GPipe:大规模模型并行训练的有效解决方案

需积分: 0 9 浏览量
更新于2024-09-14
收藏 527KB PDF 举报
本文介绍了GPipe——一种利用微批次管道并行性实现大型神经网络高效扩展的库。GPipe支持将任意深度神经网络分解成层序列并在不同加速器上执行。它引入了一种新颖的管道并行算法和批量分割方法,可以在多设备环境下同步梯度更新,使得硬件利用率高同时保持训练稳定性。文中展示了GPipe应用在图像分类与多语言神经机器翻译领域的成功实验效果,证实了GPipe的强大性能以及其灵活性。不论是对于研究人员还是工程实践者来说,都能有效提高深层模型特别是巨型规模下计算任务的工作效率。
适合人群:专注于神经网络研究的研究人员,需要大规模模型的应用团队成员。
使用场景及目标:适用于需要突破单一加速器内存限制,构建更大更复杂的机器学习模型的情景,特别是希望借助GPU集群或其他加速设备来扩展训练能力的专业人士。目标是在有限的硬件条件下最大程度优化神经网络的容量。
其他说明:相比现有的一些解决方案如SPMD、Pipeline等方式,GPipe提供更广泛的任务适应性和更低通信开销。然而需要注意当前版本假设每个单层仍然符合单个加速卡的显存配置。

GPipe: Easy Scaling with Micro-Batch Pipeline
Parallelism
Yanping Huang
huangyp@google.com
Youlong Cheng
ylc@google.com
Ankur Bapna
ankurbpn@google.com
Orhan Firat
orhanf@google.com
Mia Xu Chen
miachen@google.com
Dehao Chen
dehao@google.com
HyoukJoong Lee
hyouklee@google.com
Jiquan Ngiam
jngiam@google.com
Quoc V. Le
qvl@google.com
Yonghui Wu
yonghui@google.com
Zhifeng Chen
zhifengc@google.com
Abstract
Scaling up deep neural network capacity has been known as an effective approach
to improving model quality for several different machine learning tasks. In many
cases, increasing model capacity beyond the memory limit of a single accelera-
tor has required developing special algorithms or infrastructure. These solutions
are often architecture-specific and do not transfer to other tasks. To address the
need for efficient and task-independent model parallelism, we introduce GPipe, a
pipeline parallelism library that allows scaling any network that can be expressed
as a sequence of layers. By pipelining different sub-sequences of layers on sep-
arate accelerators, GPipe provides the flexibility of scaling a variety of different
networks to gigantic sizes efficiently. Moreover, GPipe utilizes a novel batch-
splitting pipelining algorithm, resulting in almost linear speedup when a model
is partitioned across multiple accelerators. We demonstrate the advantages of
GPipe by training large-scale neural networks on two different tasks with distinct
network architectures: (i) Image Classification: We train a 557-million-parameter
AmoebaNet model and attain a top-1 accuracy of 84.4% on ImageNet-2012, (ii)
Multilingual Neural Machine Translation: We train a single 6-billion-parameter,
128-layer Transformer model on a corpus spanning over 100 languages and achieve
better quality than all bilingual models.
1 Introduction
Deep learning has seen great progress over the last decade, partially thanks to the development of
methods that have facilitated scaling the effective capacity of neural networks. This trend has been
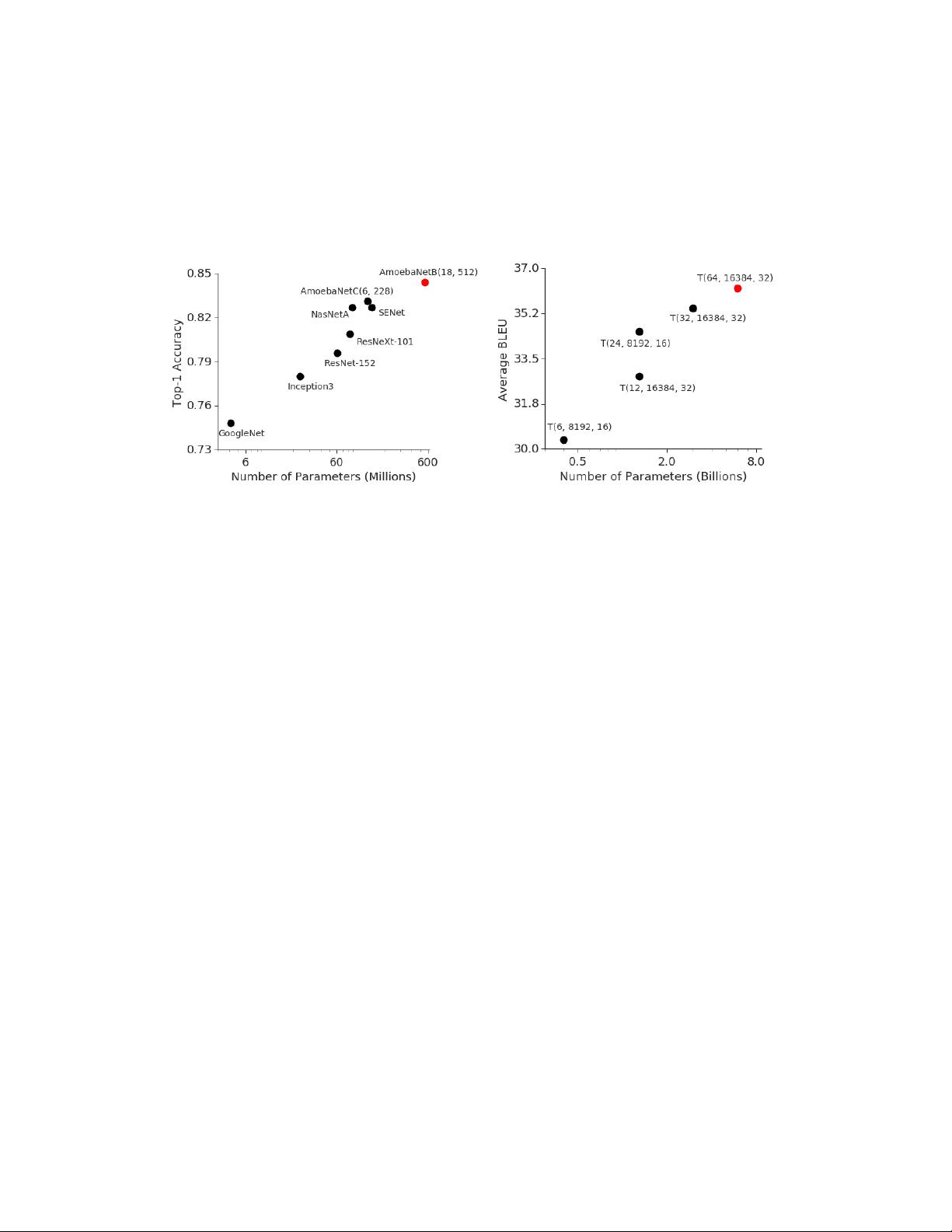
most visible for image classification, as demonstrated by the accuracy improvements on ImageNet
with the increase in model capacity (Figure 1a). A similar phenomenon can also be observed in
the context of natural language processing (Figure 1b) where simple shallow models of sentence
representations [1, 2] are outperformed by their deeper and larger counterparts [3, 4].
While larger models have brought remarkable quality improvements to several fields, scaling neural
networks introduces significant practical challenges. Hardware constraints, including memory
limitations and communication bandwidths on accelerators (GPU or TPU), force users to divide larger
Preprint. Under review.
arXiv:1811.06965v5 [cs.CV] 25 Jul 2019

剩余10页未读,继续阅读
2019-09-25 上传
139 浏览量
2023-11-16 上传
148 浏览量
2022-03-18 上传
2022-03-18 上传
151 浏览量
2023-05-28 上传
170 浏览量
2023-10-18 上传
156 浏览量
2021-09-26 上传
2022-03-18 上传
133 浏览量
139 浏览量
107 浏览量
193 浏览量
2008-11-04 上传
161 浏览量
109 浏览量
103 浏览量
158 浏览量
146 浏览量
资源评论











