

双子座:一系列高能力多模态模型
Gemini团队,Google1
本报告介绍了一种新的多模态模型家族Gemini,它在图像、音频、视频和文本理解方面具有卓越
的能力。Gemini系列包括Ultra、Pro和Nano三种尺寸,适用于从复杂的推理任务到设备内存受限
的应用场景。对广泛的基准测试的评估表明,我们最有能力的Gemini Ultra模型在32个基准测试
中的30个中提高了最先进的水平-特别是第一个在经过充分研究的考试基准测试MMLU上实现人类专
家性能的模型,并在我们检查的20个多模态基准测试中的每一个中提高了最先进的水平。我们相
信Gemini模型在跨模态推理和语言理解方面的新能力将能够实现各种用例,并且我们讨论了我们
负责任地向用户部署它们的方法。
1.
介绍
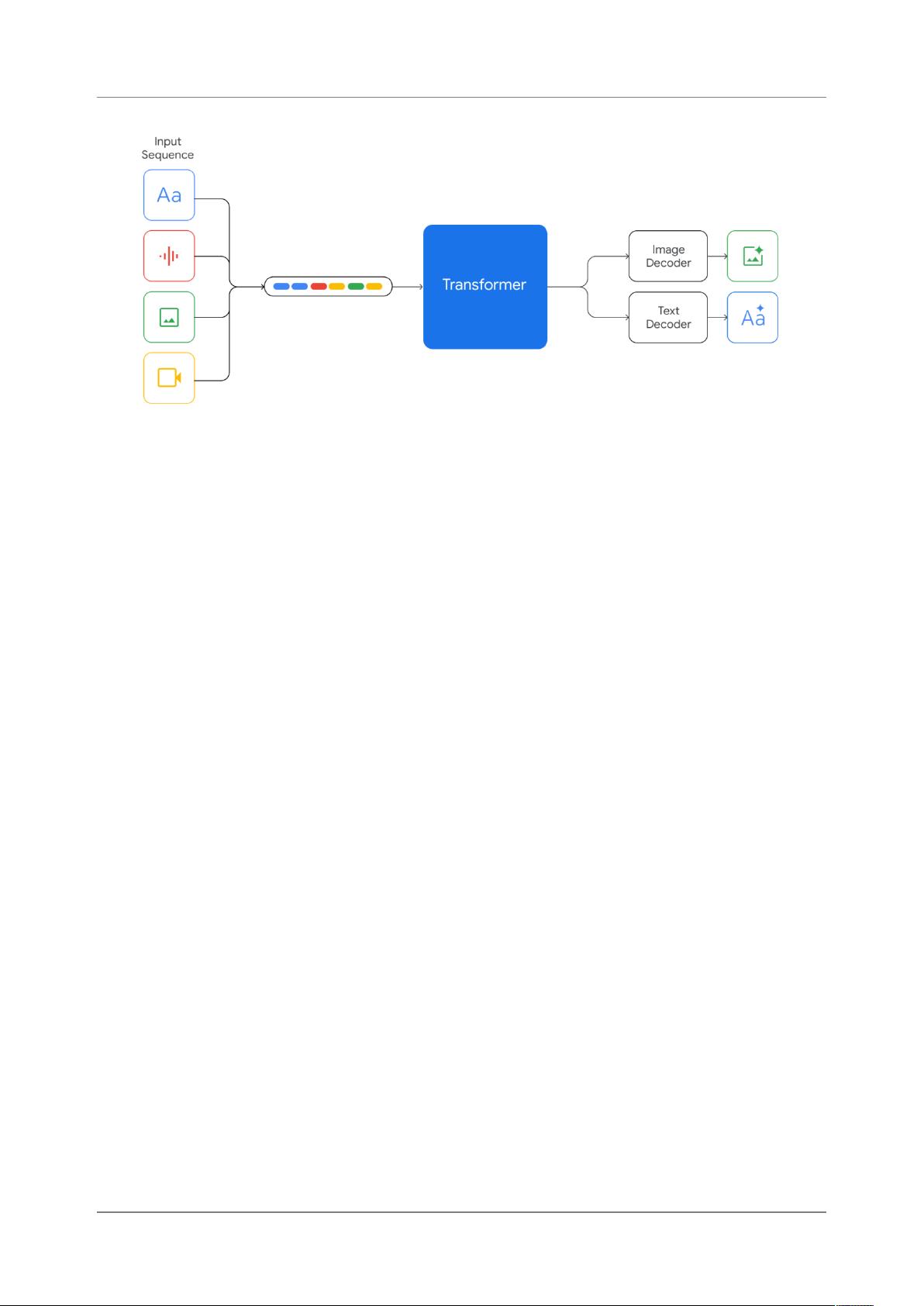
我们在Google开发了一系列高性能的多模态模型Gemini。我们通过图像、音频、视频和文本数据
共同训练了Gemini,目的是构建一个在各个模态中具有强大的通用能力以及在各个领域中具有尖
端的理解和推理性能的模型。
Gemini 1.0,我们的第一个版本,有三种尺寸:Ultra适用于高度复杂的任务,Pro提供增强性
能和可扩展性,适用于大规模部署,Nano适用于设备上的应用程序。每个尺寸都经过特别设计以
满足不同的计算限制和应用要求。我们对Gemini模型在广泛的语言、编码、推理和多模态任务上
进行了全面的内部和外部基准测试。
Gemini 推 进 了 大 规 模 语 言 建 模 的 最 新 技 术 ( Anil 等 , 2023; Brown et al.,77.7%2023;
Hoffmann et al.,2022年;OpenAI,2023a;Radford等人,2019; Rae等人,2021年),图像理解
(Alayrac等人,2022年; Chen等人,2022年; Dosovitskiy等人。从中学和高中数学竞赛(MATH基
准)中抽取的难度增加的数学问题中观察到类似的积极趋势,Gemini Ultra模型表现优于所有竞
争对手模型,在4次提示下达到53.2%的准确率。2022年; 于等人,2017年)通过改进架构和模型
优化,实现了稳定的大规模训练和在Google的Tensor Processing Units上进行优化推理。2022a)
,音频处理(Radford等人,Google的2023年;张等人,2023年),以及视频理解(Alayrac等人
,2022年; Chen等人,2023年。它还基于序列模型的工作(Sutskever等人)。2014年,基于神经
网络的深度学习有着悠久的历史(LeCun等人)。此外,Gemini可以直接从通用语音模型(USM)
(Zhang等人,2020; Chowdhery等人,2015)中以16kHz的音频信号进行输入。2022; Bradbury等
人。2018; Dean et al.2012),使大规模培训成为可能。
我们最强大的模型Gemini Ultra在我们报告的32个基准测试中,在30个基准测试中取得了最新
的最先进结果,其中包括12个流行的文本和推理基准测试中的10个,9个图像理解基准测试中的9
个,6个视频理解基准测试中的6个,以及5个语音识别和语音翻译基准测试中的5个。Gemini
Ultra是第一个在MMLU上实现人类专家水平表现的模型(Hendrycks等人)。2021 a)-通过一系列
考试测试知识和推理的突出基准-得分超过90%。除了文本,Gemini Ultra在具有挑战性的多模态
推理任务方面取得了显着进展。例如,在最近的MMMU基准(Yue等人,2023年),其中包括关于多
学科任务上的图像的问题,需要大学水平的学科知识
请参阅贡献和致谢部分以获取完整的作者列表。请发送信件至gemini-1-report@google.com
© 2023 Google.版权所有



剩余79页未读,继续阅读
资源评论


猫头虎
- 粉丝: 33w+
- 资源: 554









最新资源
- 此存储库适用于 Linkedin Learning 课程学习 Java.zip
- (源码)基于STM32和AD9850的无线电信标系统.zip
- (源码)基于Android的新闻推荐系统.zip
- 本资源库是关于“Java Collection Framework API”的参考资料,是 Java 开发社区的重要贡献,旨在提供有关 Java 语言学院 API 的实践示例和递归教育关系 .zip
- 插件: e2eFood.dll
- 打造最强的Java安全研究与安全开发面试题库,帮助师傅们找到满意的工作.zip
- (源码)基于Spark的实时用户行为分析系统.zip
- (源码)基于Spring Boot和Vue的个人博客后台管理系统.zip
- 将流行的 ruby faker gem 引入 Java.zip
- (源码)基于C#和ArcGIS Engine的房屋管理系统.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


