Re-Reading提升大型语言模型推理能力

需积分: 0 144 浏览量
更新于2024-09-20
收藏 2.42MB PDF 举报
内容概要:介绍了RE2方法,即通过对问题进行两次阅读来增强大型语言模型(LLMs)的推理能力。与传统链思考(CoT)不同,RE2通过改进输入问题的理解提升了模型的整体表现,在多个数据集上进行了验证并展示了良好的通用性和兼容性。相较于普通CoT提示方式,实验结果显示重新读取问题的形式明显增强了模型对任务的理解关注。
适用人群:从事自然语言处理或大型语言模型研究人员。
使用场景及目标:提高各种推理性能评估中LLM的能力。如数学推理任务、文本理解和复杂多步推理等场景,通过简单有效的提示方法来优化模型的推理准确率。
其他说明:RE2不仅能独立改善模型的表现,还能与现有的多种LLM改进策略相结合使用,提供了丰富的应用可能性。

Re-Reading Improves Reasoning in Large Language Models
Xiaohan Xu
1
*
, Chongyang Tao
2
, Tao Shen
3
, Can Xu
2
,
Hongbo Xu
1
, Guodong Long
3
, Jian-guang Lou
2
1
Institute of Information Engineering, CAS, {xuxiaohan,hbxu}@iie.ac.cn
2
Microsoft Corporation, {chotao,caxu,jlou}@microsoft.com
3
AAII, School of CS, FEIT, UTS, {tao.shen,guodong.long}@uts.edu.au
Abstract
To enhance the reasoning capabilities of off-
the-shelf Large Language Models (LLMs),
we introduce a simple, yet general and effec-
tive prompting method, RE2, i.e., Re-Reading
the question as input. Unlike most thought-
eliciting prompting methods, such as Chain-of-
Thought (CoT), which aim to elicit the reason-
ing process in the output, RE2 shifts the fo-
cus to the input by processing questions twice,
thereby enhancing the understanding process.
Consequently, RE2 demonstrates strong gen-
erality and compatibility with most thought-
eliciting prompting methods, including CoT.
Crucially, RE2 facilitates a "bidirectional" en-
coding in unidirectional decoder-only LLMs
because the first pass could provide global in-
formation for the second pass. We begin with
a preliminary empirical study as the founda-
tion of RE2, illustrating its potential to enable
"bidirectional" attention mechanisms. We then
evaluate RE2 on extensive reasoning bench-
marks across 14 datasets, spanning 112 exper-
iments, to validate its effectiveness and gener-
ality. Our findings indicate that, with the ex-
ception of a few scenarios on vanilla ChatGPT,
RE2 consistently enhances the reasoning per-
formance of LLMs through a simple re-reading
strategy. Further analyses reveal RE2’s adapt-
ability, showing how it can be effectively inte-
grated with different LLMs, thought-eliciting
prompting, and ensemble strategies.
1
1 Introduction
In the ever-evolving landscape of artificial in-
telligence, large language models (LLMs) have
emerged as a cornerstone of natural language un-
derstanding and generation (Brown et al., 2020;
Touvron et al., 2023a,a; OpenAI, 2023). As these
LLMs have grown in capability, a pivotal challenge
has come to the forefront: imbuing them with the
*
This work was done during internship at Microsoft.
1
Our code is available at
https://github.com/Tebmer/
Rereading-LLM-Reasoning/
Input
CoT
Input
CoT+RE2
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis
balls. Each can has 3 tennis balls. How many tennis balls
does he have now?
A: Let’s think step by step.
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis
balls. Each can has 3 tennis balls. How many tennis balls
does he have now?
Read the question again: Roger has 5 tennis balls. He buys 2
more cans of tennis balls. Each can has 3 tennis balls. How
many tennis balls does he have now?
A: Let’s think step by step.
Figure 1: Example inputs of CoT prompting versus
CoT prompting with RE2. RE2 is a simple prompting
method that repeats the question as input. Typically,
tokens in the question, such as "tennis balls", cannot
see subsequent tokens in the original setup for LLMs
(the top figure). In contrast, LLMs with RE2 allows
"tennis balls" in the second pass to see the entire ques-
tion containing "How many ...", achieving an effect of a
"bidirectional" understanding (the bottom figure).
ability to reason effectively. The capacity to engage
in sound reasoning is a hallmark of human intelli-
gence, enabling us to infer, deduce, and solve prob-
lems. In LLMs, this skill is paramount for enhanc-
ing their practical utility. Despite their remarkable
capabilities, LLMs often struggle with nuanced rea-
soning (Blair-Stanek et al., 2023; Arkoudas, 2023),
prompting researchers to explore innovative strate-
gies to bolster their reasoning prowess (Wei et al.,
2022b; Gao et al., 2023; Besta et al., 2023).
Existing research on reasoning has predomi-
nantly concentrated on designing diverse thought-
eliciting prompting strategies to elicit reasoning
processes in the output phase, such as Chain-
of-Thought (CoT) (Wei et al., 2022b), Program-
Aided Language Model (PAL) (Gao et al., 2023),
etc. (Yao et al., 2023a; Besta et al., 2023; Wang
et al., 2023a). In contrast, scant attention has been
arXiv:2309.06275v2 [cs.CL] 29 Feb 2024



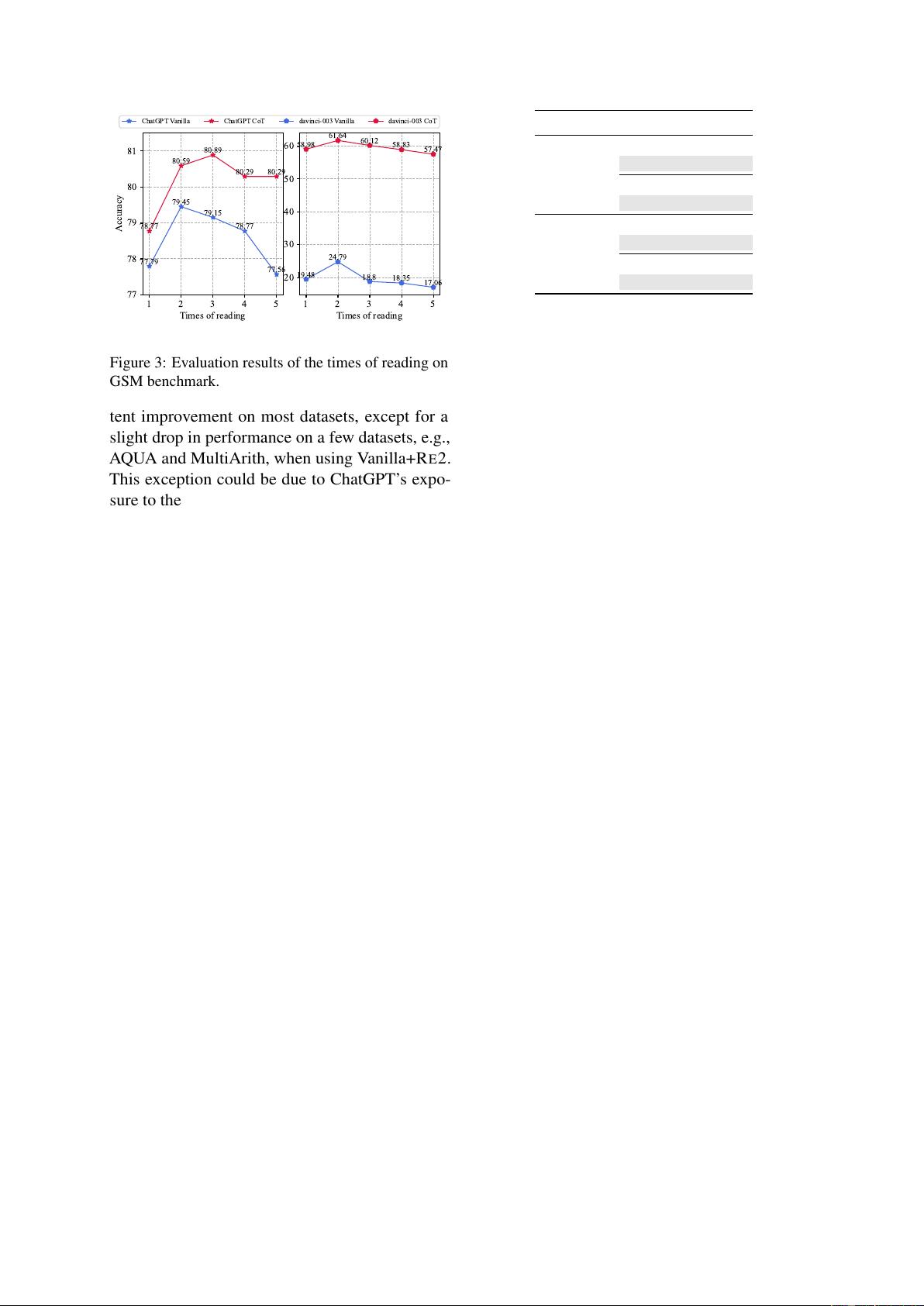
剩余24页未读,继续阅读
197 浏览量
192 浏览量
158 浏览量
113 浏览量
2005-12-13 上传
170 浏览量
2021-09-16 上传
187 浏览量
2022-05-26 上传
t-l-51729-little-red-riding-hood-traditional-tales-differentiated-reading-comprehension-activity.pdf
2021-07-25 上传
2021-11-15 上传
2019-09-25 上传
196 浏览量
2019-10-10 上传
2022-09-21 上传
2022-09-19 上传
191 浏览量
192 浏览量
2023-03-27 上传
2021-10-27 上传
168 浏览量
154 浏览量
2023-10-06 上传
187 浏览量
资源评论


豪AI冰
- 粉丝: 73
- 资源: 68









最新资源
- 基于javaswing的可视化学生信息管理系统
- 车辆、人检测14-TFRecord数据集合集.rar
- 车辆、人员、标志检测26-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 一款完全免费的屏幕水印工具
- 基于PLC的空调控制原理图
- 基于VUE的短视频推荐系统
- Windows环境下Hadoop安装配置与端口管理指南
- 起重机和汽车检测17-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord、VOC数据集合集.rar
- XAMPP 是一个免费且易于安装的Apache发行版
- 汽车软件需求开发与管理-从需求分析到实现的全流程解析
