大数据-Inceptor技术白皮书.pdf

需积分: 0 112 浏览量
更新于2022-12-24
收藏 907KB PDF 举报
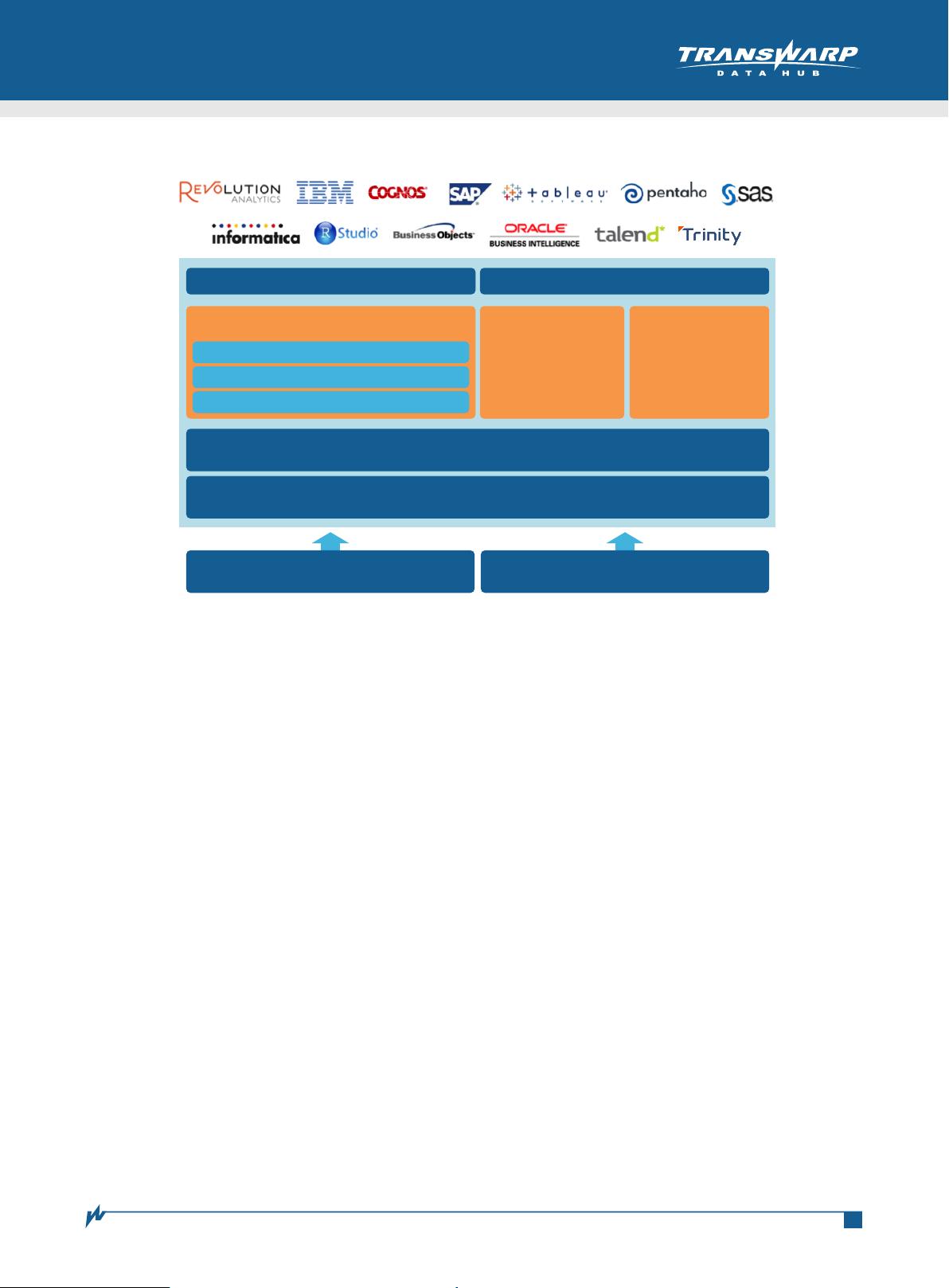
ྒߌྐ༏॓čഈݚĎႵཋ܄ඳ Transwarp Inceptor ඌϢ 2014 TRANSWARP 星环科技 Hadoop由HDFS和Map/Reduce组成。HDFS仍然是一个高可扩展的分布式文件系统,是大数据软件栈的基 石。Map/Reduce在处理PB级别的数据时,仍然具有高容错性、高吞吐量的特点。但由于复杂的工作流通常需 要多个阶段的Map/Reduce任务,而Map/Reduce的输入输出必须经过低速磁盘,导致运行复杂迭代任务时非常 低效,因此不适合对延时要求高的交互式分析或者需要复杂迭代的数据分析任务。而Spark是一个基于内存计算 的开源集群计算系统,目的是更快速地进行数据分析。 Spark 提供了与Hadoop Map/Reduce 相似的分布式计 算框架,但却有基于内存和迭代优化的设计,因此在交互式数据分析和数据挖掘工作负载中表现更优秀。 随着对大数据技术研究的深入,Spark开源生态系统得到了快速发展,已成为大数据领域最活跃的开源项目 之一。Spark之所以吸引如此多的关注,究其原因主要是因为Spark具有以下三方面特征: 虽然Spark具有以上三大优点,但从目前Spark的发展和应用现状来看,Spark自身也存在很多缺陷,主要 包括以下几个方面: 因此,尽管Spark正活跃在众多大数据公司的技术体系中,但是如果Spark本身的这些缺陷得不到及时处理, 将会严重影响Spark的普及和发展。星环科技有针对性的开发,推出了一系列关于Spark的大数据平台技术方案, 这些难题便迎刃而解。 星环科技推出的基于Spark的交互式分析引擎Inceptor,从下往上分三层架构,最底层是分布式缓存( Transwarp Holodesk),可建在内存或者SSD上;中间层是Apache Spark计算引擎层;最上层包括SQL 2003 和PL/SQL编译器、统计算法库和机器学习算法库,提供完整的R语言访问接口。 高性能:Spark对分布的数据集进行抽象,创新地提出RDD(Resilient Distributed Dataset)的概念,所有的统 计分析任务被翻译成对RDD的若干基本操作组成的有向无环图(DAG)。RDD可以被驻留在内存中,后续的任 务可以直接读取内存中的数据;同时分析DAG中任务之间的依赖性可以把相邻的任务合并,从而减少了大量 的中间结果输出,极大减少了磁盘I/O,使得复杂数据分析任务更高效。从这个意义上来说,如果任务够复杂, 迭代次数够多,Spark比Map/Reduce快一到两个数量级。 高灵活性:Spark是一个灵活的计算框架,适合做批处理、工作流、交互式分析、迭代式机器学习、流处理等 不同类型的应用,因此Spark可以成为一个用途广泛的计算引擎,并在未来取代Map/Reduce的地位。 与Hadoop生态完美融合:Spark可以与Hadoop生态系统的很多组件互操作。Spark可以运行在新一代资源管 理框架YARN上,它还可以读取已有的存放在Hadoop上的数据,这是个非常大的优势。 稳定性:由于代码质量问题,Spark长时间运行会经常出错,在架构方面,由于大量数据被缓存在内存中, Java垃圾回收缓慢的现象严重,导致Spark的性能不稳定,在复杂场景SQL的性能甚至不如现有Map/Reduce。 不能处理大数据:单台机器处理数据过大,或者由于数据倾斜导致中间结果超过内存大小时,常常出现内存 不够或者无法运行得出结果。但是Map/Reduce计算框架却可以处理大数据,因此在这方面Spark不如Map/Reduce 有效。 不支持复杂的SQL统计:目前Spark支持的SQL语法的完整程度还不能应用在复杂数据分析中。在可管理性 方面,Spark与YARN的结合不完善,这就在用户使用过程中埋下隐患,易出现各种难题。 基于Spark的交互式分析引擎 技术解析 基于Spark的交互式分析引擎技术解析 2014 TRANSWARP 星环科技 Transwarp Inceptor对Spark进行了大量的改进,具有高性能、稳定性好、功能丰富、易管理等特征,可以 切实解决Spark本身存在的难题。具体而言,星环Inceptor具有以下几点优势: 高性能 首先,支持高性能Apache Spark作为缺省执行引擎,可比原生的Hadoop Map/Reduce快;其次,通过建立 独立于Spark的分布式列式缓存层,可以有效防止GC的影响,消除Spark的性能波动,同时在列式缓存上实现 索引机制,进一步提高了执行性能;再次,在SQL执行计划优化方面,实现了基于代价的优化器(cost based optimizer)以及多种优化策略,性能可以比原生Spark快数倍;最后通过全新的方法解决数据倾斜或者数据量过 大的问题
《大数据-Inceptor技术白皮书》探讨了大数据分析领域中Hadoop、Spark及星环科技Inceptor的关键技术和挑战。文章指出,Hadoop的核心组件HDFS提供了高可扩展性的分布式存储,而Map/Reduce则以其高容错性和吞吐量处理大规模数据。然而,Map/Reduce在处理需要多阶段迭代的任务时效率低下,不适合交互式分析。
Spark作为内存计算的集群计算系统,因其内存优化和迭代计算特性,在交互式分析和数据挖掘中表现出色。Spark的三大特点包括:内存计算加速、处理多样化的计算任务和与Hadoop生态系统的良好集成。但Spark也存在一些缺陷,如长时间运行的稳定性问题、内存管理导致的性能波动、对大数据处理能力的局限以及对复杂SQL支持的不足。
针对Spark的局限,星环科技推出了Inceptor,一个基于Spark的交互式分析引擎。Inceptor采用三层架构,包括分布式缓存层(Transwarp Holodesk)、Apache Spark计算层和丰富的功能层,支持SQL和R语言接口。Inceptor针对Spark的性能问题进行了优化,如通过独立的列式缓存层减少GC影响,实现索引以提升查询速度,使用代价优化器优化SQL执行计划,以及解决了数据倾斜和大数据处理问题,确保了更高效的性能。
此外,Inceptor的高灵活性让它能够适应批处理、工作流、交互式分析等多种应用场景,且与YARN的兼容性提升了其在Hadoop生态系统中的实用性。星环科技的这一创新解决方案不仅提升了大数据分析的速度,还增强了系统的稳定性和可管理性,为大数据分析提供了更全面的解决方案。通过Inceptor,星环科技成功地解决了Spark的痛点,推动了大数据分析技术的发展和应用。

2022-12-24 上传
131 浏览量
181 浏览量
2022-12-24 上传
147 浏览量
113 浏览量
172 浏览量
161 浏览量
2022-06-21 上传
2019-01-07 上传
128 浏览量
2022-01-24 上传
148 浏览量
201 浏览量
2021-10-19 上传
2021-09-29 上传
2021-10-14 上传
2018-06-14 上传
160 浏览量
121 浏览量
105 浏览量
资源评论


是空空呀
- 粉丝: 196
- 资源: 3万+









最新资源
- 搜广推推荐系统中传统推荐系统方法思维导图整理-完整版
- 微藻检测19-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 使用AS的自定义功能块与OS之间WINCC自定义功能块图标,自定义功能块面板教程 1.不是采用西门子APL面板实现 2.AS可以采用LAD或者SCL语言生成功能块 3.实现弹窗功能 4.事件可
- 等发达地区的无穷大无穷大无穷大请问
- Python实现常见排序算法详解
- JWaaaaaaaaaaaaaaaaaaaa
- Python复制重复数据工具.exe
- 2024圣诞节海外消费市场趋势及营销策略分析报告
- 基于Java的网上教务评教管理系统的设计与实现.doc
- EventHandlerError解决办法.md
- NotImplementedError.md
- SecurityException(解决方案).md
- IllegalAccessException(解决方案).md
- NameError.md
- NSRunLoopError如何解决.md
- OSError.md
