
搭建
虚拟机网络配置
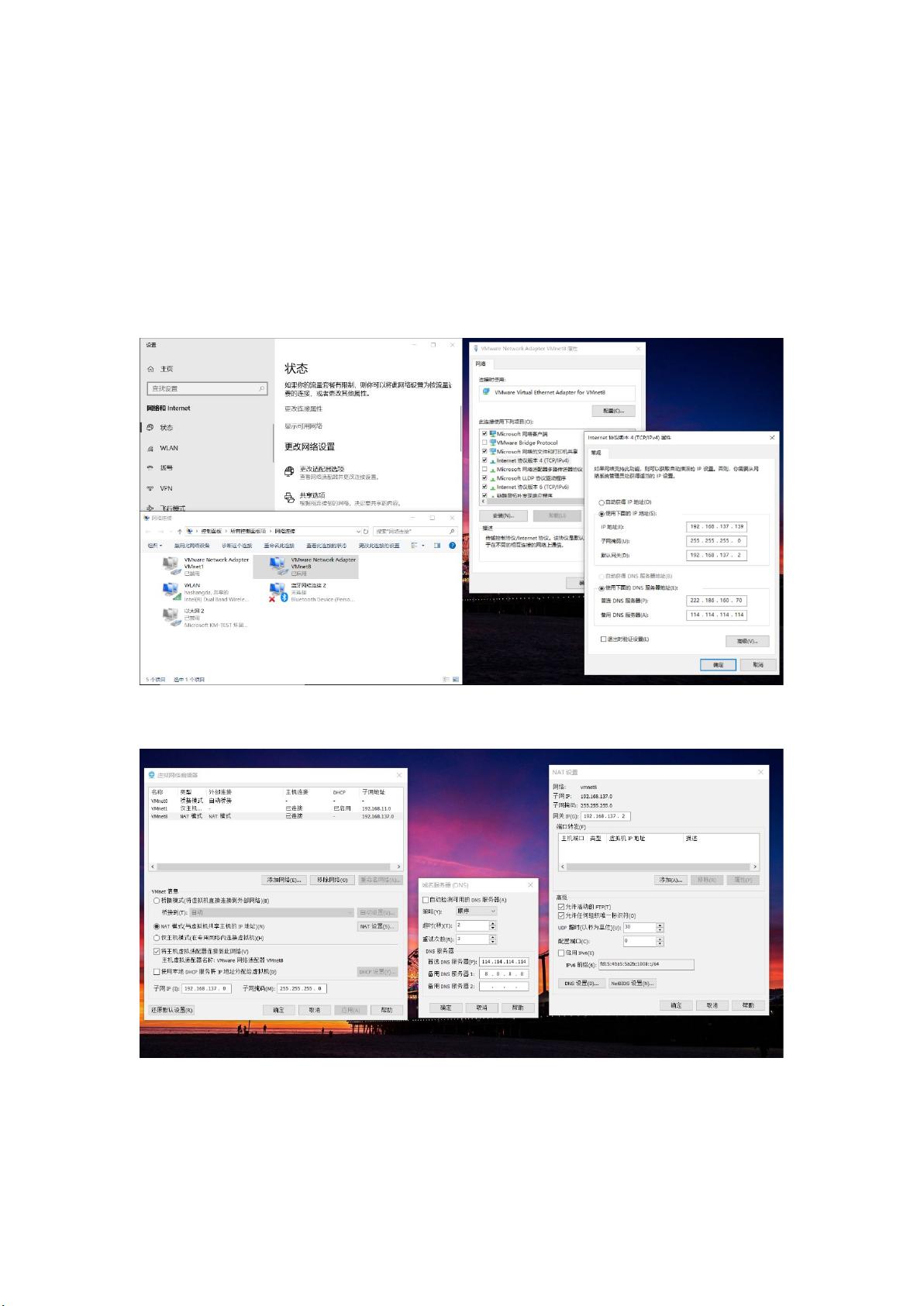
在主机 联网的情况下使用 模式
虚拟机网络配置必须和主机 ( 模式的网卡 是桥接模式的
网卡)里的 同一网段,右键 点击属性,然后选择 协议版本 查看
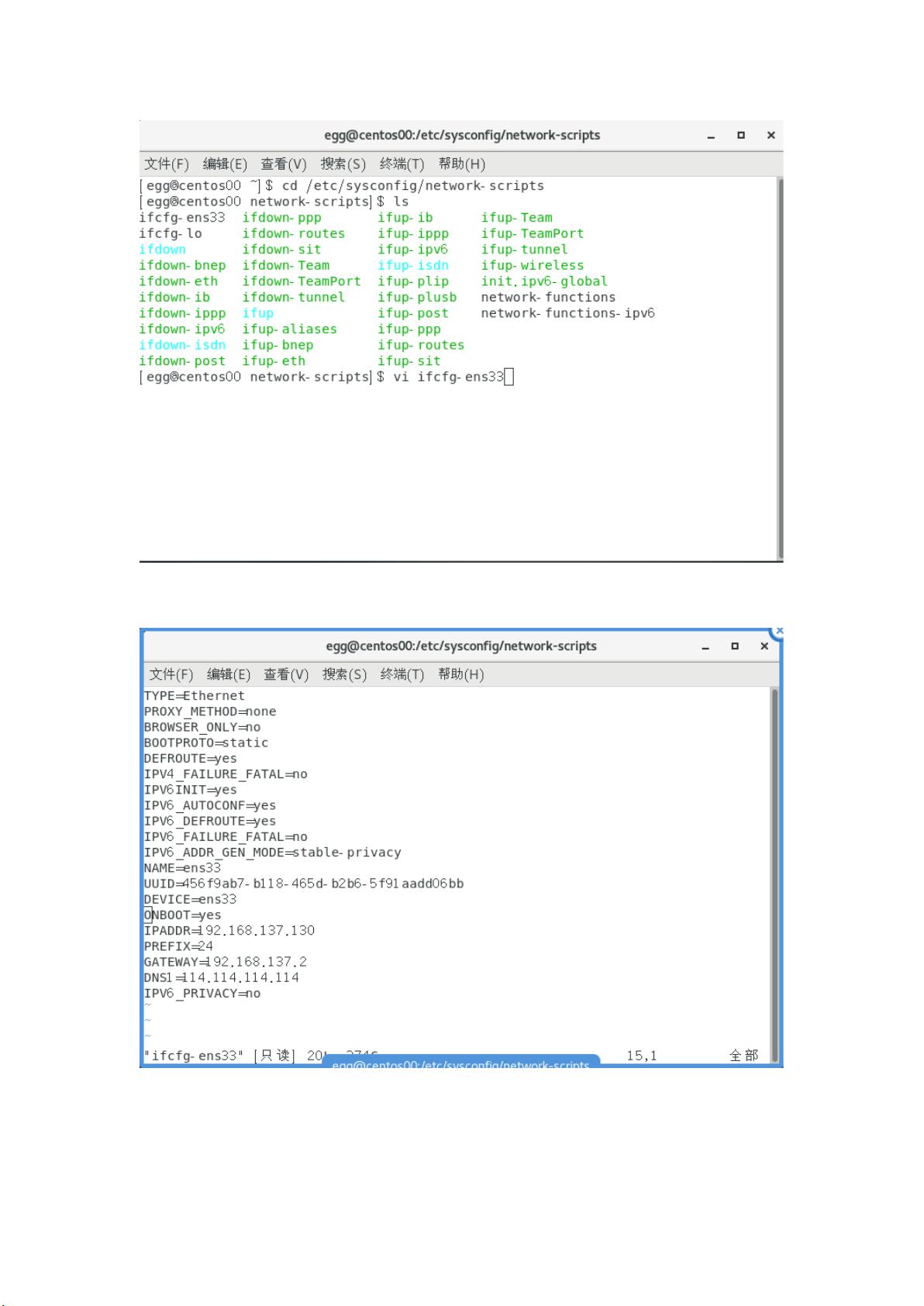
地址,根据主机 的参数配置虚拟机的
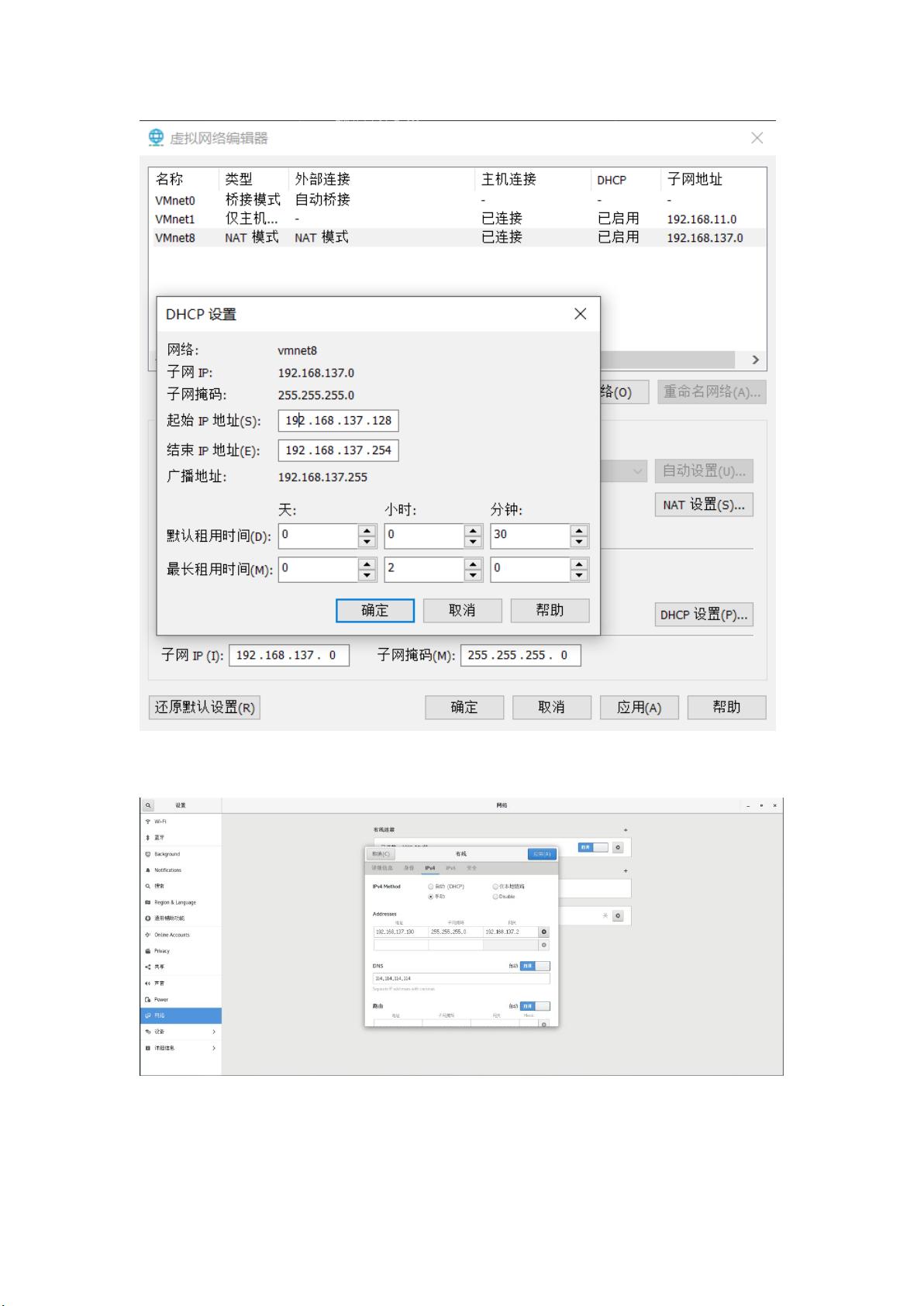
虚拟机配置的 必须在如下图中的起始地址和结束地址之间
剩余17页未读,继续阅读
资源评论


「已注销」
- 粉丝: 0
- 资源: 6









最新资源
- (源码)基于C语言的系统服务框架.zip
- (源码)基于Spring MVC和MyBatis的选课管理系统.zip
- (源码)基于ArcEngine的GIS数据处理系统.zip
- (源码)基于JavaFX和MySQL的医院挂号管理系统.zip
- (源码)基于IdentityServer4和Finbuckle.MultiTenant的多租户身份认证系统.zip
- (源码)基于Spring Boot和Vue3+ElementPlus的后台管理系统.zip
- (源码)基于C++和Qt框架的dearoot配置管理系统.zip
- (源码)基于 .NET 和 EasyHook 的虚拟文件系统.zip
- (源码)基于Python的金融文档智能分析系统.zip
- (源码)基于Java的医药管理系统.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


