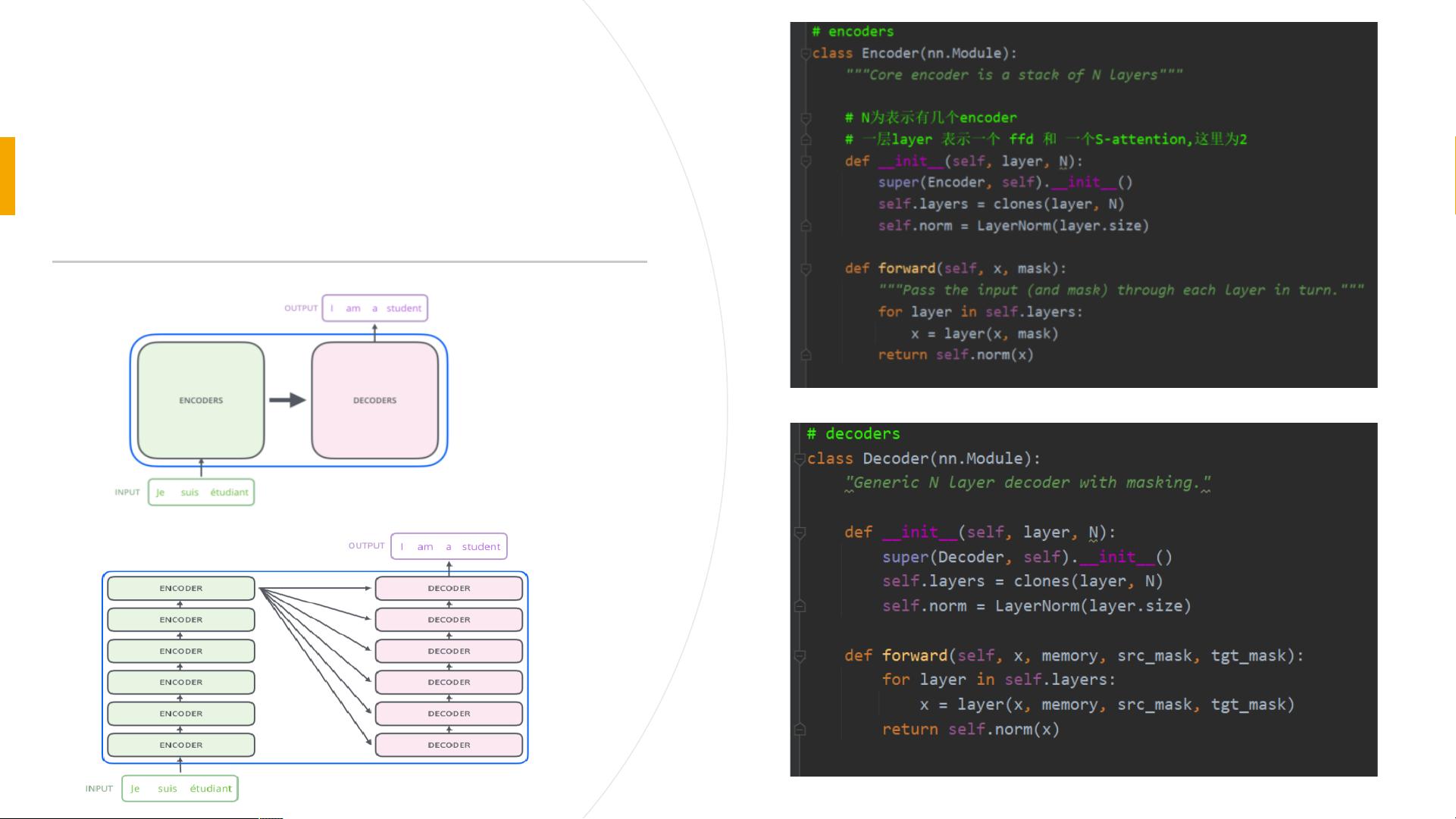
**Transformer的整体架构**遵循了一种经典的Encoder-Decoder设计思路,其中:
- **Encoder**负责对输入序列进行编码,捕捉其中的语义信息;
- **Decoder**则根据Encoder的输出来生成目标序列,如翻译、文本摘要等任务中的输出。
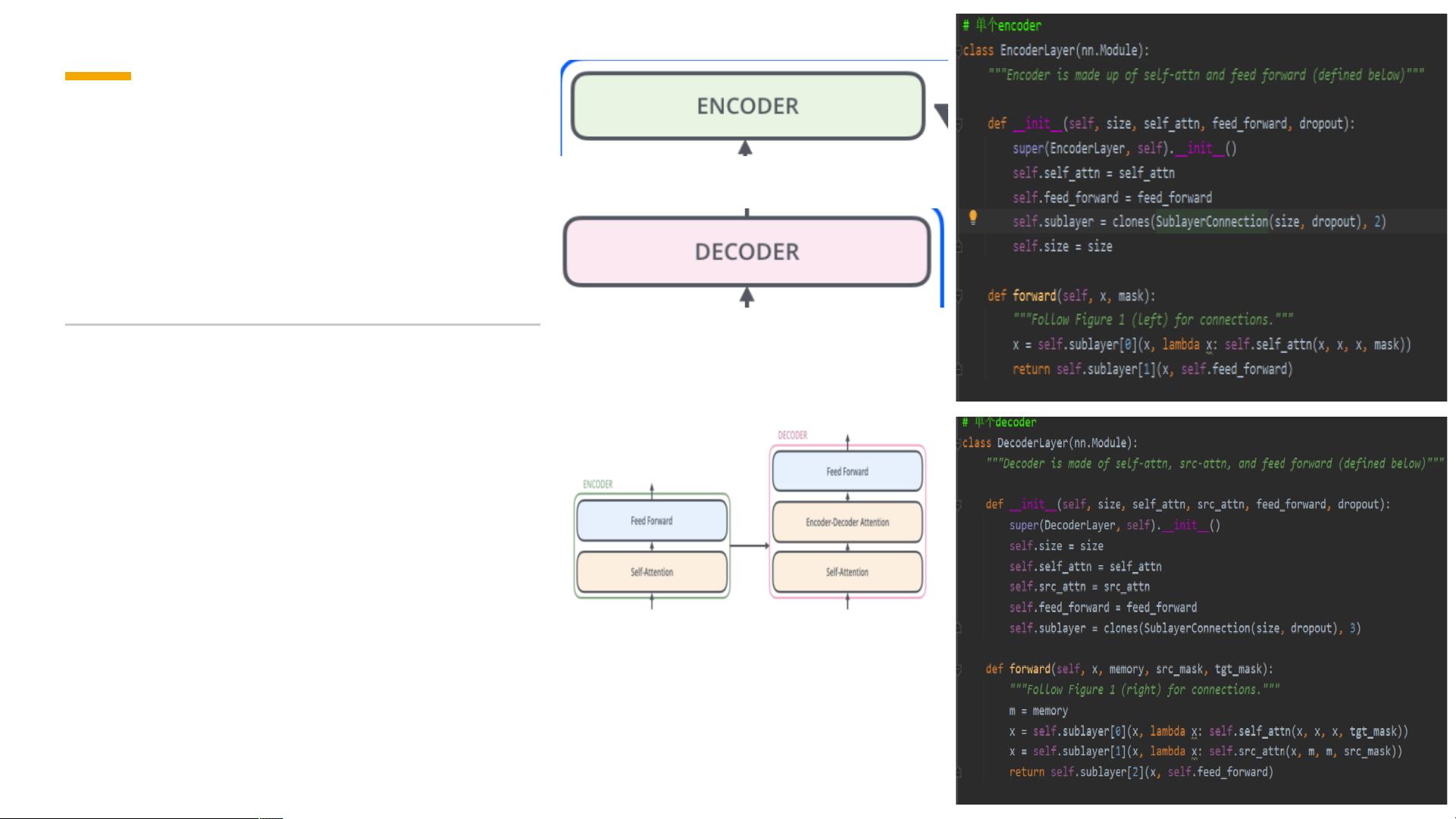
每个Encoder或Decoder由若干个相同的子层构成,但它们之间的权重并不共享。
#### Self-Attention机制解析
Self-Attention机制是Transformer的核心所在,其核心思想是在处理序列中的某个元素时,不仅考虑该元素自身的信息,还会参考序列中其他所有元素的信息。这一机制解决了RNN存在的问题,即难以有效捕捉长距离依赖关系。
##### Self-Attention工作原理
以翻译任务为例:“The animal didn't cross the street because it was too tired”,在这个句子中,“it”指代的是“animal”而非“street”。人类读者能够轻易理解这一点,但对于机器而言则较为困难。Self-Attention机制通过构建各个词汇间的相互关系,帮助模型理解这种指代关系。
在实现上,Self-Attention机制首先将输入序列中的每一个词汇转换为其对应的词嵌入向量,然后通过三个不同的权重矩阵\(W_Q\)、\(W_K\)、\(W_V\)将这些向量分别转化为Query向量、Key向量和Value向量。通过计算Query向量与Key向量之间的相似度得分,并应用softmax函数对其进行归一化处理,可以得到每个词汇与其他词汇之间的注意力分布。
例如,对于输入序列“Thinking Machines”,经过Self-Attention处理后,每个词汇都将拥有一个表示它与其他词汇之间注意力分布的向量\(Z\)。这里的\(Z_1\)和\(Z_2\)分别表示“Thinking”和“Machines”这两个词汇在其位置上对于其他词汇的关注程度。
#### Multi-Head Attention机制
Multi-Head Attention进一步优化了Self-Attention机制,引入了多头注意力的概念。具体来说,它允许模型同时关注输入的不同位置,增强了模型的理解能力。例如,在处理指代消解任务时,多头注意力可以让模型更好地判断“it”是指代“animal”还是“street”。
此外,Multi-Head Attention还为注意力层提供了多个“表示子空间”,这意味着通过不同的权重矩阵\(W_Q\)、\(W_K\)、\(W_V\),可以将输入向量投影到多个不同的表示空间中。在Transformer中,通常使用8个头,因此会产生8个不同的注意力分布矩阵。
为了将这些矩阵整合成单一的输出矩阵以供后续处理,Transformer采用了连接操作,即将这些矩阵水平连接起来形成一个大矩阵,然后通过另一个权重矩阵\(W_O\)将其转换为最终的输出。
#### Masked Multi-Head Attention
Masked Multi-Head Attention是对Multi-Head Attention的一种扩展,主要应用于Decoder中。它的关键点在于引入了掩码(mask)机制,用于解决两个主要问题:
1. **Padding Mask**:由于输入序列的长度不一,需要在较短序列的末尾添加填充(通常是0)。然而,这些填充位并没有实际意义,因此需要通过加上一个很大的负数来确保它们在Softmax运算后的权重接近0。
2. **Sequence Mask**:为了避免Decoder看到未来的信息,即在预测当前时间步的输出时不能利用未来时间步的信息。这通常通过构建一个上三角矩阵并将其应用于注意力得分来实现,以确保模型仅能关注当前及之前的时间步。
总而言之,Masked Multi-Head Attention机制不仅提高了模型的实用性,还增强了其在序列生成任务中的表现。通过对不同类型的掩码的应用,Transformer能够在多种应用场景中表现出色,包括但不限于机器翻译、文本生成和问答系统等。