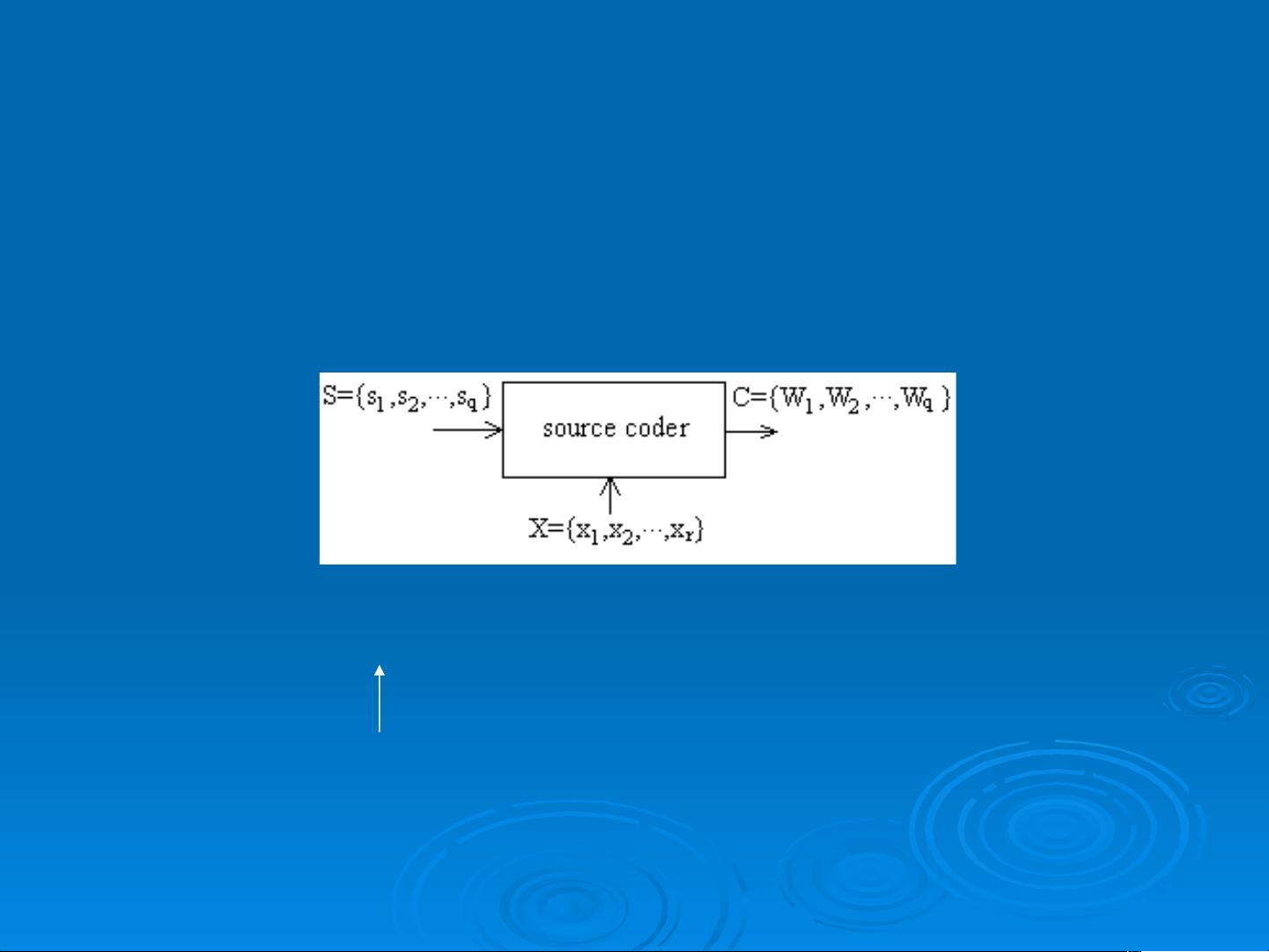
How to code losslessly?
Assuming that the statistical
characteristics of the source can
be ignored, it must satisfy the
following condition.
To get the target of lossless coding, it must
conform to the condition , which
guarantees that there are plenty of code
symbols to be used.
From the condition we can get an inequality,
r
q
N
l
rq
lN
log
log
第 2 页 / 共 34 页
N l
q r