

Void: A fast and light voice liveness detection system
Muhammad Ejaz Ahmed
Data61, CSIRO
Sungkyunkwan University
Il-Youp Kwak
∗
Chung-Ang University
Jun Ho Huh
Samsung Research
Iljoo Kim
Samsung Research
Taekkyung Oh
KAIST
Sungkyunkwan University
Hyoungshick Kim
Sungkyunkwan University
Abstract
Due to the open nature of voice assistants’ input channels, ad-
versaries could easily record people’s use of voice commands,
and replay them to spoof voice assistants. To mitigate such
spoofing attacks, we present a highly efficient
vo
ice l
i
veness
d
etection solution called “Void.” Void detects voice spoof-
ing attacks using the differences in spectral power between
live-human voices and voices replayed through speakers. In
contrast to existing approaches that use multiple deep learn-
ing models, and thousands of features, Void uses a single
classification model with just 97 features.
We used two datasets to evaluate its performance: (1)
255,173 voice samples generated with 120 participants, 15
playback devices and 12 recording devices, and (2) 18,030
publicly available voice samples generated with 42 partici-
pants, 26 playback devices and 25 recording devices. Void
achieves equal error rate of 0.3% and 11.6% in detecting voice
replay attacks for each dataset, respectively. Compared to a
state of the art, deep learning-based solution that achieves
7.4% error rate in that public dataset, Void uses 153 times
less memory and is about 8 times faster in detection. When
combined with a Gaussian Mixture Model that uses Mel-
frequency cepstral coefficients (MFCC) as classification fea-
tures – MFCC is already being extracted and used as the main
feature in speech recognition services – Void achieves 8.7%
error rate on the public dataset. Moreover, Void is resilient
against hidden voice command, inaudible voice command,
voice synthesis, equalization manipulation attacks, and com-
bining replay attacks with live-human voices achieving about
99.7%, 100%, 90.2%, 86.3%, and 98.2% detection rates for
those attacks, respectively.
1 Introduction
Popular voice assistants like Siri (Apple), Alexa (Amazon)
and Now (Google) allow people to use voice commands to
∗
Part of this work done while Dr. Kwak was at Samsung Research.
quickly shop online, make phone calls, send messages, con-
trol smart home appliances, access banking services, and so
on. However, such privacy- and security-critical commands
make voice assistants lucrative targets for attackers to exploit.
However, recent studies [11, 12, 23] demonstrated that voice
assistants are vulnerable to various forms of voice presenta-
tion attacks including “voice replay attacks” (attackers simply
record victims’ use of voice assistants and replay them) and
“voice synthesis attacks” (attackers train victims’ voice bio-
metric models and create new commands).
To distinguish between live-human voices and replayed
voices, several voice liveness detection techniques have been
proposed. Feng et al. [11] proposed the use of wearable de-
vices, such as eyeglasses, or earbuds to detect voice liveness.
They achieved about 97% detection rate but rely on the use
additional hardware that users would have to buy, carry, and
use. Deep learning-based approaches [7, 30] have also been
proposed. The best known solution from an online replay
attack detection competition called “2017 ASVspoof Chal-
lenge” [7] is highly accurate, achieving about 6.7% equal
error rate (EER) – but it is computationally expensive and
complex: two deep learning models (LCNN and CNN with
RNN) and one SVM-based classification model were all used
together to achieve high accuracy. The second best solution
achieved 12.3% EER using an ensemble of 5 different classifi-
cation models and multiple classification features: Constant Q
Cepstral Coefficients (CQCC), Perceptual Linear Prediction
(PLP), and Mel Frequency Cepstral Coefficients (MFCC) fea-
tures were all used. CQCC alone is heavy and would consist
of about 14,000 features.
To reduce computational burden and maintain high detec-
tion accuracy, we present “Void” (
Vo
ice l
i
veness
d
etection),
which is a highly efficient voice liveness detection system
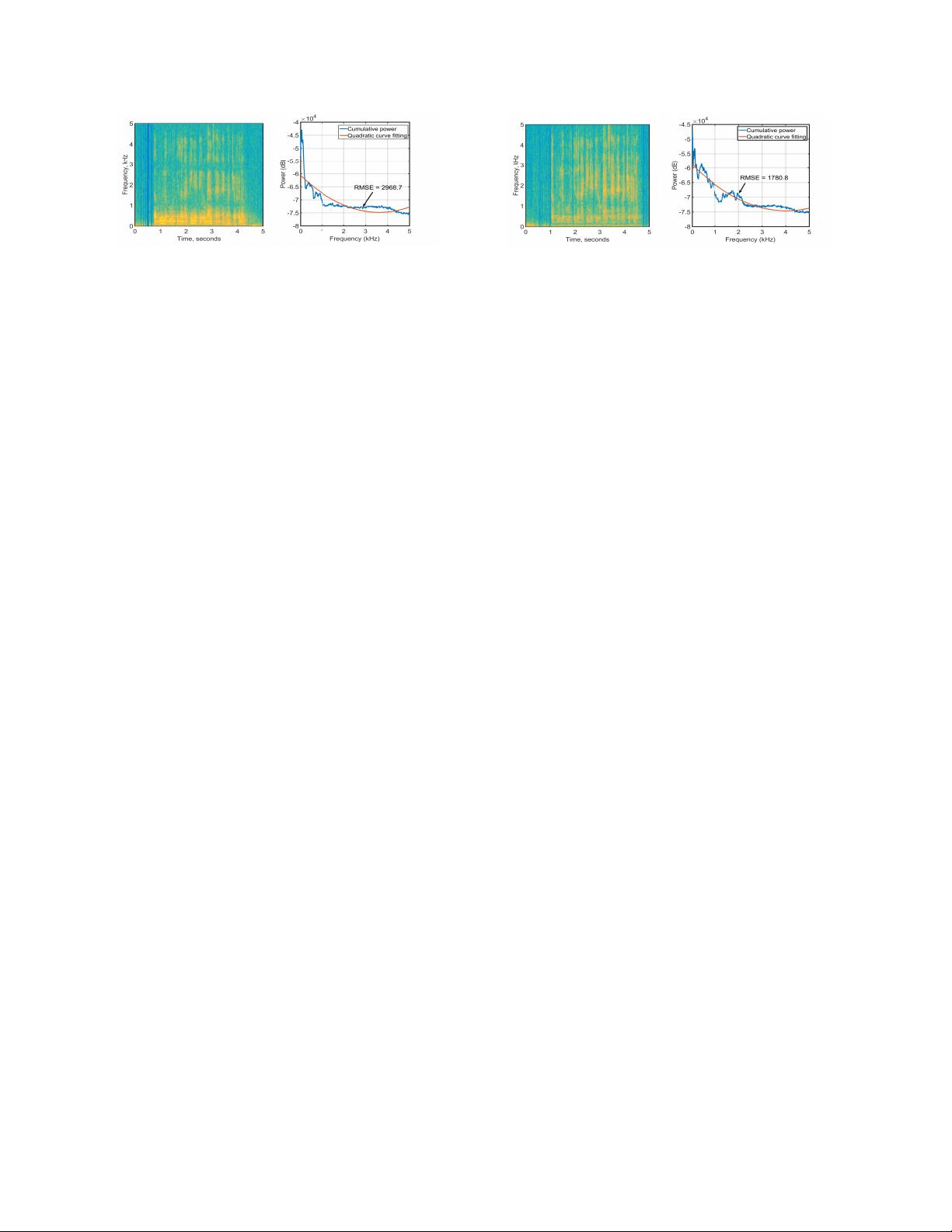
that relies on the analysis of cumulative power patterns in
spectrograms to detect replayed voices. Void uses a single
classification model with just 97 spectrogram features. In par-
ticular, Void exploits the following two distinguishing charac-
teristics in power patterns: (1) Most loudspeakers inherently
add distortions to original sounds while replaying them. In

剩余17页未读,继续阅读
资源评论


染阳
- 粉丝: 2099
- 资源: 6









最新资源
- 机械设计raun内外盒组装包装设备含工程图sw17可编辑非常好的设计图纸100%好用.zip
- 机械设计板式过滤设备sw14可编辑非常好的设计图纸100%好用.zip
- 机械设计UV光解+活性炭设备sw14可编辑非常好的设计图纸100%好用.zip
- 数据分析-08-B站美食视频图鉴 干饭人干饭魂干饭都是人上人(包含数据和代码)
- 机械设计阿密龙水炮模型sw12可编辑非常好的设计图纸100%好用.zip
- 机械设计宝马车悬架系统模型step非常好的设计图纸100%好用.zip
- xssaaaaaaaaaaaaa
- 婚庆摄影小程序ssm.zip
- 校园顺路代送微信小程序ssm.zip
- 微信小程序线上教育商城ssm.zip
- 基于微信小程序投票评选系统的设计与实现ssm.zip
- 基于微信小程序的二手物品交易平台ssm.zip
- 机械设计背板字体视觉检测设备 step非常好的设计图纸100%好用.zip
- 在线厨艺平台的设计与实现微信小程序ssm.zip
- 基于微信小程序的小区管理系统的设计ssm.zip
- 即时空教室查询小程序ssm.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


