



2021 年二手车交易价格分析以及预测
一、 项目介绍
1.1 项目背景
过去的的二十年是微软的时代,是个人电脑不断普及的时代,从 1995 年到 2007 年,
比尔盖茨连续 13 年《福布斯》全球首富排行榜第一。之后随着互联网的发展,BAT 逐渐走
向世界舞台。而后人工智能不断被提及,深度学习以及工业互联网的浪潮袭来,现如今又伴
随着物联网技术的快速发展。过去市场的焦点是电脑,随着时代的发展,焦点转移到了网络、
手机、智能手机,现如今上述已经几乎是每个人的标配。随着无人驾驶技术的发展,也许车
辆就是下一个时代的浪潮。
1.2 项目内容
本项目着眼于车辆信息,结合当下火热的二手车交易市场数据,对最近二手车的交易价
格进行分析以及预测。
经过前期调研,最终决定通过爬取一些网站的二手车数据和一些公开的数据集,分析交
易数据的特征,根据交易特征对 2021 年二手车交易价格进行分析预测。
二、 数据来源及获取
2.1 爬取网站数据
1)选择最火的二手车交易网站-瓜子二手车。点开官网,点击我要买车。
图 2-1 我要买车
2)根据不同的浏览器,选择不同的方式解析网页源码与数据包,选择 DOC 过滤。获取头
部 cookie 等相关信息,使程序伪装成浏览器。
图 2-2 获取头部信息
3)通过搜索框,输入页面商品名称和属性名称,获取每个交易车辆的详细地址以及想要
数据的位置
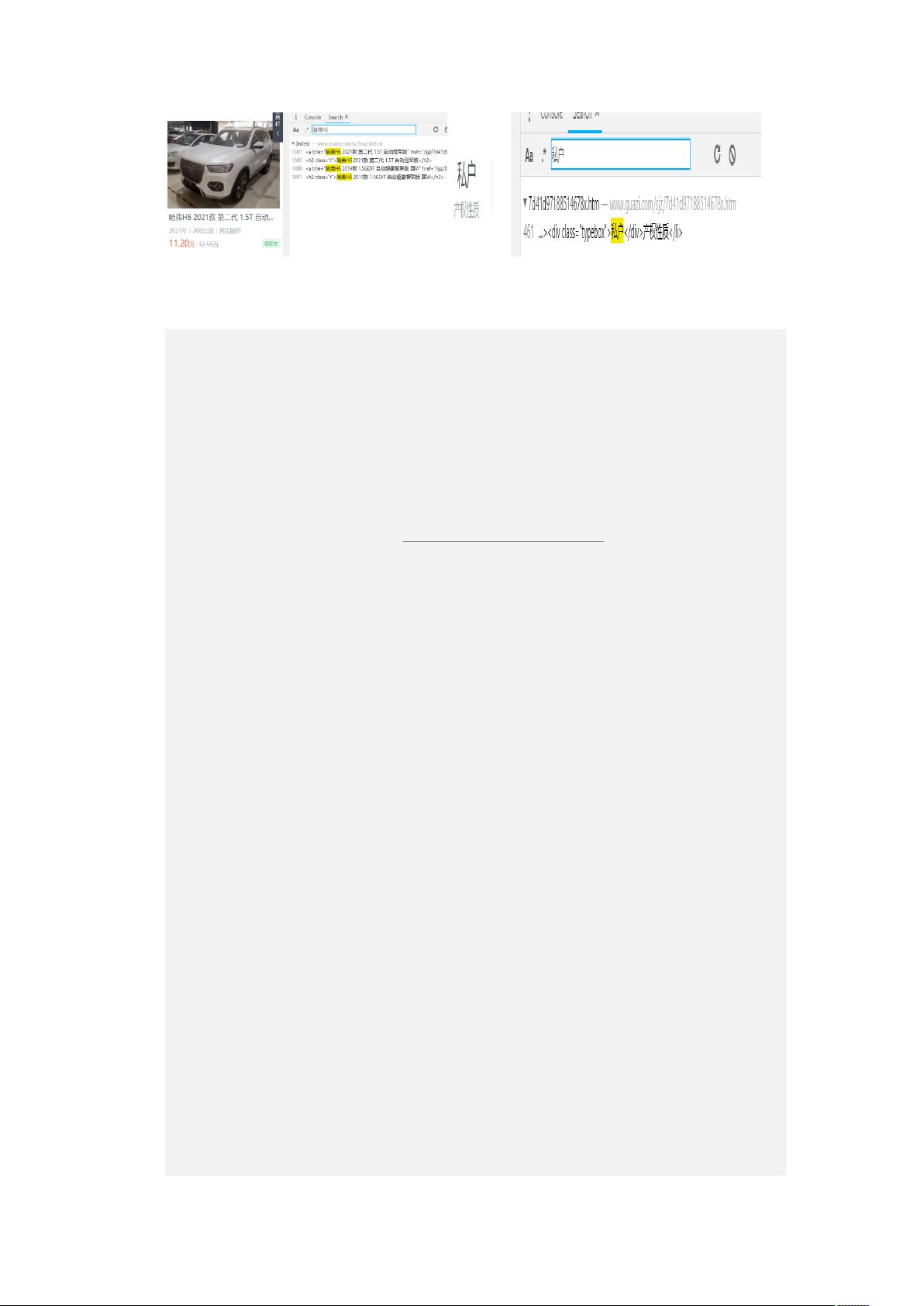
(a)详细地址 (b)想要数据的位置
图 2-3 获取详细信息
4)主要函数如下所示:
# 获取详细数据的 url
def get_detail_url(url, headers):
rq = requests.get(url, headers=headers)
soup = BeautifulSoup(rq.text, 'lxml')
content = soup.find(class_='carlist clearfix js-top')
links = content.find_all('a')
detail_url_list = []
for link in links:
detail_url_list.append(f"https://www.guazi.com{link['href']}")
return detail_url_list
# 获取详情数据
def get_detail(url, headers):
rq = requests.get(url, headers=headers)
soup = BeautifulSoup(rq.text, 'lxml')
# name
content = soup.find(class_='product-textbox')
title = content.find('h1').text
# info (上牌时间为图片) 里程数 排量 变速箱
info = content.find(class_='assort clearfix')
span = info.find_all('span')
if len(span) >= 4:
info_dic = {'name': title.strip(), 'km': span[1].text, 'displacement':
span[2].text, 'gearbox': span[3].text}
else: # 某些网页 span 数据较少
info_dic = {'name': title.strip(), 'km': span[1].text, 'displacement': '无',
'gearbox': '无'}
# price 价格单位是万
price = soup.find(class_='price-num') # price-num pricebox js-disprice
price = price.text
# 销售方
seller = soup.find(class_='ten')

seller = seller.find(class_='typebox')
seller = seller.text
# 燃油类型
fuel = soup.find_all(class_='td2') # 很多信息 第十五个是燃油类型 或者 没有信息
horsepower = "无"
if len(fuel)>=13:
horsepower = fuel[12].text
if len(fuel)>=15:
fuel = fuel[14].text
else:
fuel = "无"
# fuel
return info_dic, price, seller, fuel,horsepower
2.2 公开赛数据
网站上的数据爬取难度较高,且数据量较少,一直爬取容易被封 IP,所以这里使用公开
赛的一个数据集对数据进行补充------阿里天池的二手车交易价格预测数据集。其数据具体内
容如下图所示。
图 2-4 公开赛数据集详细信息
2.3 爬取数据转换以及保存
网站上爬取的数据与公开赛数据集的数据是不一致的,相对来说公开赛数据集的标签比
较多,信息比较详细,且数据类型单一,方便后续处理。所以这里需要对两个数据集进行统
一,爬取的数据向公开赛数据靠拢,即爬取的公开赛数据集所拥有的标签,并将其转换为同
一单位(比如 fuelType 网站上的数据是汉字,而公开赛数据集里的数据为数字,为了较少存
储内存以及方便数据的后续处理,在这里将其统一为数字),同时删除无法在网站上爬取的
公开赛数据中的标签。爬取的代码已经在 2-1 中展示,以下为转换和保存的代码:
name = []
fuelType = []
gearbox = []
power = []
kilometer = []
seller = []
price = []
# 爬取 保存数据
for page in range(1,3):
print("************第{}页正在保存**********".format(page)) # 每一页 数量不定
base_url = 'https://www.guazi.com/sjz/buy/o{}/#bread'.format(page) #
detail_url = get_detail_url(base_url, headers) # 所有车辆详细信息链接
print(len(detail_url))
for d_url in detail_url:
print(d_url)
info_dic, pric, sell, fuel, horsepower = get_detail(d_url, headers)
name.append(info_dic['name']) # 名字
if fuel.find("汽油"):
fuel = 0
elif fuel.find("柴油"):
fuel = 1
elif fuel.find("液化石油气"):
fuel = 2
elif fuel.find("天然气"):
fuel = 3
elif fuel.find("混合动力"):
fuel = 4
else:
fuel = 6
fuelType.append(fuel) # 燃油类型
tmp = info_dic['gearbox']
if tmp.find("手动"):
tmp = 0
else: # 电动汽车 大多是自动挡
tmp = 1
gearbox.append(tmp) # 变速箱 自动 or 手动
tmp = re.findall("\d+", horsepower)
if len(tmp) == 0:
tmp = 0
else:
tmp = int(tmp[0]) * 0.735
power.append(tmp) # 功率
km = re.findall(r"\d+\.?\d*", info_dic['km'])
if len(km) == 0:

km = 0
else:
km = float(km[0])
kilometer.append(km) # 里程数
if sell.find("私户"):
sell = 0
else:
sell = 1
seller.append(sell) # 销售方、
tmp = re.findall(r"\d+\.?\d*", pric)
if len(tmp) == 0:
tmp = 0
else:
tmp = float(tmp[0]) * 10000
price.append(tmp) # 价格
df = pd.DataFrame({'name' : name,
'fuelType': fuelType,
'gearbox' : gearbox ,
'power' : power,
'kilometer': kilometer,
'seller' : seller,
'price' : price})
df.to_csv('guazi.csv') # 最终保存为 csv 文件
2.4 爬取数据完整代码
以上分析了我们应该怎么爬取数据、爬取什么数据,以及如何对爬取的数据进行转换和
保存。以下贴出完整代码,复制到.py 文件可直接运行。
import numpy
import os
import time
import pandas as pd
import requests
import lxml
from bs4 import BeautifulSoup # 解析网页
import parsel
import re
# 参考
https://blog.csdn.net/XRLoft/article/details/112706442/https://blog.csdn.net/yuany
ibujian/article/details/107612631
# 获取详细数据的 url
def get_detail_url(url, headers):
rq = requests.get(url, headers=headers)
soup = BeautifulSoup(rq.text, 'lxml')













