

实验指导书
1.1 基于 Hadoop 的数据仓库 Hive 学习指南
1.2 实验环境
1.操作系统:CentOS6.6
2.已经安装好 Linux 操作系统,并安装配置了 Hadoop 环境,已经
安装好了 Hadoop 分布式文件系统
3.登录用户名:hadoop,密码:123456
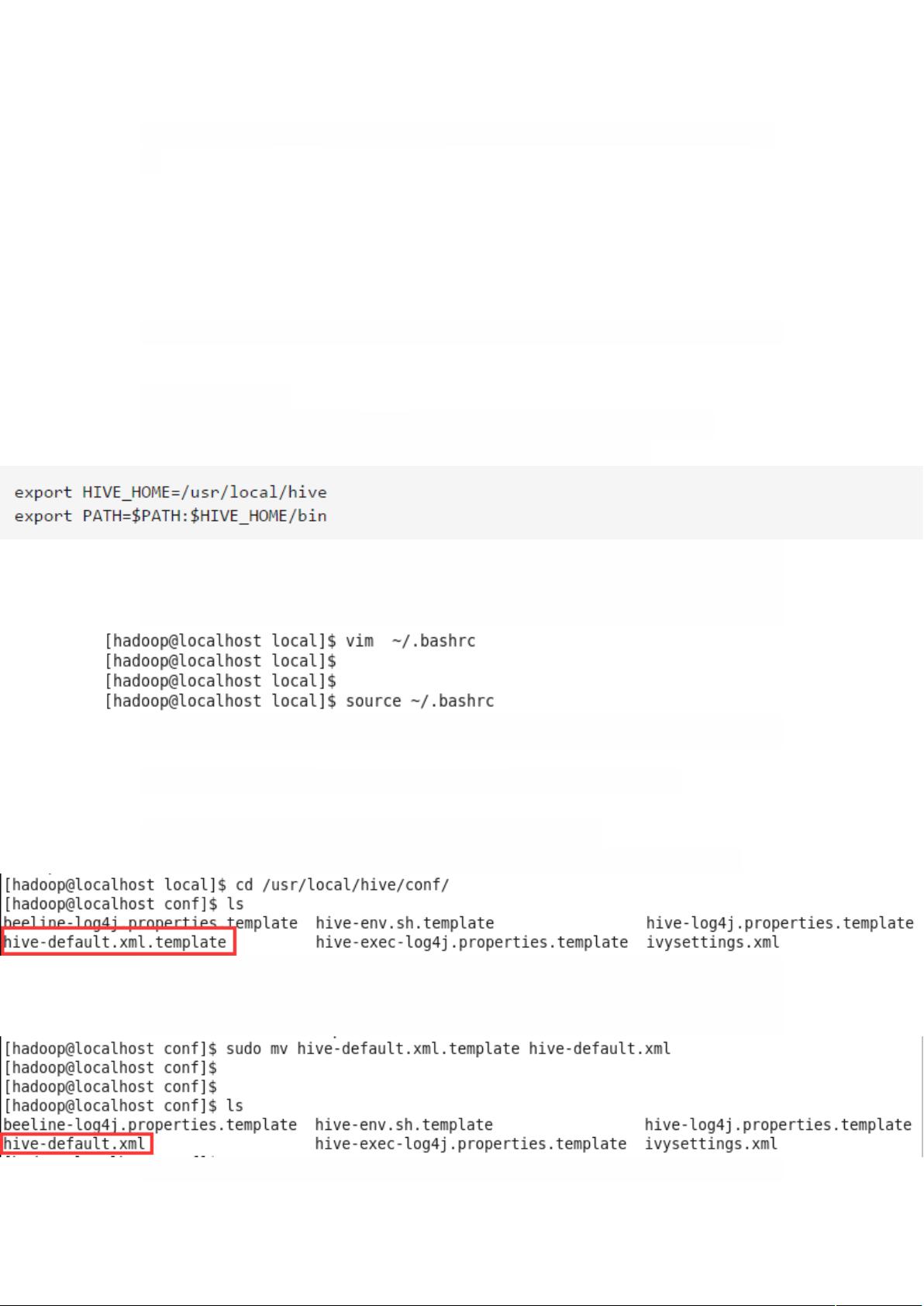
账户:root 密码:123456
桌面的 hive-site.txt 存放配置文件的内容
hive-command.txt 存放常用的 hive 命令
1.3 实验原理
1.通过实验掌握基本的 Hive 安装方法;
2.掌握用数据仓库 Hive 来解决一些常见的数据库操作以及简单的
Hive 编程。



剩余26页未读,继续阅读
资源评论


陈怂怂
- 粉丝: 82
- 资源: 1









最新资源
- 毕业设计-基于树莓派的寝室小监控系统全部资料+详细文档+高分项目+源码.zip
- 毕业设计-基于树莓派的人脸识别系统(调用百度云api)全部资料+详细文档+高分项目+源码.zip
- 毕业设计-基于微服务架构实现的智能招聘系统全部资料+详细文档+高分项目+源码.zip
- 毕业设计-基于微服务的商城秒杀系统全部资料+详细文档+高分项目+源码.zip
- 毕业设计-基于微信小程序的共享雨伞租借系统全部资料+详细文档+高分项目+源码.zip
- Delphi 12 控件之DevExpressUniversalTrialCompleteSetup-20241212-Downloadly.ir.rar
- 自动驾驶,AutoWareAuto框架全框架梳理思维导图及代码注释 授人以鱼不如授人以渔,涵盖:融合感知模块,定位模块,决策规划模块,控制模块,预测模块等较为详细的注释(并非每行都有注释)及框架梳理
- cb.zip
- 银行数字化转型程度-根据年报词频计算(2012-2021年).zip
- 基于labview的OneNET云平台数据写入与读取 可通过labview往云台设备写入 读取数据 也可通过手机app查看labview写入的数据,实现实时监控
- 动手学深度学习,沐神版配套代码,所有代码均可在jupyter中运行,内附有极为详尽的代码注释
- abp使用微服务代码示例
- 地热模拟软件OGS手册的中文翻译中英对照版
- python读取西门子s7-300 plc数据,通过调用微信发送给微信联系人
- IMG_20241223_084327.jpg
- IMG_20241223_084327.jpg
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


