### 计算机视觉深度学习入门五讲:结构篇
#### 概述
《计算机视觉深度学习入门五讲:结构篇》旨在为读者提供一份深入浅出的学习资料,重点介绍计算机视觉领域中深度学习模型的基本架构及其应用。通过本篇的学习,读者能够理解并掌握常用的卷积神经网络(CNN)模型的构建方式以及这些模型如何应用于解决实际问题。
#### CNN模型的结构
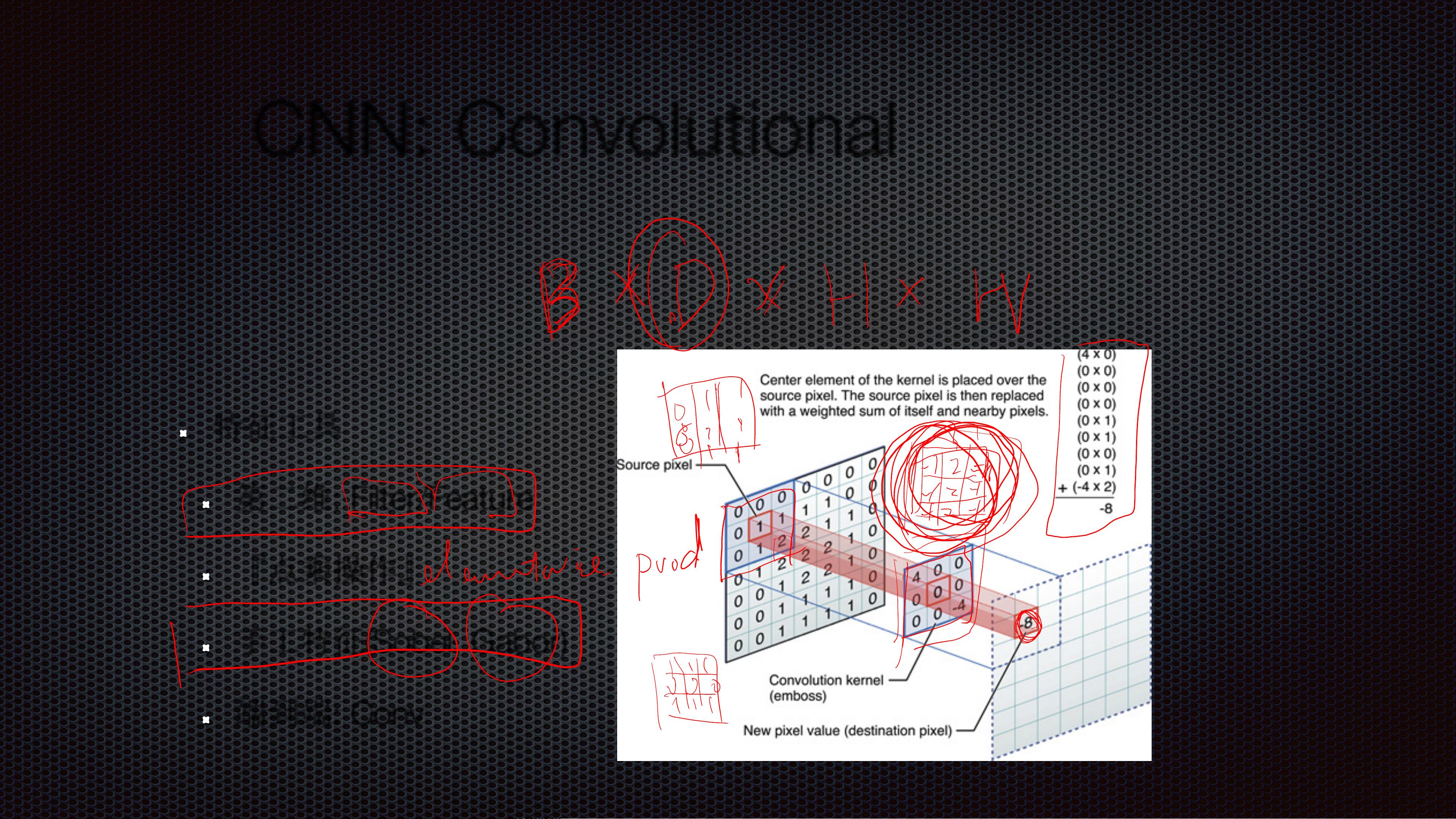
卷积神经网络(Convolutional Neural Network,简称CNN)是目前计算机视觉领域中最常用的一种深度学习模型。其基本结构通常包括输入层、卷积层、池化层、全连接层以及输出层等几大部分。其中卷积层和池化层是CNN特有的结构,它们的设计目的是为了更好地提取图像中的局部特征并减少计算复杂度。
- **可微/可BP部分:Backbones**:Backbones是指CNN模型中的主干网络部分,这部分通常由多个卷积层和池化层组成,负责从原始图像中提取高层次的特征表示。
- **额外部分:针对问题,特征向量重新加工**:这部分涉及如何根据具体任务需求对提取到的特征进行进一步的加工处理,例如使用特定的层来实现特征融合或调整特征维度等。
#### 机器学习论文的结构
- **目的**:明确研究的目标是什么,希望通过该研究解决哪些问题。
- **结构**:详细描述模型的架构,包括各个组成部分及其之间的连接方式。
- **优化**:介绍模型训练过程中所采用的优化策略,如损失函数的选择、正则化方法等。
- **数据**:阐述实验使用的数据集,包括数据预处理步骤等。
#### 特征的组织与重构
- **Conv(3,3)**:表示使用大小为3×3的卷积核进行卷积操作,这是最常见的一种卷积操作类型。
- **Conv(1,1)**:表示使用大小为1×1的卷积核进行卷积操作,主要用于改变输入特征图的通道数而不会改变其空间尺寸。
- **Conv(1,N)**:一般用于一维卷积,这里N表示卷积核的长度。
#### 模型的简与繁
- **BlocksAndUnits**:模型通常由多个重复的模块或单元构成,这些模块和单元的复杂程度决定了整个模型的深度和宽度。常见的单元包括但不限于Residual Unit、Inception Unit等。
#### 特征融合
特征融合是指将不同来源或不同层级的特征结合起来,以增强模型的表现能力。常用的方法有:
- **分组**:通过将特征图分成不同的组别来进行处理,可以有效减少参数数量同时保持较高的准确性。
- **加法**:直接将两个特征相加以融合信息。
- **乘法**:通过元素级别的乘法来融合特征。
- **拼接**:将多个特征图沿某一维度拼接起来形成新的特征表示。
- **二阶**:利用二阶统计量来融合特征。
#### CNN压缩
CNN模型通常包含大量的参数,这不仅增加了计算成本也使得模型难以部署到资源受限的设备上。因此,研究者们提出了多种压缩技术,如:
- **FP32, FP16, INT8**:分别代表了浮点数精度为32位、16位以及整数精度为8位的数据类型。通过降低数据精度可以显著减少模型的内存占用。
- **其他粗粒度**:除了精度降低之外,还有其他一些压缩技术,比如剪枝、量化、低秩分解等。
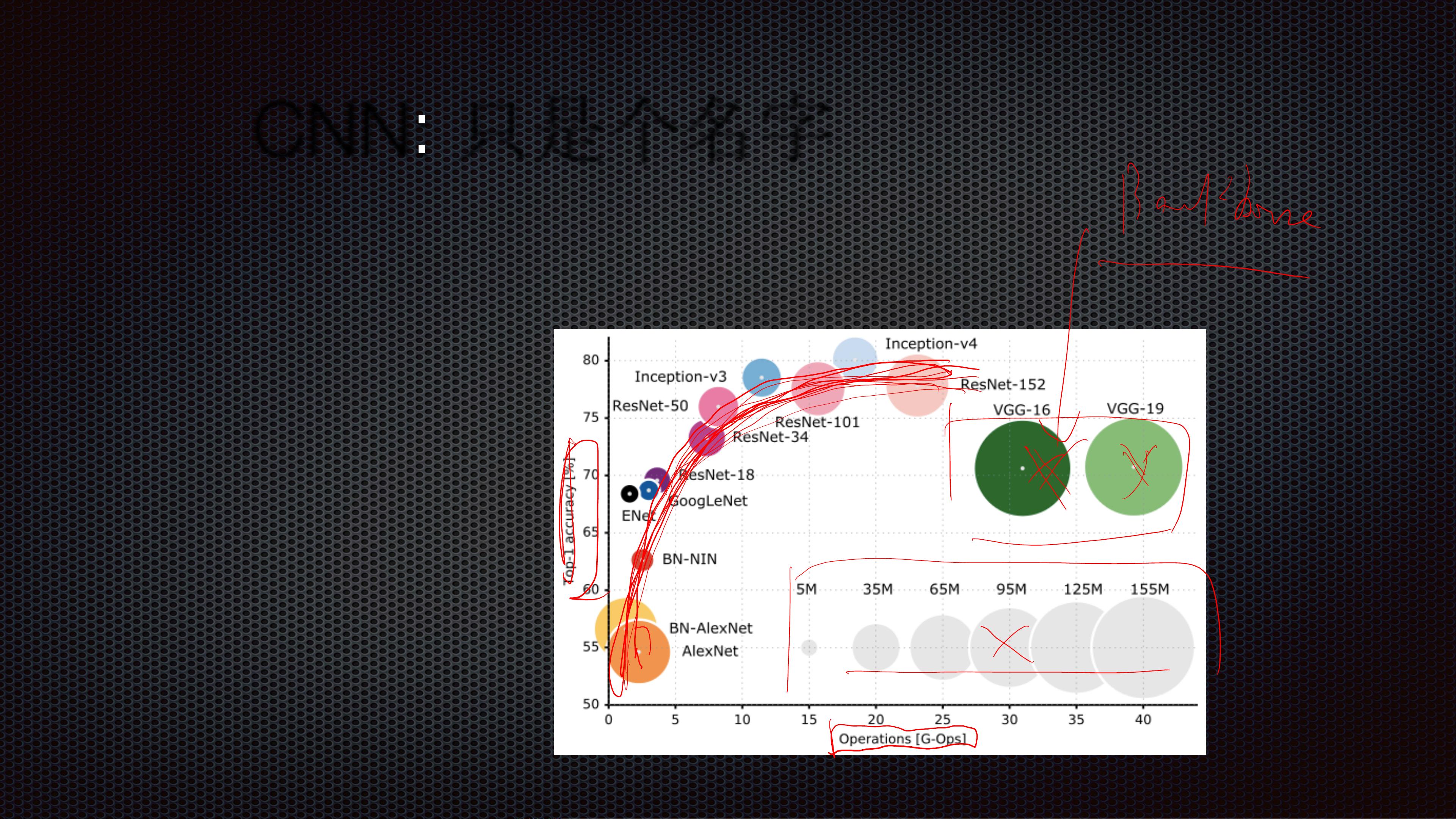
#### CNN模型的发展
- **AlexNet, VGG, LeNet, GoogLeNet**:这些都是早期非常经典的CNN模型,在当时的图像分类任务中取得了突破性的进展。
- **Inception Series**:以InceptionV3为代表的一系列模型采用了多尺度卷积和残差连接等技术,显著提高了模型的性能。
- **ResNet Series**:ResNet通过引入残差连接解决了深层网络训练时的梯度消失问题,使得构建更深的网络成为可能。
- **DenseNet**:通过密集连接的方式最大化特征重用,从而减少了参数数量同时保持了较高的准确率。
- **Dual Path Network**:结合了ResNet和DenseNet的优点,能够在不同路径之间共享信息。
- **Squeeze and Excitation**:在ResNet的基础上加入了注意力机制,提高了模型对关键特征的关注度。
- **Spatial Weighted Pooling**:多池化方法,通过在不同位置设置权重来提高模型的泛化能力。
#### CNN:Deeper/Wider
随着模型深度和宽度的增加,研究者们发现更深层次的网络能够获得更好的性能。但同时也会带来训练难度增大的问题,为此出现了多种解决方案:
- **Residual Networks Behave Like Ensembles of Relatively Shallow Networks**:研究表明,残差网络实际上可以看作是由许多较浅的子网络组成的集合,这有助于提高模型的鲁棒性和泛化能力。
- **On the Connection of Deep Fusion to Ensembling**:深入探讨了深层网络与模型集成之间的关系。
- **Wider or Deeper: Revisiting the ResNet Model for Visual Recognition**:分析了在视觉识别任务中增加网络宽度和深度的效果差异。
#### CNN:Binarization
- **Pooling与Activation的演化历程**:早期的CNN模型通常采用平均池化和sigmoid/tanh激活函数,后来逐渐发展为使用最大池化和ReLU激活函数。
- **AveragePooling+Sigmoid:高斯假设与梯度消失**:这种组合下的模型往往假设数据是多元高斯分布,并且容易出现梯度消失的问题。
- **MaxPooling+ReLu:非高斯假设与梯度爆炸**:相比于平均池化和sigmoid,这种方式更适合非高斯分布的数据,并能有效避免梯度消失问题,但也可能会遇到梯度爆炸的情况。
- **BatchNorm与Affine:肮脏的近似处理**:批量归一化(Batch Normalization)和仿射变换(Affine Transformation)都是为了加速模型训练过程中的收敛速度而设计的技术,尽管它们本质上是一种近似处理。
以上内容覆盖了《计算机视觉深度学习入门五讲:结构篇》的主要知识点,通过对这些内容的理解,可以帮助读者建立起对计算机视觉领域深度学习模型结构的基础认识,并为进一步深入学习打下坚实的基础。