

1
A Survey of the Recent Architectures of Deep Convolutional Neural Networks
Asifullah Khan
1, 2*
, Anabia Sohail
1, 2
,
Umme Zahoora
1
, and Aqsa Saeed Qureshi
1
1
Pattern Recognition Lab, DCIS, PIEAS, Nilore, Islamabad 45650, Pakistan
2
Deep Learning Lab, Center for Mathematical Sciences, PIEAS, Nilore, Islamabad 45650, Pakistan
asif@pieas.edu.pk
Abstract
Deep Convolutional Neural Networks (CNNs) are a special type of Neural Networks, which
have shown state-of-the-art performance on various competitive benchmarks. The powerful
learning ability of deep CNN is largely due to the use of multiple feature extraction stages
(hidden layers) that can automatically learn representations from the data. Availability of a large
amount of data and improvements in the hardware processing units have accelerated the research
in CNNs, and recently very interesting deep CNN architectures are reported. The recent race in
developing deep CNNs shows that the innovative architectural ideas, as well as parameter
optimization, can improve CNN performance. In this regard, different ideas in the CNN design
have been explored such as the use of different activation and loss functions, parameter
optimization, regularization, and restructuring of the processing units. However, the major
improvement in representational capacity of the deep CNN is achieved by the restructuring of the
processing units. Especially, the idea of using a block as a structural unit instead of a layer is
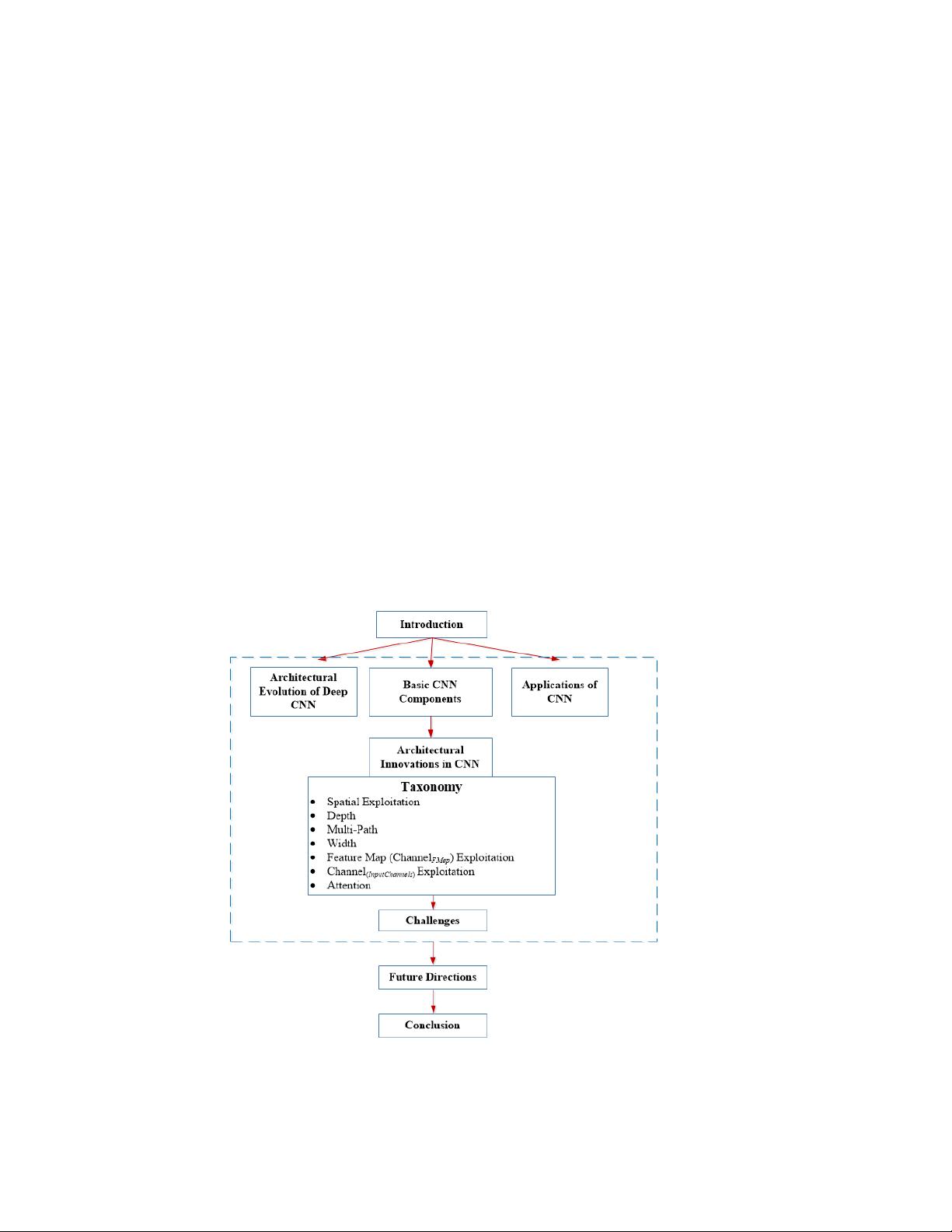
receiving substantial attention. This survey thus focuses on the intrinsic taxonomy present in the
recently reported deep CNN architectures and consequently, classifies the recent innovations in
CNN architectures into seven different categories. These seven categories are based on spatial
exploitation, depth, multi-path, width, feature map exploitation, channel boosting, and attention.
Additionally, this survey also covers the elementary understanding of CNN components and
sheds light on its current challenges and applications.
Keywords: Deep Learning, Convolutional Neural Networks, Architecture, Representational
Capacity, Residual Learning, and Channel Boosted CNN.



剩余66页未读,继续阅读













评论0