
Ubuntu16.04+hadoop2.7.3 环境搭建
1 VM 安装
2 Ubuntu16.04 虚拟机安装
3 安装 VMtools
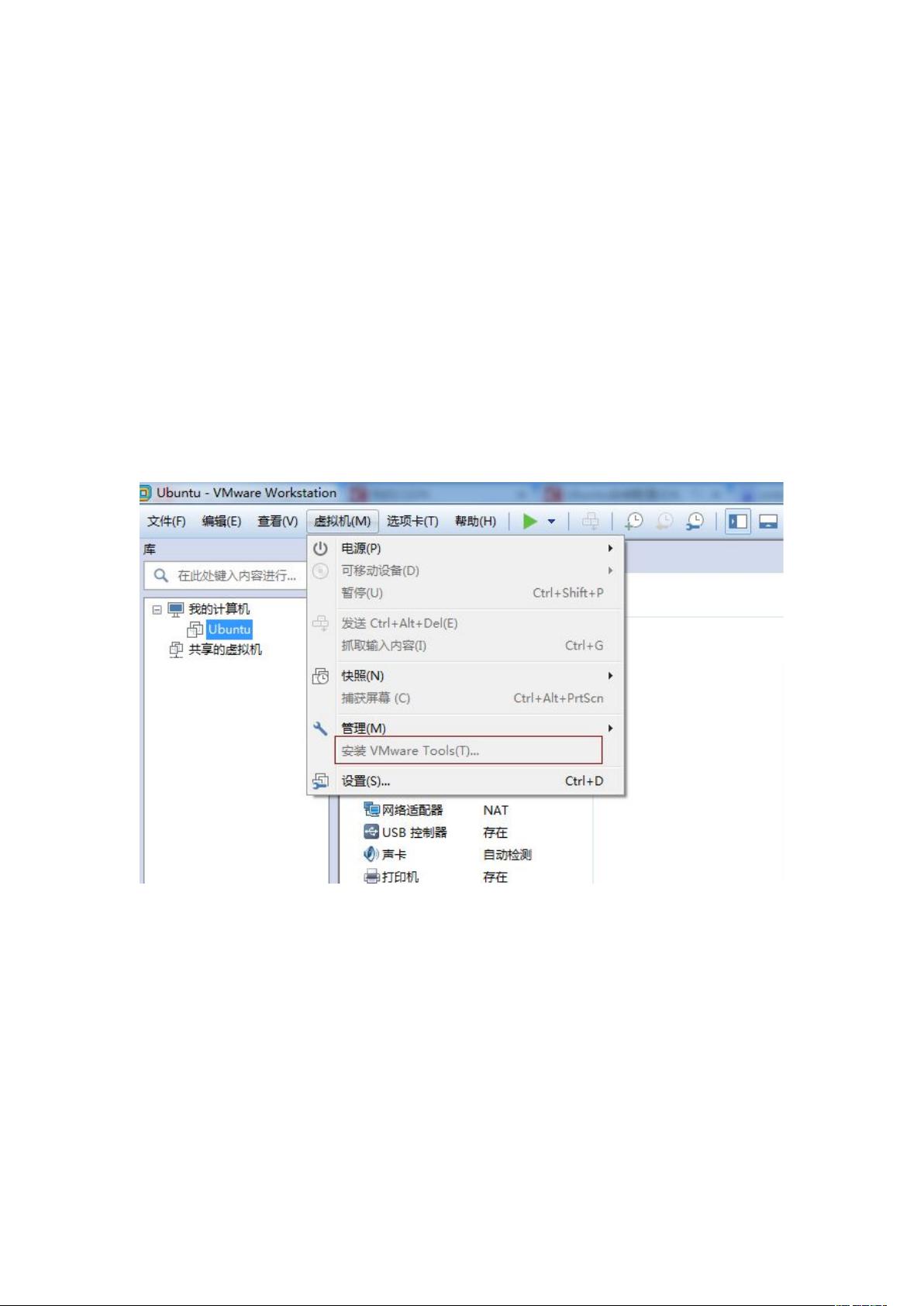
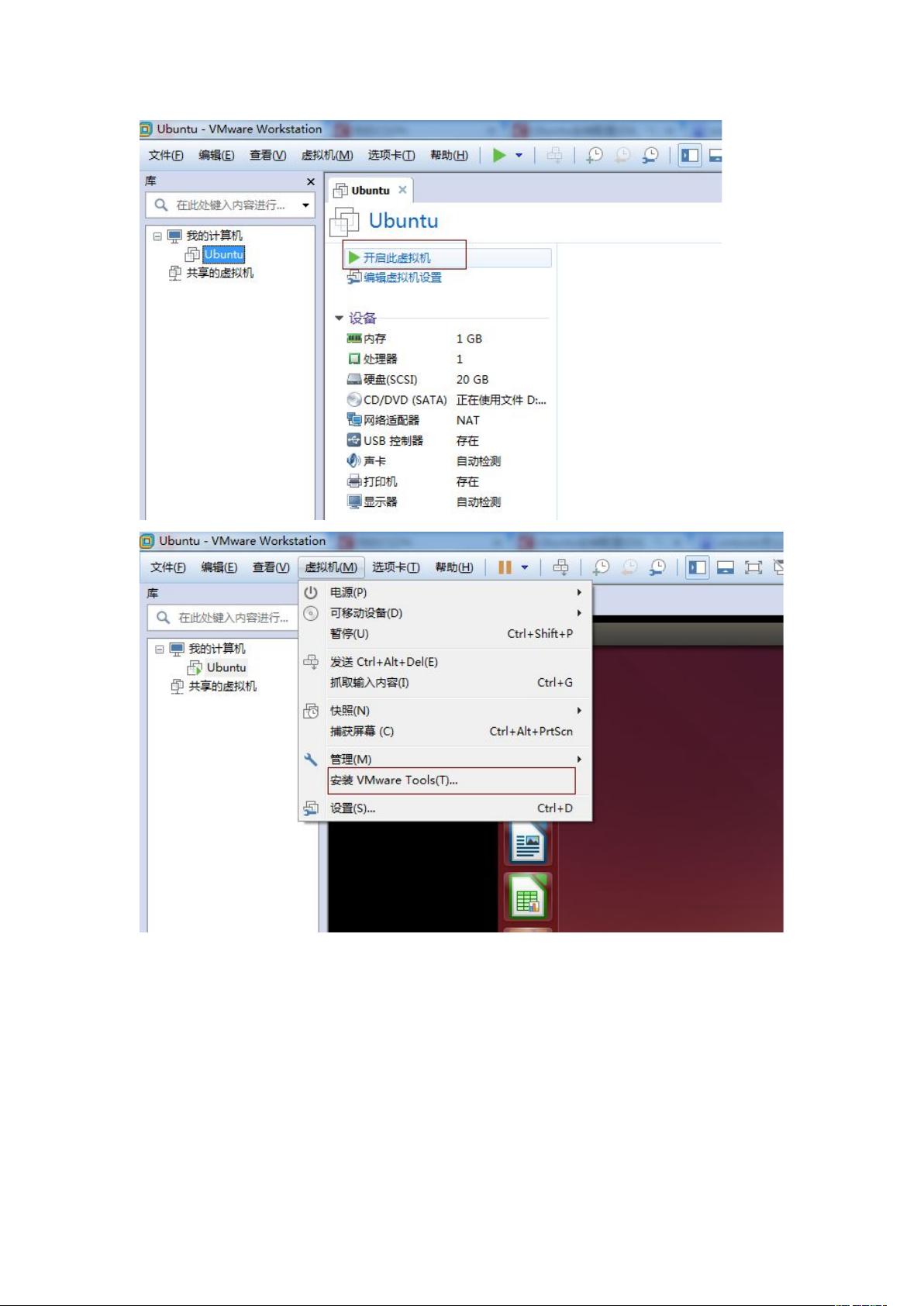
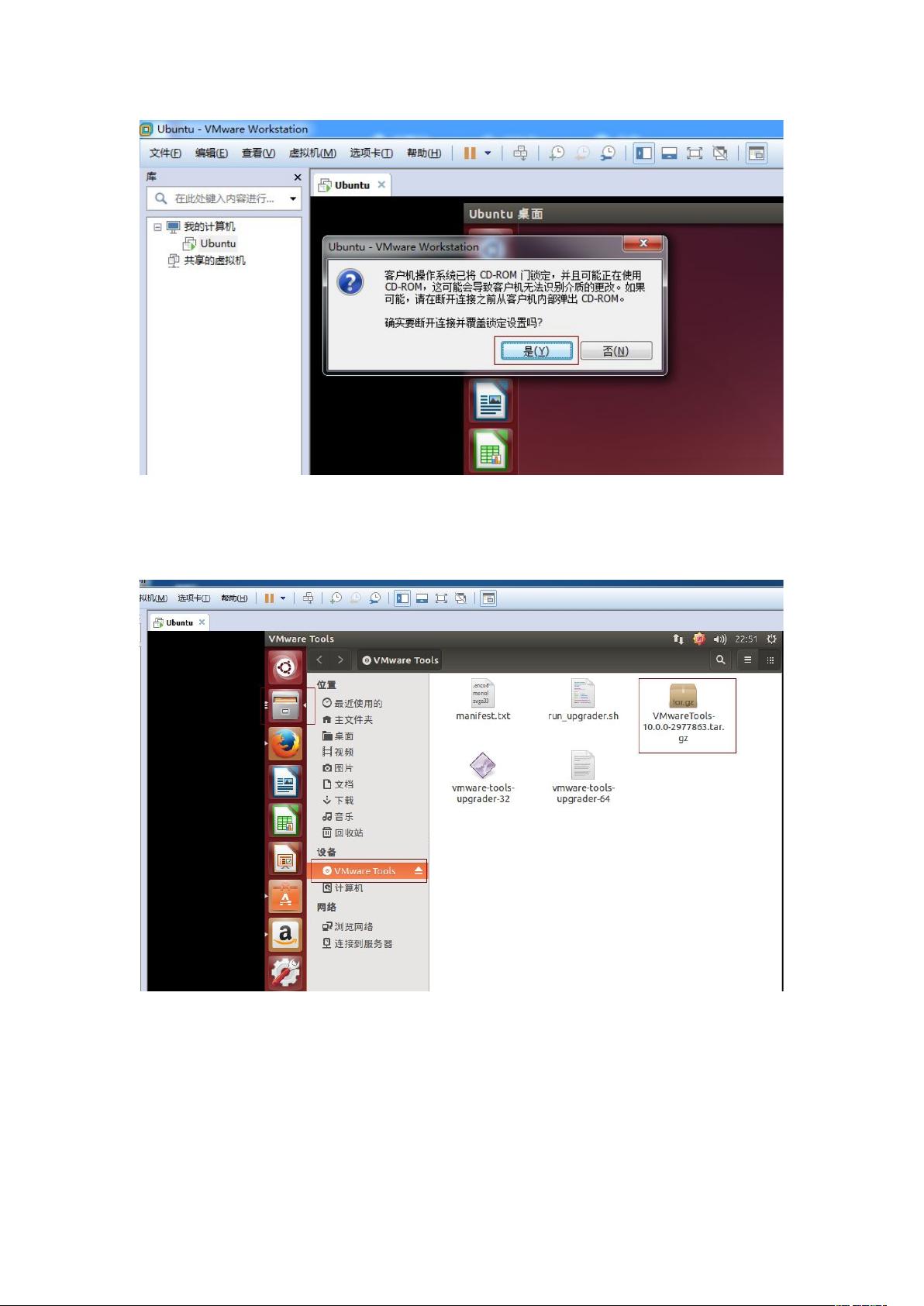
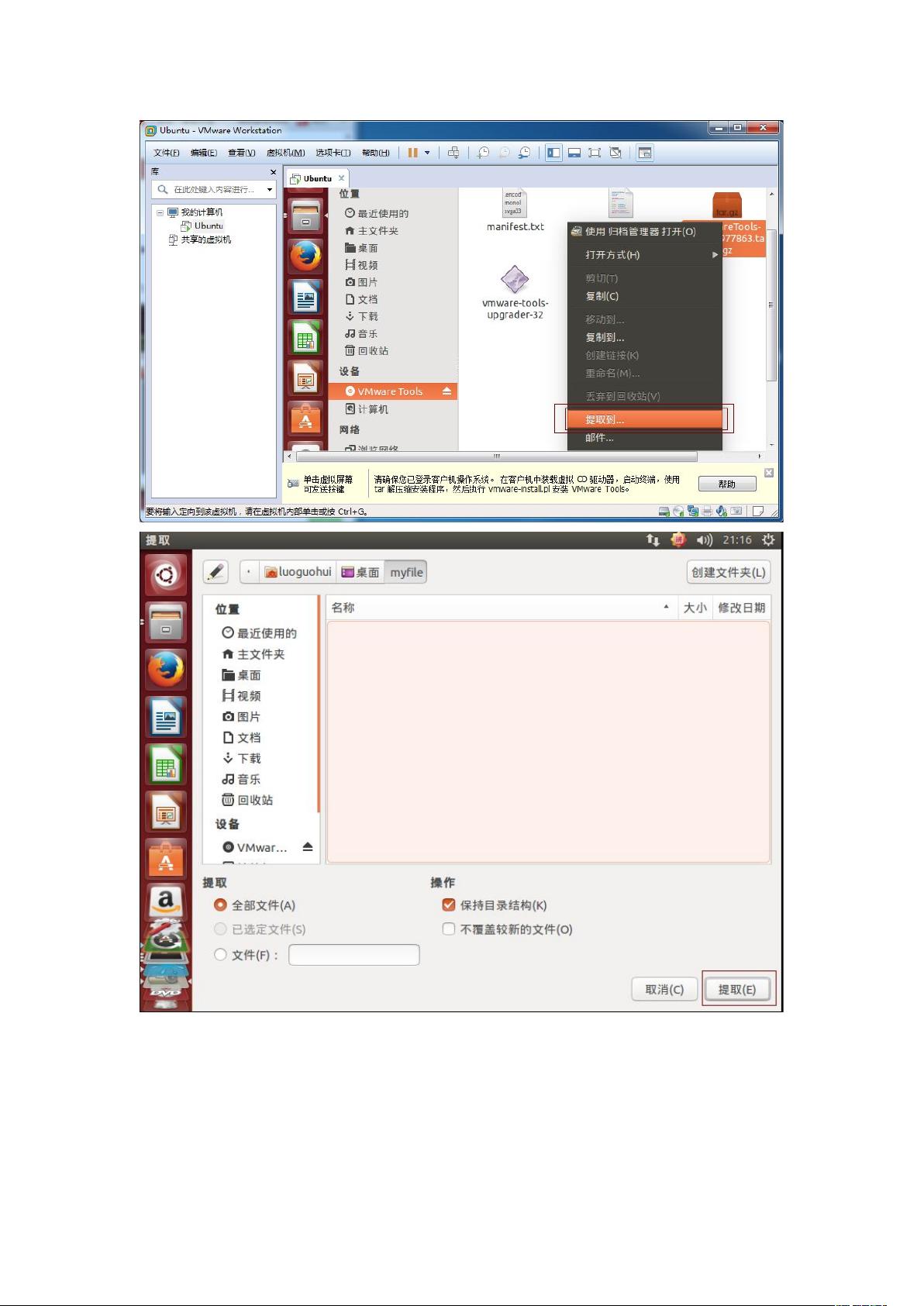
打开虚拟机 VMware Workstaon,启动 Ubuntu 系统,菜单栏 - 虚拟机 - 安装
VMware Tools,不启动 Ubuntu 系统是无法点击“安装 VMware Tools”选项的,如
下图:
剩余25页未读,继续阅读
资源评论


听你眼睛唱歌
- 粉丝: 1
- 资源: 3









最新资源
- 基于Simulink的考虑局部遮阴的光伏PSO-MPPT控制模型.rar
- 基于Simulink的最大功率点追踪MPPT功能的单相单级脉宽调制(PWM)光伏逆变器,并且支持并网运行.rar
- 基于TCN-GRU的自行车租赁数量预测研究Matlab代码.rar
- 基于TCN-GRU-Attention的自行车租赁数量预测研究Matlab代码.rar
- 基于WoodandBerry1和非耦合控制WoodandBerry2来实现控制木材和浆果蒸馏柱控制Simulink仿真.rar
- 基于变分多谐波对偶模式追踪从噪声信号中提取重复瞬态分量的方法附Matlab代码.rar
- 基于Python的智能门禁打卡系统设计与开发-含详细代码及解释
- 数电课件,数字电路与逻辑
- A Neural Probabilistic Language Model.pdf
- 基于Java的学生信息管理系统实现
- OpenCV人脸检测和识别
- 管理工具PKIManager-1.1.3.6-全算法版本-信创
- ACM程序设计经典题目与解决方案(C语言实现)
- 详细的Visual Studio安装教程及注意事项
- 手机侧面轮廓尺寸检测机3D图纸和工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- GitHub教程:账号注册、项目创建与协同开发详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


