[](https://pypi.org/project/unidic2ud/)
# UniDic2UD
Tokenizer, POS-tagger, lemmatizer, and dependency-parser for modern and contemporary Japanese, working on [Universal Dependencies](https://universaldependencies.org/format.html).
## Basic usage
```py
>>> import unidic2ud
>>> qkana=unidic2ud.load("qkana")
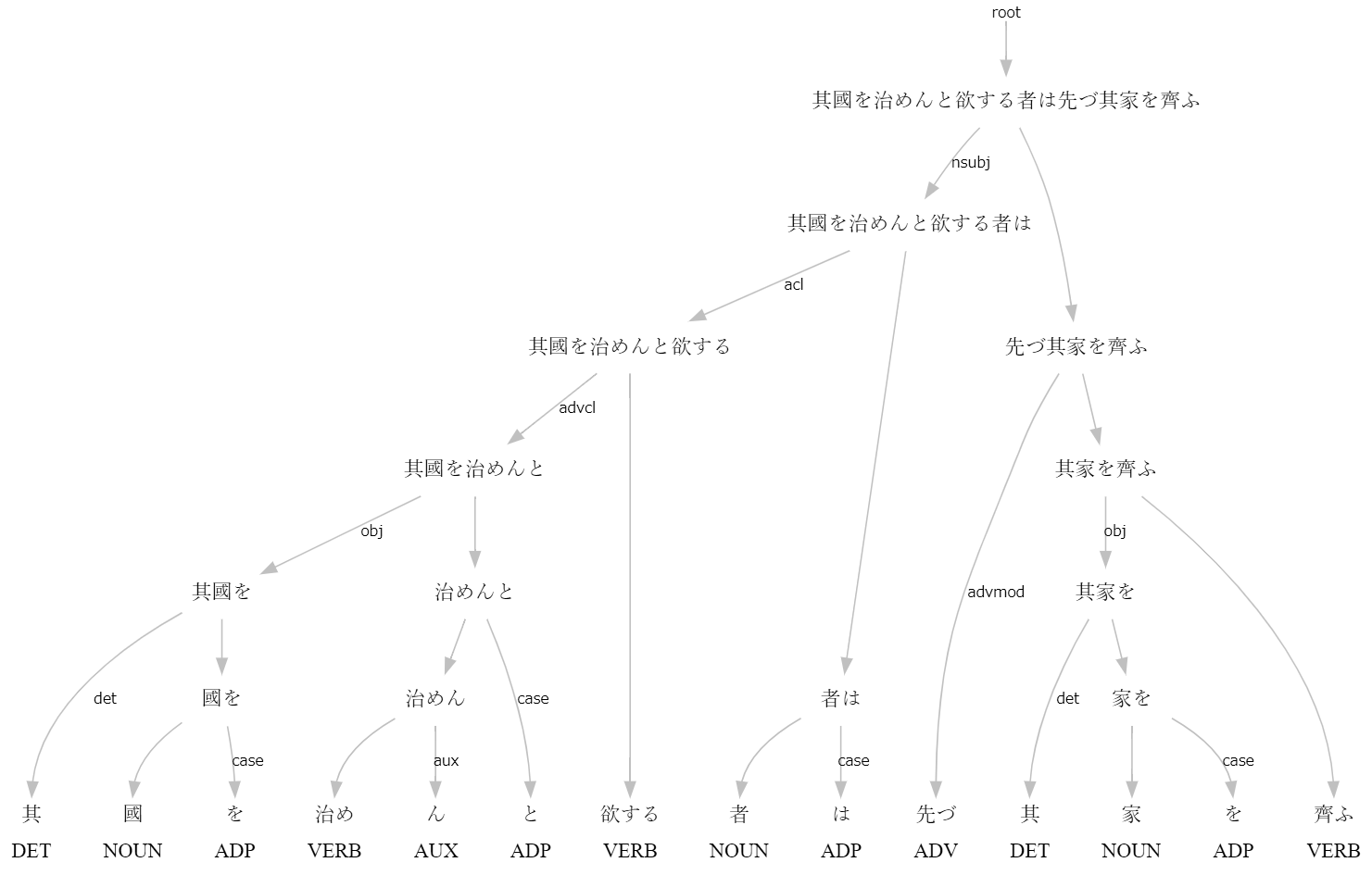
>>> s=qkana("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(s)
# text = 其國を治めんと欲する者は先づ其家を齊ふ
1 其 其の DET 連体詞 _ 2 det _ SpaceAfter=No|Translit=ソノ
2 國 国 NOUN 名詞-普通名詞-一般 _ 4 obj _ SpaceAfter=No|Translit=クニ
3 を を ADP 助詞-格助詞 _ 2 case _ SpaceAfter=No|Translit=ヲ
4 治め 収める VERB 動詞-一般 _ 7 advcl _ SpaceAfter=No|Translit=オサメ
5 ん む AUX 助動詞 _ 4 aux _ SpaceAfter=No|Translit=ン
6 と と ADP 助詞-格助詞 _ 4 case _ SpaceAfter=No|Translit=ト
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
8 者 者 NOUN 名詞-普通名詞-一般 _ 14 nsubj _ SpaceAfter=No|Translit=モノ
9 は は ADP 助詞-係助詞 _ 8 case _ SpaceAfter=No|Translit=ハ
10 先づ 先ず ADV 副詞 _ 14 advmod _ SpaceAfter=No|Translit=マヅ
11 其 其の DET 連体詞 _ 12 det _ SpaceAfter=No|Translit=ソノ
12 家 家 NOUN 名詞-普通名詞-一般 _ 14 obj _ SpaceAfter=No|Translit=ウチ
13 を を ADP 助詞-格助詞 _ 12 case _ SpaceAfter=No|Translit=ヲ
14 齊ふ 整える VERB 動詞-一般 _ 0 root _ SpaceAfter=No|Translit=トトノフ
>>> t=s[7]
>>> print(t.id,t.form,t.lemma,t.upos,t.xpos,t.feats,t.head.id,t.deprel,t.deps,t.misc)
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
>>> print(s.to_tree())
其 <══╗ det(決定詞)
國 ═╗═╝<╗ obj(目的語)
を <╝ ║ case(格表示)
治め ═╗═╗═╝<╗ advcl(連用修飾節)
ん <╝ ║ ║ aux(動詞補助成分)
と <══╝ ║ case(格表示)
欲する ═══════╝<╗ acl(連体修飾節)
者 ═╗═══════╝<╗ nsubj(主語)
は <╝ ║ case(格表示)
先づ <══════╗ ║ advmod(連用修飾語)
其 <══╗ ║ ║ det(決定詞)
家 ═╗═╝<╗ ║ ║ obj(目的語)
を <╝ ║ ║ ║ case(格表示)
齊ふ ═════╝═╝═══╝ root(親)
>>> f=open("trial.svg","w")
>>> f.write(s.to_svg())
>>> f.close()
```

`unidic2ud.load(UniDic,UDPipe)` loads a natural language processor pipeline, which uses `UniDic` for tokenizer POS-tagger and lemmatizer, then uses `UDPipe` for dependency-parser. The default `UDPipe` is `UDPipe="japanese-modern"`. Available `UniDic` options are:
* `UniDic="gendai"`: Use [現代書き言葉UniDic](https://unidic.ninjal.ac.jp/download#unidic_bccwj).
* `UniDic="spoken"`: Use [現代話し言葉UniDic](https://unidic.ninjal.ac.jp/download#unidic_csj).
* `UniDic="qkana"`: Use [旧仮名口語UniDic](https://unidic.ninjal.ac.jp/download_all#unidic_qkana).
* `UniDic="kindai"`: Use [近代文語UniDic](https://unidic.ninjal.ac.jp/download_all#unidic_kindai).
* `UniDic="kinsei"`: Use [近世口語(洒落本)UniDic](https://unidic.ninjal.ac.jp/download_all#unidic_kinsei).
* `UniDic="kyogen"`: Use [中世口語(狂言)UniDic](https://unidic.ninjal.ac.jp/download_all#unidic_kyogen).
* `UniDic="wakan"`: Use [中世文語(説話・随筆)UniDic](https://unidic.ninjal.ac.jp/download_all#unidic_wakan).
* `UniDic="wabun"`: Use [中古和文UniDic](https://unidic.ninjal.ac.jp/download_all#unidic_wabun).
* `UniDic="manyo"`: Use [上代(万葉集)UniDic](https://unidic.ninjal.ac.jp/download_all#unidic_manyo).
* `UniDic=None`: Use `UDPipe` for tokenizer, POS-tagger, lemmatizer, and dependency-parser.
`unidic2ud.UniDic2UDEntry.to_tree()` has an option `to_tree(BoxDrawingWidth=2)` for old terminals, whose Box Drawing characters are "fullwidth".
You can simply use `unidic2ud` on the command line:
```sh
echo 其國を治めんと欲する者は先づ其家を齊ふ | unidic2ud -U qkana
```
## CaboCha emulator usage
```py
>>> import unidic2ud.cabocha as CaboCha
>>> qkana=CaboCha.Parser("qkana")
>>> s=qkana.parse("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(s.toString(CaboCha.FORMAT_TREE_LATTICE))
其-D
國を-D
治めんと-D
欲する-D
者は-------D
先づ-----D
其-D |
家を-D
齊ふ
EOS
* 0 1D 0/0 0.000000
其 連体詞,*,*,*,*,*,其の,ソノ,*,DET O 1<-det-2
* 1 2D 0/1 0.000000
國 名詞,普通名詞,一般,*,*,*,国,クニ,*,NOUN O 2<-obj-4
を 助詞,格助詞,*,*,*,*,を,ヲ,*,ADP O 3<-case-2
* 2 3D 0/1 0.000000
治め 動詞,一般,*,*,*,*,収める,オサメ,*,VERB O 4<-advcl-7
ん 助動詞,*,*,*,*,*,む,ン,*,AUX O 5<-aux-4
と 助詞,格助詞,*,*,*,*,と,ト,*,ADP O 6<-case-4
* 3 4D 0/0 0.000000
欲する 動詞,一般,*,*,*,*,欲する,ホッスル,*,VERB O 7<-acl-8
* 4 8D 0/1 0.000000
者 名詞,普通名詞,一般,*,*,*,者,モノ,*,NOUN O 8<-nsubj-14
は 助詞,係助詞,*,*,*,*,は,ハ,*,ADP O 9<-case-8
* 5 8D 0/0 0.000000
先づ 副詞,*,*,*,*,*,先ず,マヅ,*,ADV O 10<-advmod-14
* 6 7D 0/0 0.000000
其 連体詞,*,*,*,*,*,其の,ソノ,*,DET O 11<-det-12
* 7 8D 0/1 0.000000
家 名詞,普通名詞,一般,*,*,*,家,ウチ,*,NOUN O 12<-obj-14
を 助詞,格助詞,*,*,*,*,を,ヲ,*,ADP O 13<-case-12
* 8 -1D 0/0 0.000000
齊ふ 動詞,一般,*,*,*,*,整える,トトノフ,*,VERB O 14<-root
EOS
```
`CaboCha.Parser(UniDic)` is an alias for `unidic2ud.load(UniDic,UDPipe="japanese-modern")`, and its default is `UniDic=None`. `CaboCha.Tree.toString(format)` has five available formats:
* `CaboCha.FORMAT_TREE`: tree (numbered as 0)
* `CaboCha.FORMAT_LATTICE`: lattice (numbered as 1)
* `CaboCha.FORMAT_TREE_LATTICE`: tree + lattice (numbered as 2)
* `CaboCha.FORMAT_XML`: XML (numbered as 3)
* `CaboCha.FORMAT_CONLL`: Universal Dependencies CoNLL-U (numbered as 4)
You can simply use `udcabocha` on the command line:
```sh
echo 其國を治めんと欲する者は先づ其家を齊ふ | udcabocha -U qkana -f 2
```
`-U UniDic` specifies `UniDic`. `-f format` specifies the output format in 0 to 4 above (default is `-f 0`) and in 5 to 8 below:
* `-f 5`: `to_tree()`
* `-f 6`: `to_tree(BoxDrawingWidth=2)`
* `-f 7`: `to_svg()`
* `-f 8`: [raw DOT](https://graphviz.readthedocs.io/en/stable/manual.html#using-raw-dot) graph through [Immediate Catena Analysis](https://koichiyasuoka.github.io/deplacy/#deplacydot)
Try [notebook](https://colab.research.google.com/github/KoichiYasuoka/UniDic2UD/blob/master/udcabocha.ipynb) for Google Colaboratory.
## Usage via spaCy
If you have already installed [spaCy](https://pypi.org/project/spacy/) 2.1.0 or later, you can use `UniDic` via spaCy Language pipeline.
```py
>>> import unidic2ud.spacy
>>> qkana=unidic2ud.spacy.load("qkana")
>>> d=qkana("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(type(d))
<class 'spacy.tokens.doc.Doc'>
>>> print(unidic2ud.spacy.to_conllu(d))
# text = 其國を治めんと欲する者は先づ其家を齊ふ
1 其 其の DET 連体詞 _ 2 det _ SpaceAfter=No|Translit=ソノ
2 國 国 NOUN 名詞-普通名詞-一般 _ 4 obj _ SpaceAfter=No|Translit=クニ
3 を を ADP 助詞-格助詞 _ 2 case _ SpaceAfter=No|Translit=ヲ
4 治め 収める VERB 動詞-一般 _ 7 advcl _ SpaceAfter=No|Translit=オサメ
5 ん む AUX 助動詞 _ 4 aux _ SpaceAfter=No|Translit=ン
6 と と ADP 助詞-格助詞 _ 4 case _ SpaceAfter=No|Translit=ト
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
8 者 者 NOUN 名詞-普通名詞-一般 _ 14 nsub
PyPI 官网下载 | unidic2ud-2.4.2.tar.gz
版权申诉
195 浏览量
2022-01-30
12:16:46
上传
评论
收藏 9.8MB GZ 举报

 unidic2ud-2.4.2.tar.gz (22个子文件)
unidic2ud-2.4.2.tar.gz (22个子文件)  unidic2ud-2.4.2
unidic2ud-2.4.2  PKG-INFO 13KB unidic2ud.egg-info PKG-INFO 13KB
PKG-INFO 13KB unidic2ud.egg-info PKG-INFO 13KB requires.txt 57B SOURCES.txt 540B entry_points.txt 89B top_level.txt 10B dependency_links.txt 1B unidic2ud cli.py 2KB __main__.py 579B __init__.py 182B cabocha cli.py 2KB __init__.py 134B unidic2cabocha.py 7KB download japanese-modern.udpipe 9.77MB mecabrc 20B conllusvgview.js 19KB spacy unidic2spacy.py 5KB __init__.py 72B unidic2ud.py 15KB setup.cfg 38B setup.py 2KB README.md 11KB
requires.txt 57B SOURCES.txt 540B entry_points.txt 89B top_level.txt 10B dependency_links.txt 1B unidic2ud cli.py 2KB __main__.py 579B __init__.py 182B cabocha cli.py 2KB __init__.py 134B unidic2cabocha.py 7KB download japanese-modern.udpipe 9.77MB mecabrc 20B conllusvgview.js 19KB spacy unidic2spacy.py 5KB __init__.py 72B unidic2ud.py 15KB setup.cfg 38B setup.py 2KB README.md 11KB资源评论













