

Systematic attribute reductions based on double granulation structures and
three-view uncertainty measures in interval-set decision systems
Xin Xie
a,b
, Xianyong Zhang
a,b,c,∗
a
School of Mathematical Sciences, Sichuan Normal University, Chengdu 610066, China
b
Institute of Intelligent Information and Quantum Information, Sichuan Normal University, Chengdu 610066, China
c
Visual Computing and Virtual Reality Key Laboratory of SiChuan Province, Sichuan Normal University, Chengdu 610066, China
Abstract
Attribute reductions eliminate redundant information to become valuable in data reasoning. In the data context of
interval-set decision systems (ISDSs), attribute reductions rely on granulation structures and uncertainty measures;
however, the current structures and measures exhibit the singleness limitations, so their enrichments imply corre-
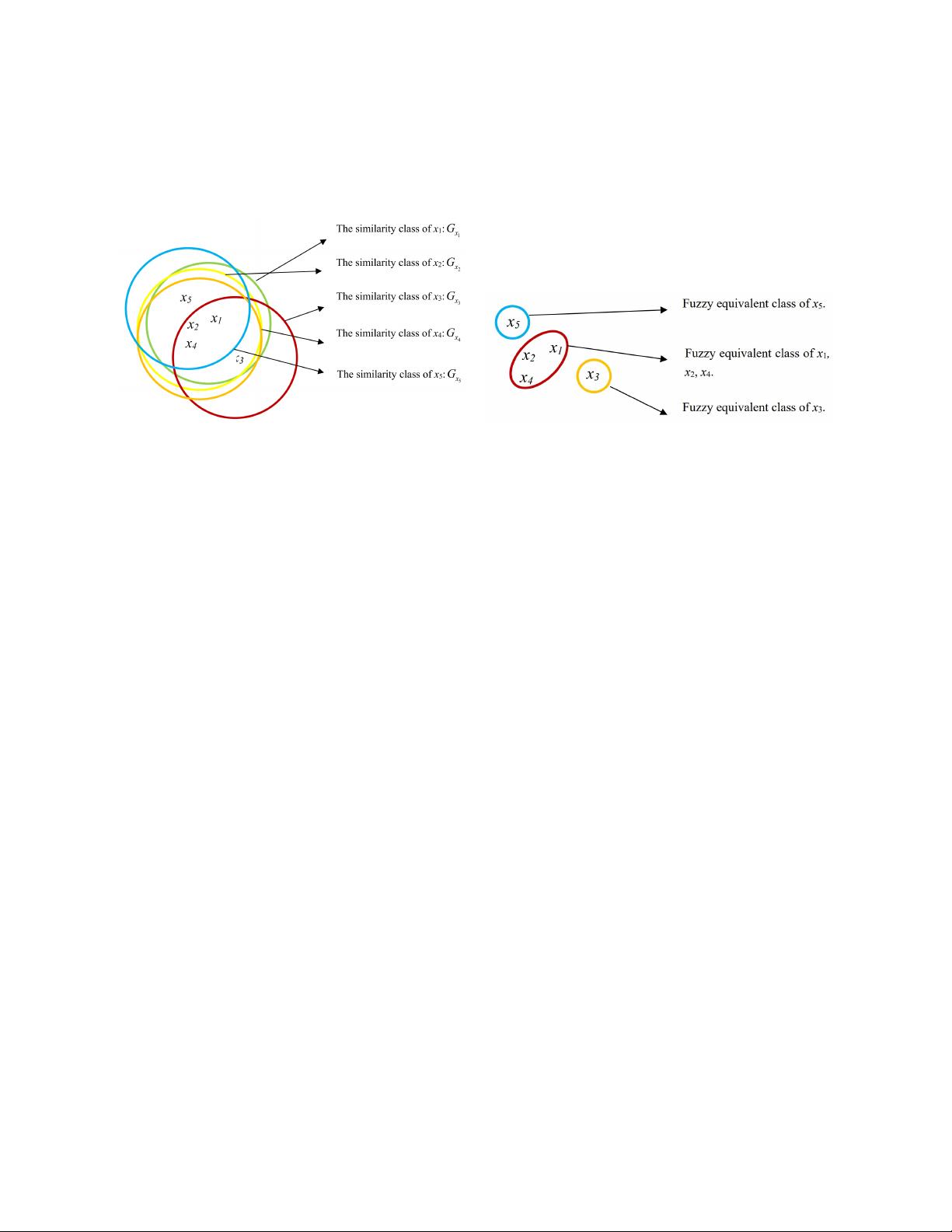
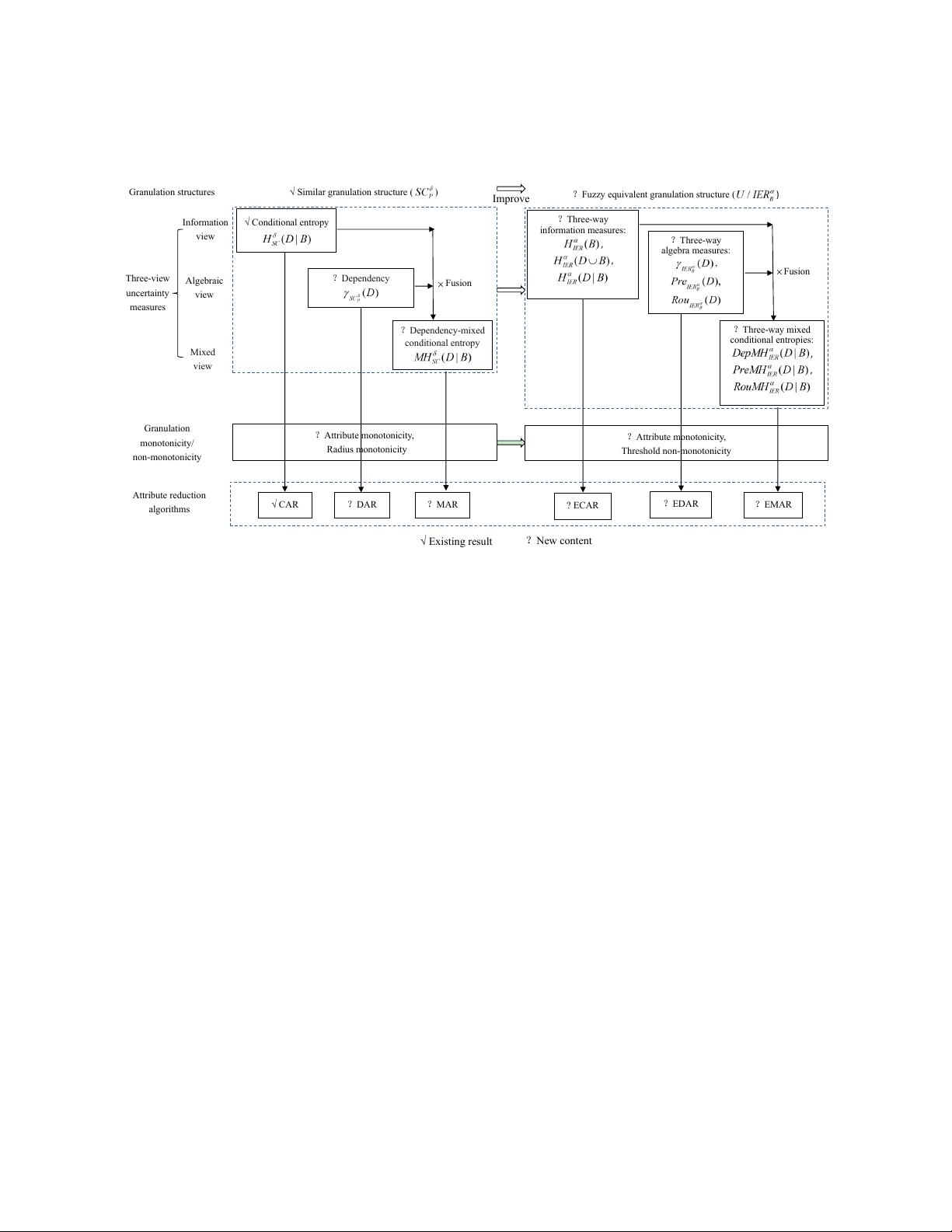
sponding improvements of attribute reductions. Aiming at ISDSs, a fuzzy-equivalent granulation structure is proposed
to improve the existing similar granulation structure, dependency degrees are proposed to enrich the existing condition
entropy by using algebra-information fusion, so 3×2 attribute reductions are systematically formulated to contain both
a basic reduction algorithm (called CAR) and five advanced reduction algorithms. At the granulation level, the similar
granulation structure is improved to the fuzzy-equivalent granulation structure by removing the granular repeatability,
and two knowledge structures emerge. At the measurement level, dependency degrees are proposed from the algebra
perspective to supplement the condition entropy from the information perspective, and mixed measures are gener-
ated by fusing dependency degrees and condition entropies from the algebra-information viewpoint, so three-view
and three-way uncertainty measures emerge to acquire granulation monotonicity/non-monotonicity. At the reduction
level, the two granulation structures and three-view uncertainty measures two-dimensionally produce 3×2 heuristic re-
duction algorithms based on attribute significances, and thus five new algorithms emerge to improve an old algorithm
(i.e., CAR). As finally shown by data experiments, 3 × 2-systematic construction measures and attribute reductions
exhibit the effectiveness and development, comparative results validate the three-level improvements of granulation
structures, uncertainty measures, and reduction algorithms on ISDSs. This study resorts to tri-level thinking to enrich
the theory and application of three-way decision.
Keywords: Attribute reduction; Interval-set decision system; Granulation structure; Uncertainty measure; Condition
entropy; Granulation monotonicity/non-monotonicity
1. Introduction
Attribute reductions in rough set theory are related to feature selections in machine learning, and they mainly
reduce data dimensionality to facilitate information processing and knowledge discovery [1]. Attribute reductions
have various approaches, especially on classification tasks and learning [2, 3, 4, 5, 6, 7, 8, 9]. Attribute reductions
have become a fundamental research topic, and they are extensively applied in multiple fields such as formal concept
analysis [10, 11, 12].
Rough set theory explores data reasoning, and thus it relies on decision systems with data representations. Tra-
ditionally, attribute values of samples are single-valued, so single-valued decision systems (SVDSs) are mainly em-
ployed to multiple generic environments [13, 14, 15, 16, 17]. In practical scenarios, attribute values are often uncer-
tain or fuzzy, so they can exhibit interval-based forms. Accordingly, Yao [18] introduced interval sets, and relevant
concepts based on interval sets (including interval-set information tables (ISITs) and interval-set decision systems
(ISDSs) [19]) gained continuous research. For example, Zhong and Huang [20] analyzed granulation structures of
interval sets from measure and set; Lin et al. [21] introduced the conjunction form and dominance relation in ISITs;
Li et al. [22] discussed the concept representation and rule induction in incomplete ISITs; Wang [23] gave the fuzzy
∗
Corresponding author
Email addresses: 702374273@qq.com (Xin Xie), xianyongzh@sina.com.cn (Xianyong Zhang )
Preprint submitted to International Journal of Approximate Reasoning May 5, 2024


剩余28页未读,继续阅读
资源评论


谢大虾
- 粉丝: 42
- 资源: 5









最新资源
- 提升工程效率的必备工具:IPAddressApp-无显示器远程调试的新选择
- 山东理工大学2024 离散数学思维导图
- IOS面试常问的问题及回答
- 船只检测13-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord、VOC数据集合集.rar
- 51单片机的温度监测与控制(温控风扇)
- 一个冒险者开发(只开发了底层)
- 船只检测10-TOD-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord、VOC数据集合集.rar
- 基于Web的智慧城市实验室主页系统设计与实现+vue(源码).rar
- InCode AI IDE
- triton-2.1.0-cp311-cp311-win-amd64.whl
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


