### Download the model and place it in the models directory
- Link 1: https://github.com/mymagicpower/AIAS/releases/download/apps/denoiser.zip
- Link 2: https://github.com/mymagicpower/AIAS/releases/download/apps/speakerEncoder.zip
- Link 3: https://github.com/mymagicpower/AIAS/releases/download/apps/tacotron2.zip
- Link 4: https://github.com/mymagicpower/AIAS/releases/download/apps/waveGlow.zip
-
### TTS text to speech
Note: To prevent the cloning of someone else's voice for illegal purposes, the code limits the use of voice files to only those provided in the program.
Voice cloning refers to synthesizing audio that has the characteristics of the target speaker by using a specific voice, combining the pronunciation of the text with the speaker's voice.
When training a speech cloning model, the target voice is used as the input of the Speaker Encoder, and the model extracts the speaker's features (voice) as the Speaker Embedding.
Then, when training the model to resynthesize speech of this type, in addition to the input target text, the speaker's features will also be added as additional conditions to the model's training.
During prediction, a new target voice is selected as the input of the Speaker Encoder, and its speaker's features are extracted, finally realizing the input of text and target voice and generating a speech segment of the target voice speaking the text.
The Google team proposed a neural system for text-to-speech synthesis that can learn the speech features of multiple different speakers with only a small amount of samples, and synthesize their speech audio. In addition, for speakers that the network has not encountered during training, their speech can be synthesized with only a few seconds of unknown speaker audio without retraining, that is, the network has zero-shot learning ability.
Traditional natural speech synthesis systems require a large amount of high-quality samples during training, usually requiring hundreds or thousands of minutes of training data for each speaker, which makes the model generally not universal and cannot be widely used in complex environments (with many different speakers). These networks combine the processes of speech modeling and speech synthesis.
The SV2TTS work first separates these two processes and uses the first speech feature encoding network (encoder) to model the speaker's speech features, and then uses the second high-quality TTS network to convert features into speech.
- SV2TTS paper
[Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis](https://arxiv.org/pdf/1806.04558.pdf)
- Network structure

#### Mainly composed of three parts:
#### Sound feature encoder (speaker encoder)
Extract the speaker's voice feature information. Embed the speaker's voice into a fixed dimensional vector, which represents the speaker's potential voice features.
The encoder mainly embeds the reference speech signal into a vector space of fixed dimension, and uses it as supervision to enable the mapping network to generate original voice signals (Mel spectrograms) with the same features.
The key role of the encoder is similarity measurement. For different speeches of the same speaker, the vector distance (cosine angle) in the embedding vector space should be as small as possible, while for different speakers, it should be as large as possible.
In addition, the encoder should also have the ability to resist noise and robustness, and extract the potential voice feature information of the speaker's voice without being affected by the specific speech content and background noise.
These requirements are consistent with the requirements of the speech recognition model (speaker-discriminative), so transfer learning can be performed.
The encoder is mainly composed of three layers of LSTM, and the input is a 40-channel logarithmic Mel spectrogram. After the output of the last frame cell of the last layer is processed by L2 regularization, the embedding vector representation of the entire sequence is obtained.
In actual inference, any length of input speech signal will be divided into multiple segments by an 800ms window, and each segment will get an output. Finally, all outputs are averaged and superimposed to obtain the final embedding vector.
This method is very similar to the Short-Time Fourier Transform (STFT).
The generated embedding space vector is visualized as follows:
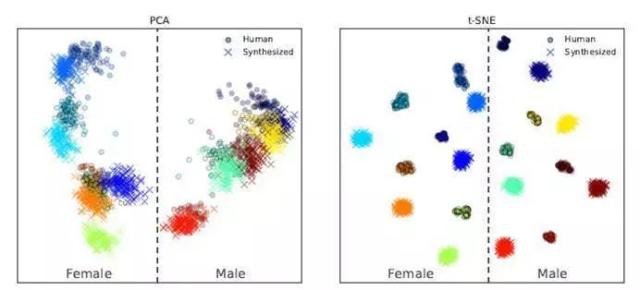
It can be seen that different speakers correspond to different clustering ranges in the embedding space, which can be easily distinguished, and speakers of different genders are located on both sides.
(However, synthesized speech and real speech are also easy to distinguish, and synthesized speech is farther away from the clustering center. This indicates that the realism of synthesized speech is not enough.)
####Sequence-to-sequence mapping synthesis network (Tacotron 2)
Based on the Tacotron 2 mapping network, the vector obtained from the text and sound feature encoder is used to generate a logarithmic Mel spectrogram.
The Mel spectrogram takes the logarithm of the spectral frequency scale Hz and converts it to the Mel scale, so that the sensitivity of the human ear to sound is linearly positively correlated with the Mel scale.
This network is trained independently of the encoder network. The audio signal and the corresponding text are used as inputs. The audio signal is first feature-extracted by a pre-trained encoder, and then used as input to the attention layer.
The network output feature consists of a sequence of length 50ms and a step size of 12.5ms. After Mel scaling filtering and logarithmic dynamic range compression, the Mel spectrogram is obtained.
In order to reduce the influence of noisy data, L1 regularization is additionally added to the loss function of this part.
The comparison of the input Mel spectrogram and the synthesized spectrogram is shown below:
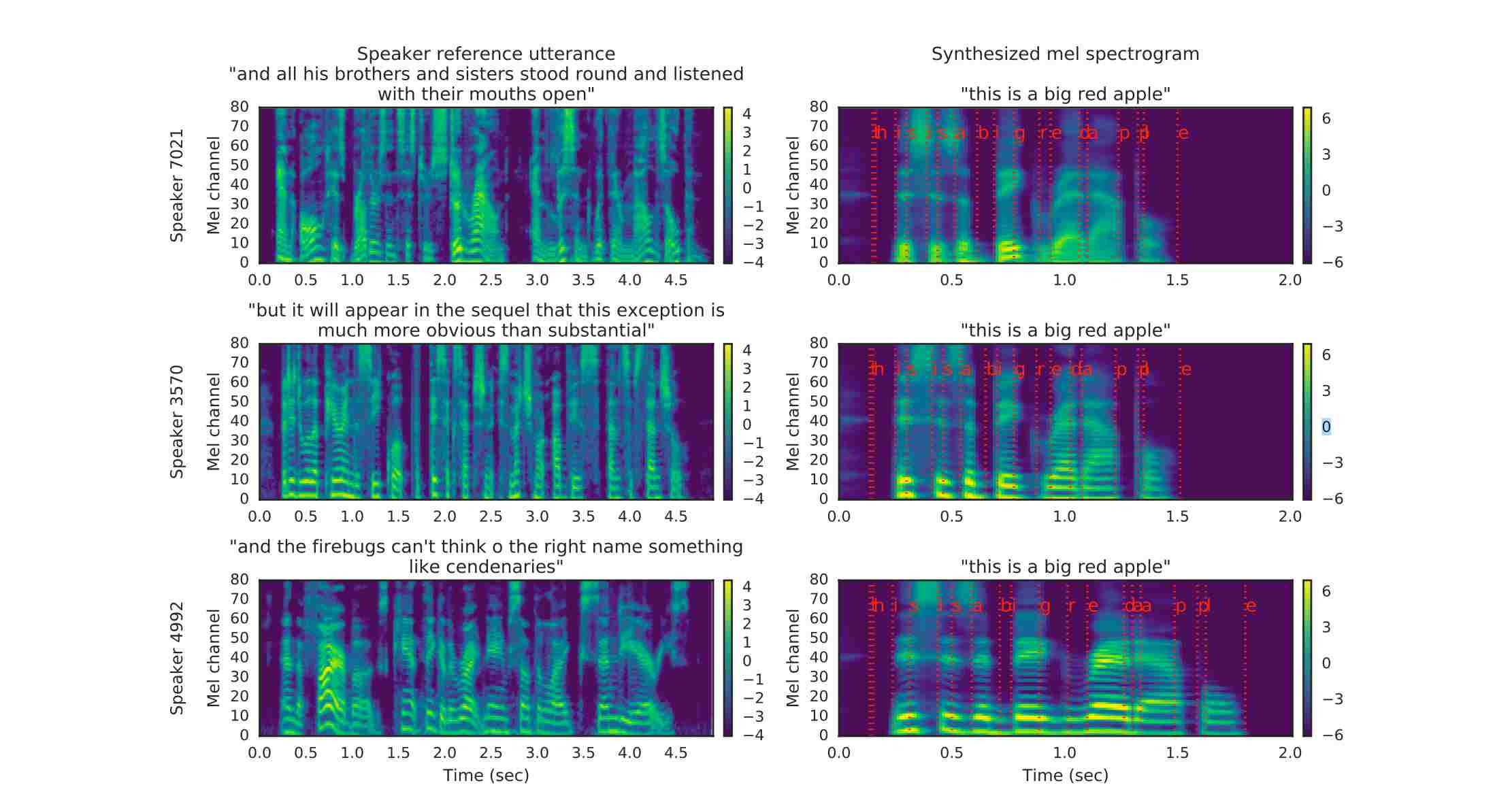
The red line on the right graph represents the correspondence between text and spectrogram. It can be seen that the speech signal used for reference supervision does not need to be consistent with the target speech signal in the text, which is also a major feature of the SV2TTS paper.
#### Speech synthesis network (WaveGlow)
WaveGlow: A network that synthesizes high-quality speech by relying on streams from Mel spectrograms. It combines Glow and WaveNet to generate fast, good, and high-quality rhythms without requiring automatic regression.
The Mel spectrogram (frequency domain) is converted into a time series sound waveform (time domain) to complete speech synthesis.
It should be noted that these three parts of the network are trained independently, and the voice encoder network mainly plays a conditional supervision role for the sequence mapping network, ensuring that the generated speech has the unique voice features of the speaker.
## Running Example- TTSExample
After successful operation, the command line should see the following information:
```text
...
[INFO] - Text: Convert text to speech based on the given voice
[INFO] - Given voice: src/test/resources/biaobei-009502.mp3
#Generate feature vector:
[INFO] - Speaker Embedding Shape: [256]
[INFO] - Speaker Embedding: [0.06272025, 0.0, 0.24136968, ..., 0.027405139, 0.0, 0.07339379, 0.0]
[INFO] - Mel spectrogram data Shape: [80, 331]
[INFO] - Mel spectrogram data: [-6.739388, -6.266942, -5.752069, ..., -10.643405, -10.558134, -10.5380535]
[INFO] - Generate wav audio file: build/output/audio.wav
```
The speech effect generated by the text "Convert text to speech based on the given voice":
[audio.wav](https://aias-home.oss-cn-beijing.aliyuncs.com/AIAS/voice_sdks/audio.wav)
AIAS - 人工智能加速器套件 提供: 包括SDK,平台引擎,场景套件在内,合计超过100个项目组成的项目集

版权申诉
120 浏览量
2023-08-12
10:04:27
上传
评论
收藏 101.31MB ZIP 举报
 AIAS - 人工智能加速器套件 提供: 包括SDK,平台引擎,场景套件在内,合计超过100个项目组成的项目集 (1781个子文件)
AIAS - 人工智能加速器套件 提供: 包括SDK,平台引擎,场景套件在内,合计超过100个项目组成的项目集 (1781个子文件)  gradlew.bat 2KB mvnw.cmd 6KB mvnw.cmd 6KB example.csv 40KB .env.development 93B .env.development 90B .env.development 90B .env.development 90B sougou.dict 983KB user.dict 85B .editorconfig 243B .editorconfig 243B .editorconfig 243B .editorconfig 243B .eslintignore 34B .eslintignore 34B .eslintignore 34B .eslintignore 34B
gradlew.bat 2KB mvnw.cmd 6KB mvnw.cmd 6KB example.csv 40KB .env.development 93B .env.development 90B .env.development 90B .env.development 90B sougou.dict 983KB user.dict 85B .editorconfig 243B .editorconfig 243B .editorconfig 243B .editorconfig 243B .eslintignore 34B .eslintignore 34B .eslintignore 34B .eslintignore 34B result.gif 1.56MB .gitignore 238B build.gradle 2KB build.gradle 1KB settings.gradle 39B gradlew 5KB
result.gif 1.56MB .gitignore 238B build.gradle 2KB build.gradle 1KB settings.gradle 39B gradlew 5KB index.html 691B index.html 620B index.html 620B index.html 620B favicon.ico 17KB favicon.ico 17KB favicon.ico 17KB favicon.ico 17KB voiceprint_sdk.iml 26KB asr_sdk.iml 25KB ocr-sdk.iml 23KB sv2tts_waveglow_sdk.iml 22KB tacotron2_sdk.iml 22KB capture_image_sdk.iml 22KB live2mp4_sdk.iml 22KB camera_face_sdk.iml 22KB camera2mp4_sdk.iml 22KB live2images_sdk.iml 22KB rtsp2rtmp_sdk.iml 22KB images2apng_sdk.iml 22KB mp4_face_sdk.iml 22KB camera_facemask_sdk.iml 22KB images2gif_sdk.iml 22KB mp4togif_sdk.iml 22KB rtsp_facemask_sdk.iml 22KB mp4_facemask_sdk.iml 22KB rtsp_face_sdk.iml 22KB camera-face-sdk.iml 22KB mp4-face-sdk.iml 22KB camera-facemask-sdk.iml 22KB rtsp-facemask-sdk.iml 22KB mp4-facemask-sdk.iml 22KB rtsp-face-sdk.iml 22KB sv2tts_speakencoder_sdk.iml 22KB imagekit_java.iml 22KB tacotron_stft_sdk.iml 21KB mp4togif-sdk.iml 21KB first_order_sdk.iml 20KB ffmpeg_audio_sdk.iml 20KB filter_sdk.iml 20KB image_sdk.iml 19KB platform-train.iml 14KB api-platform.iml 11KB flink_face_sdk.iml 8KB flink_sentence_encoder_sdk.iml 8KB flink_sentence_encoder_sdk.iml 8KB sentence-encoder-sdk.iml 6KB word_encoder_cn_sdk.iml 6KB word_encoder_cn_sdk.iml 6KB sentence-encoder-sdk.iml 6KB npy_npz_sdk.iml 4KB dishes_sdk.iml 4KB tokenizer_sdk.iml 4KB kafka_sentence_encoder_sdk.iml 4KB senta_textcnn_sdk.iml 4KB pedestrian_sdk.iml 4KB vehicle_sdk.iml 4KB kafka_sentiment_analysis_sdk.iml 4KB pose_estimation_sdk.iml 4KB traffic_sdk.iml 4KB animal_sdk.iml 4KB object_detection_v4_sdk.iml 4KB depth_estimation_sdk.iml 4KB kafka_face_sdk.iml 4KB semantic_simnet_bow_sdk.iml 3KB translation_zh_en_sdk.iml 3KB translation_en_de_sdk.iml 3KB porn_detection_sdk.iml 3KB senta_bilstm_sdk.iml 3KB lac_sdk.iml 3KB face_landmark_sdk.iml 3KB fasttext_sdk.iml 3KB face_sdk.iml 3KB mask_sdk.iml 3KB sentence_encoder_100_sdk.iml 3KB bert_qa_sdk.iml 3KB
index.html 691B index.html 620B index.html 620B index.html 620B favicon.ico 17KB favicon.ico 17KB favicon.ico 17KB favicon.ico 17KB voiceprint_sdk.iml 26KB asr_sdk.iml 25KB ocr-sdk.iml 23KB sv2tts_waveglow_sdk.iml 22KB tacotron2_sdk.iml 22KB capture_image_sdk.iml 22KB live2mp4_sdk.iml 22KB camera_face_sdk.iml 22KB camera2mp4_sdk.iml 22KB live2images_sdk.iml 22KB rtsp2rtmp_sdk.iml 22KB images2apng_sdk.iml 22KB mp4_face_sdk.iml 22KB camera_facemask_sdk.iml 22KB images2gif_sdk.iml 22KB mp4togif_sdk.iml 22KB rtsp_facemask_sdk.iml 22KB mp4_facemask_sdk.iml 22KB rtsp_face_sdk.iml 22KB camera-face-sdk.iml 22KB mp4-face-sdk.iml 22KB camera-facemask-sdk.iml 22KB rtsp-facemask-sdk.iml 22KB mp4-facemask-sdk.iml 22KB rtsp-face-sdk.iml 22KB sv2tts_speakencoder_sdk.iml 22KB imagekit_java.iml 22KB tacotron_stft_sdk.iml 21KB mp4togif-sdk.iml 21KB first_order_sdk.iml 20KB ffmpeg_audio_sdk.iml 20KB filter_sdk.iml 20KB image_sdk.iml 19KB platform-train.iml 14KB api-platform.iml 11KB flink_face_sdk.iml 8KB flink_sentence_encoder_sdk.iml 8KB flink_sentence_encoder_sdk.iml 8KB sentence-encoder-sdk.iml 6KB word_encoder_cn_sdk.iml 6KB word_encoder_cn_sdk.iml 6KB sentence-encoder-sdk.iml 6KB npy_npz_sdk.iml 4KB dishes_sdk.iml 4KB tokenizer_sdk.iml 4KB kafka_sentence_encoder_sdk.iml 4KB senta_textcnn_sdk.iml 4KB pedestrian_sdk.iml 4KB vehicle_sdk.iml 4KB kafka_sentiment_analysis_sdk.iml 4KB pose_estimation_sdk.iml 4KB traffic_sdk.iml 4KB animal_sdk.iml 4KB object_detection_v4_sdk.iml 4KB depth_estimation_sdk.iml 4KB kafka_face_sdk.iml 4KB semantic_simnet_bow_sdk.iml 3KB translation_zh_en_sdk.iml 3KB translation_en_de_sdk.iml 3KB porn_detection_sdk.iml 3KB senta_bilstm_sdk.iml 3KB lac_sdk.iml 3KB face_landmark_sdk.iml 3KB fasttext_sdk.iml 3KB face_sdk.iml 3KB mask_sdk.iml 3KB sentence_encoder_100_sdk.iml 3KB bert_qa_sdk.iml 3KB共 1781 条
- 1
- 2
- 3
- 4
- 5
- 6
- 18
资源评论


Java程序员-张凯
- 粉丝: 1w+
- 资源: 6732









最新资源
- postgresql-42.7.3.jar
- 2024-05-21 20-36-43.mkv
- 基于QT+C++的智能云监护仪项目,能够实时显示使用者心电、血氧、血压波形及其它各种参数+源码(毕业设计&课程设计&项目开发)
- 基于java开发的app接收硬件端传输的心音信号,具有显示心音波形,发出心音的功能+源码(毕业设计&课程设计&项目开发)
- Python 程序语言设计模式思路-行为型模式:职责链模式:将请求从一个处理者传递到下一个处理者
- 9241703124789646.16健身系统2.apk
- postgresql-16.3-1-windows-x64.exe
- Python 程序语言设计模式思路-结构型模式:装饰器讲解及利用Python装饰器模式实现高效日志记录和性能测试
- 基于YOLOv5和DeepSORT的多目标跟踪仿真与记录
- Python 程序语言设计模式思路-创建型模式:原型模式:通过复制现有对象来创建新对象,面向对象编程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


