## Prosody features
```sh
prosody.py
```
Compute prosody features from continuous speech based on duration, fundamental frequency and energy.
Static or dynamic features can be computed:
Static matrix is formed with 103 features and include
Num Feature Description
--------------------------------------------------------------------------------------------------------------------------
Features based on F0
---------------------------------------------------------------------------------------------------------------------------
1-6 F0-contour Avg., Std., Max., Min., Skewness, Kurtosis
7-12 Tilt of a linear estimation of F0 for each voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
13-18 MSE of a linear estimation of F0 for each voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
19-24 F0 on the first voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
25-30 F0 on the last voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
--------------------------------------------------------------------------------------------------------------------------
Features based on energy
---------------------------------------------------------------------------------------------------------------------------
31-34 energy-contour for voiced segments Avg., Std., Skewness, Kurtosis
35-38 Tilt of a linear estimation of energy contour for V segments Avg., Std., Skewness, Kurtosis
39-42 MSE of a linear estimation of energy contour for V segment Avg., Std., Skewness, Kurtosis
43-48 energy on the first voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
49-54 energy on the last voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
55-58 energy-contour for unvoiced segments Avg., Std., Skewness, Kurtosis
59-62 Tilt of a linear estimation of energy contour for U segments Avg., Std., Skewness, Kurtosis
63-66 MSE of a linear estimation of energy contour for U segments Avg., Std., Skewness, Kurtosis
67-72 energy on the first unvoiced segment Avg., Std., Max., Min., Skewness, Kurtosis
73-78 energy on the last unvoiced segment Avg., Std., Max., Min., Skewness, Kurtosis
--------------------------------------------------------------------------------------------------------------------------
Features based on duration
---------------------------------------------------------------------------------------------------------------------------
79 Voiced rate Number of voiced segments per second
80-85 Duration of Voiced Avg., Std., Max., Min., Skewness, Kurtosis
86-91 Duration of Unvoiced Avg., Std., Max., Min., Skewness, Kurtosis
92-97 Duration of Pauses Avg., Std., Max., Min., Skewness, Kurtosis
98-103 Duration ratios Pause/(Voiced+Unvoiced), Pause/Unvoiced, Unvoiced/(Voiced+Unvoiced),
Voiced/(Voiced+Unvoiced), Voiced/Puase, Unvoiced/Pause
---------------------------------------------------------------------------------------------------------------------------
The dynamic feature matrix is formed with 13 features computed for each voiced segment and contains:
- 1 Duration of the voiced segment
- 2-7. Coefficients of 5-degree Lagrange polynomial to model F0 contour
- 8-13. Coefficients of 5-degree Lagrange polynomial to model energy contour
Dynamic prosody features are based on
Najim Dehak, "Modeling Prosodic Features With Joint Factor Analysis for Speaker Verification", 2007
### Notes:
1. The fundamental frequency is computed the PRAAT algorithm. To use the RAPT method, change the "self.pitch method" variable in the class constructor.
2. When Kaldi output is set to "true" two files will be generated, the ".ark" with the data in binary format and the ".scp" Kaldi script file
### Runing
Script is called as follows
```sh
python prosody.py <file_or_folder_audio> <file_features> <static (true or false)> <plots (true or false)> <format (csv, txt, npy, kaldi, torch)>
```
### Examples:
Extract features in the command line
```sh
python prosody.py "../audios/001_ddk1_PCGITA.wav" "prosodyfeaturesAst.txt" "true" "true" "txt"
python prosody.py "../audios/001_ddk1_PCGITA.wav" "prosodyfeaturesUst.csv" "true" "true" "csv"
python prosody.py "../audios/001_ddk1_PCGITA.wav" "prosodyfeaturesUdyn.pt" "false" "true" "torch"
python prosody.py "../audios/" "prosodyfeaturesst.txt" "true" "false" "txt"
python prosody.py "../audios/" "prosodyfeaturesst.csv" "true" "false" "csv"
python prosody.py "../audios/" "prosodyfeaturesdyn.pt" "false" "false" "torch"
python prosody.py "../audios/" "prosodyfeaturesdyn.csv" "false" "false" "csv"
KALDI_ROOT=/home/camilo/Camilo/codes/kaldi-master2
export PATH=$PATH:$KALDI_ROOT/src/featbin/
python prosody.py "../audios/001_ddk1_PCGITA.wav" "prosodyfeaturesUdyn" "false" "false" "kaldi"
python prosody.py "../audios/" "prosodyfeaturesdyn" "false" "false" "kaldi"
```
Extract features directly in Python
```
from prosody import Prosody
prosody=Prosody()
file_audio="../audios/001_ddk1_PCGITA.wav"
features1=prosody.extract_features_file(file_audio, static=True, plots=True, fmt="npy")
features2=prosody.extract_features_file(file_audio, static=True, plots=True, fmt="dataframe")
features3=prosody.extract_features_file(file_audio, static=False, plots=True, fmt="torch")
prosody.extract_features_file(file_audio, static=False, plots=False, fmt="kaldi", kaldi_file="./test")
```
[Jupyter notebook](https://github.com/jcvasquezc/DisVoice/blob/master/notebooks_examples/prosody_features.ipynb)
#### Results:
Prosody analysis from continuous speech static
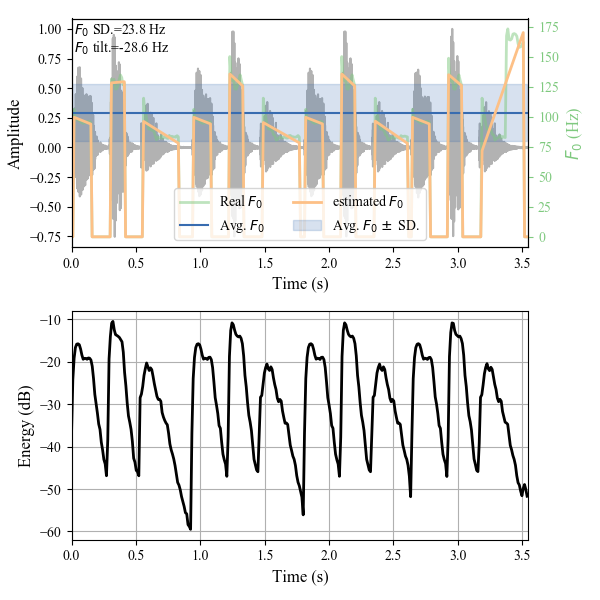
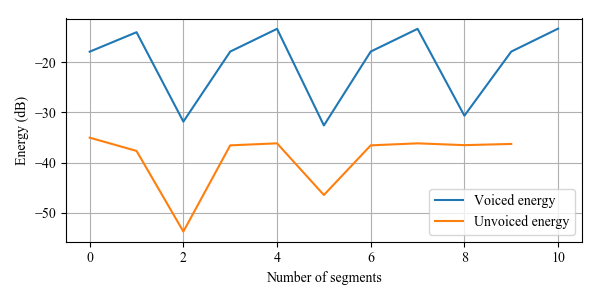
#### References
[[1]](http://ieeexplore.ieee.org/abstract/document/4291597/). N., Dehak, P. Dumouchel, and P. Kenny. "Modeling prosodic features with joint factor analysis for speaker verification." IEEE Transactions on Audio, Speech, and Language Processing 15.7 (2007): 2095-2103.
[[2]](http://www.sciencedirect.com/science/article/pii/S105120041730146X). J. R. Orozco-Arroyave, J. C. Vásquez-Correa et al. "NeuroSpeech: An open-source software for Parkinson's speech analysis." Digital Signal Processing (2017).
从语音信号中提取特征_Jupyter Notebook_Python_下载.zip

版权申诉
 从语音信号中提取特征_Jupyter Notebook_Python_下载.zip (222个子文件)
从语音信号中提取特征_Jupyter Notebook_Python_下载.zip (222个子文件)  disvoice.aux 10KB make.bat 778B .buildinfo 230B setup.cfg 123B sphinxmanual.cls 4KB sphinxhowto.cls 3KB theme.css 114KB basic.css 10KB pygments.css 4KB badge_only.css 3KB Glottal.doctree 56KB RepLearning.doctree 54KB Replearningfeatures.doctree 49KB Prosody.doctree 40KB Articulation.doctree 32KB Phonation.doctree 28KB Phonological.doctree 23KB reference.doctree 9KB index.doctree 9KB help.doctree 3KB lato-italic.eot 262KB lato-bolditalic.eot 260KB lato-bold.eot 250KB lato-regular.eot 248KB fontawesome-webfont.eot 162KB roboto-slab-v7-bold.eot 78KB roboto-slab-v7-regular.eot 76KB
disvoice.aux 10KB make.bat 778B .buildinfo 230B setup.cfg 123B sphinxmanual.cls 4KB sphinxhowto.cls 3KB theme.css 114KB basic.css 10KB pygments.css 4KB badge_only.css 3KB Glottal.doctree 56KB RepLearning.doctree 54KB Replearningfeatures.doctree 49KB Prosody.doctree 40KB Articulation.doctree 32KB Phonation.doctree 28KB Phonological.doctree 23KB reference.doctree 9KB index.doctree 9KB help.doctree 3KB lato-italic.eot 262KB lato-bolditalic.eot 260KB lato-bold.eot 250KB lato-regular.eot 248KB fontawesome-webfont.eot 162KB roboto-slab-v7-bold.eot 78KB roboto-slab-v7-regular.eot 76KB ajax-loader.gif 673B .gitignore 1KB .gitmodules 1B
ajax-loader.gif 673B .gitignore 1KB .gitmodules 1B RepLearning.html 36KB Glottal.html 34KB Replearningfeatures.html 32KB Prosody.html 32KB Articulation.html 27KB Phonological.html 25KB Phonation.html 25KB genindex.html 12KB index.html 10KB reference.html 9KB py-modindex.html 7KB help.html 6KB search.html 5KB disvoice_favicon.ico 105KB disvoice_favicon.ico 105KB disvoice.idx 3KB disvoice.ilg 419B disvoice.ind 3KB objects.inv 765B articulation_features.ipynb 1.58MB glottal_features.ipynb 1.17MB emotion classification using SVMs in scikit-learn.ipynb 592KB emotion classification using DNNs in Pytorch.ipynb 532KB phonological_features.ipynb 466KB replearning_features.ipynb 222KB prosody_features.ipynb 106KB phonation_features.ipynb 50KB python.ist 267B jquery-3.1.0.js 258KB jquery.js 84KB underscore-1.3.1.js 34KB searchtools.js 25KB websupport.js 25KB modernizr.min.js 15KB underscore.js 12KB searchindex.js 10KB doctools.js 8KB theme.js 4KB LICENSE 1KB Makefile 2KB Makefile 607B README.md 7KB README.md 4KB README.md 4KB README.md 4KB README.md 4KB README.md 4KB README.md 3KB reference.md 2KB index.md 2KB RepLearning.md 493B Glottal.md 337B Articulation.md 274B Phonological.md 264B Phonation.md 253B Prosody.md 238B help.md 138B disvoice.out 3KB
RepLearning.html 36KB Glottal.html 34KB Replearningfeatures.html 32KB Prosody.html 32KB Articulation.html 27KB Phonological.html 25KB Phonation.html 25KB genindex.html 12KB index.html 10KB reference.html 9KB py-modindex.html 7KB help.html 6KB search.html 5KB disvoice_favicon.ico 105KB disvoice_favicon.ico 105KB disvoice.idx 3KB disvoice.ilg 419B disvoice.ind 3KB objects.inv 765B articulation_features.ipynb 1.58MB glottal_features.ipynb 1.17MB emotion classification using SVMs in scikit-learn.ipynb 592KB emotion classification using DNNs in Pytorch.ipynb 532KB phonological_features.ipynb 466KB replearning_features.ipynb 222KB prosody_features.ipynb 106KB phonation_features.ipynb 50KB python.ist 267B jquery-3.1.0.js 258KB jquery.js 84KB underscore-1.3.1.js 34KB searchtools.js 25KB websupport.js 25KB modernizr.min.js 15KB underscore.js 12KB searchindex.js 10KB doctools.js 8KB theme.js 4KB LICENSE 1KB Makefile 2KB Makefile 607B README.md 7KB README.md 4KB README.md 4KB README.md 4KB README.md 4KB README.md 4KB README.md 3KB reference.md 2KB index.md 2KB RepLearning.md 493B Glottal.md 337B Articulation.md 274B Phonological.md 264B Phonation.md 253B Prosody.md 238B help.md 138B disvoice.out 3KB disvoice.pdf 1.11MB environment.pickle 17KB
disvoice.pdf 1.11MB environment.pickle 17KB phonological1.png 488KB phonological1.png 488KB phonological1.png 488KB replearning_continuous.png 244KB replearning_continuous.png 244KB replearning_continuous.png 244KB glottal_vowel.png 198KB glottal_vowel.png 198KB glottal_vowel.png 198KB phonological2.png 152KB
phonological1.png 488KB phonological1.png 488KB phonological1.png 488KB replearning_continuous.png 244KB replearning_continuous.png 244KB replearning_continuous.png 244KB glottal_vowel.png 198KB glottal_vowel.png 198KB glottal_vowel.png 198KB phonological2.png 152KB共 222 条
- 1
- 2
- 3
资源评论

 2301_771407632024-05-20资源有很好的参考价值,总算找到了自己需要的资源啦。
2301_771407632024-05-20资源有很好的参考价值,总算找到了自己需要的资源啦。

快撑死的鱼
- 粉丝: 1w+
- 资源: 9154

下载权益

C知道特权

VIP文章

课程特权
开通VIP











