# 先 完整阅读文档!!!
## 项目由来
1. 在调用深度学习训练好的AI模型时,如果使用python调用非常简单,甚至不用编写代码,大部分深度学习框架就是python编写的,自带有推理逻辑文件和方法
2. 但是不是每个同学都会python,不是每个项目都是python语言开发,不是每个岗位都会深度学习
3. 由于大部分服务器项目还是由java语言居多,之前java方向的同学也多,由于找遍全网也没有找到java调用AI模型的例子,
4. 所以特意编写一个java调用AI模型的方法(全网应该就这一份)。思路是通用的,只需要替换不同的模型即可达到不同效果
6. 极其轻量,两个依赖,一个java主文件即可运行
5. **不懂项目有什么用作?不知道用在什么地方?没关系,先下载运行看效果后立马就明白了!**
---
## 环境
- **master分支:面向过程写法,dp分支:面向对象写法。第一次先运行master分支代码**
- 只需要java环境不需要安装其它! 代码目录不能含有中文!
- maven源记得改为国内源,否则下载依赖需要2天。
- CPU建议i7十一代以上,自己测试可以不用GPU,实际项目必须GPU,尽量3060以上(图片检测无所谓,视频流实时检测必须GPU)
- 本项目相当于最基础工具处理方法,不包含和结合业务逻辑,项目使用时视频流需要多线程,队列等等,需要自己处理。
- 不包含视频流处理以及存储,转发等功能,具体实现搜索关键字:流媒体服务器,rtmp 等等。 **思路如下:一个线程拉流,一个或多个线程识别,一个线程推流,一个共变量存储最新画面防止堆积,拉流线程只负责更新最新画面,识别线程只负责识别最新画面,识别后放到队列等待推流线程推流(注意帧率)**
---
## 紧接着下载运行看效果再研究代码,别忘记点star
## 看不懂也要先运行
1. 下载代码可直接运行主文件:`ObjectDetection_1_25200_n.java` , `ObjectDetection_n_7.java`,`ObjectDetection_1_n_8400.java` 都 **可以直接运行不会报错**
2. `CameraDetection.java`,是实时视频流识别检测,**也可直接运行**,三个文件完全独立,不互相依赖,如果有GPU帧率会更高,需要开启调用GPU。images目录下有视频文件也可以改为路径预览视频识别效果,根据视频实时识别demo,其他文件都可以改为实时识别
3. 多个主文件是为了支持不用网络结构的模型,即使是`onnx`模型,输出的结果参数也不一样,目前支持三种结构,下面有讲解
4. 可以封装为`http` `controller` `api`接口,也可以结合摄像头实时分析视频流,进行识别后预览和告警
5. 支持`yolov7` , `yolov5`和`yolov8`,`paddlepaddle`后处理稍微改一下也可以支持, **代码中自带的onnx模型仅仅为了演示,准确率非常低,实际应用需要自己训练**
6. 训练出来的模型成为基础模型,可以用于测试。生产环境的模型需要经过模型压缩,量化,剪枝,蒸馏,才可以使用(当然这不是java开发者的工作)。会提升视频华民啊帧率达到60-120帧左右。点击查看:[百度压缩模型工具](https://www.paddlepaddle.org.cn/tutorials/projectdetail/3949129),[基础概念](https://zhuanlan.zhihu.com/p/138059904),[参考文章](https://zhuanlan.zhihu.com/p/430910227)
8. 视频流检测用小模型,接口图片检测用大模型
6. 替换`model`目录下的onnx模型文件,可以识别检测任何物体(烟火,跌倒,抽烟,安全帽,口罩,人,打架,计数,攀爬,垃圾,开关,状态,分类,等等),有模型即可
7. **模型不是onnx格式怎么办?不要紧张,主流AI框架模型都可以转为onnx格式。怎么转?自己搜!**
---
## ObjectDetection_1_25200_n.java
- `yolov5`
- **85**:每一行`85`个数值,`5`个center_x,center_y, width, height,score ,`80`个标签类别得分(不一定是80要看模型标签数量)
- **25200**:三个尺度上的预测框总和 `( 80∗80∗3 + 40∗40∗3 + 20∗20∗3 )`,每个网格三个预测框,后续需要`非极大值抑制NMS`处理
- **1**:没有批量预测推理,即每次输入推理一张图片

---
## ObjectDetection_n_7.java
- `yolov7`
- **Concatoutput_dim_0** :变量,表示当前图像中预测目标的数量,
- **7**:表示每个目标的七个参数:`batch_id,x0,y0,x1,y1,cls_id,score`

---
## ObjectDetection_1_n_8400.java
- `yolov8`

---
## 暂不直接支持输出结果是三个数组参数的模型(因为不常用)
- 但是这种结构模型可以导出为`[1,25200,85]`或`[n,7]`输出结构,然后就可以使用已有代码调用。
- **yolov5** :导出onnx时增加参数 `inplace=True,simplify=True`(ObjectDetection_1_25200_n.java)
- **yolov7** :导出onnx时增加参数 `grid=True,simplify=True`(ObjectDetection_1_25200_n.java) 或者 `grid=True,simplify=True,end2end=True`(ObjectDetection_n_7.java)


---
## ONNX
Open Neural Network Exchange(ONNX,开放神经网络交换)格式,是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移.
是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch,TensorFlow,PaddlePaddle,MXNet)可以采用相同格式存储模型数据并交互。 ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github.
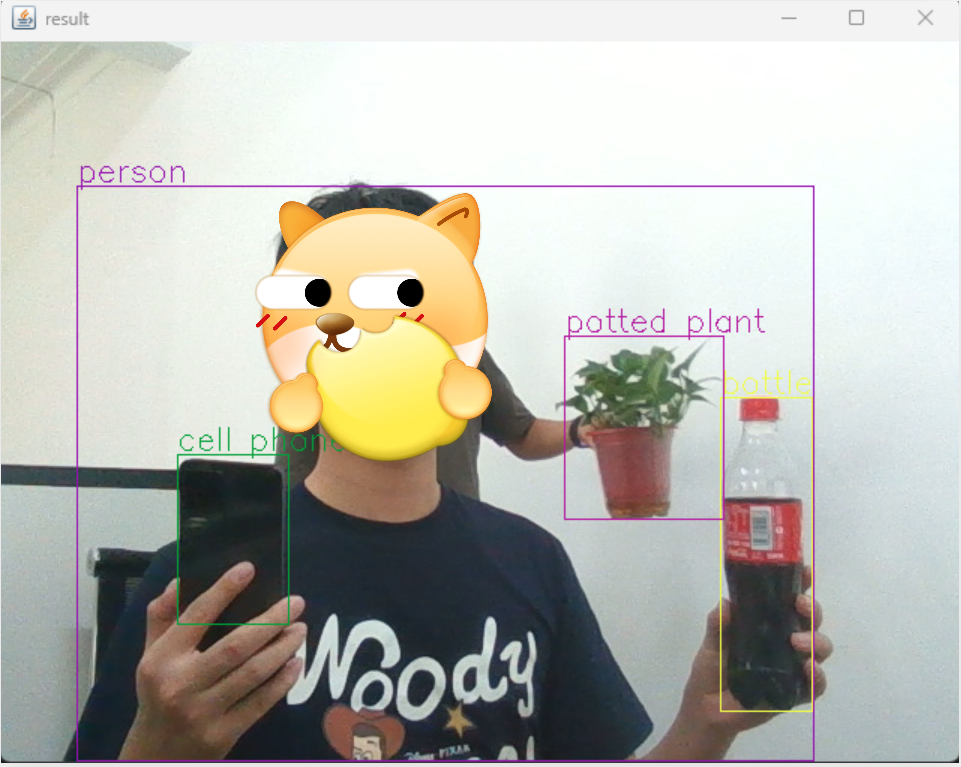
## 图片效果


## 视频效果(必看)
- https://live.csdn.net/v/308058
- https://live.csdn.net/v/296613
- https://blog.csdn.net/changzengli/article/details/129661570
## 扫码加群
- 进群2小时内发运行代码截图,不然踢出群,真踢 (群二维码过期会更新)
- 网友集成本项目案例:https://gitee.com/sprouting/bud-server.git,作者都在群中

## 有用链接
- https://blog.csdn.net/changzengli/article/details/129182528
- https://blog.csdn.net/xqtt29/article/details/110918397
- https://blog.csdn.net/changzengli/article/details/127904594
- 使用封装后的javacpp中的javacv 和 ffmpeg 也可以
## 使用GPU前提
- 更新显卡驱动,显卡驱动一定要最新版本
- 安装对应版本的:cuda 和 cudnn,版本需要和自己电脑上的GPU型号对应,和项目无关
- 并测试是否安装成功,一定要测试: nvcc -V
## 中文解决方案

java 调用 python yolo onnx 模型 AI 视频 识别 支持 yolov5 yolov8 yolov7

版权申诉
 yolo-onnx-java-master.zip (38个子文件)
yolo-onnx-java-master.zip (38个子文件)  yolo-onnx-java-master
yolo-onnx-java-master  pom.xml 2KB src main resources lib opencv_videoio_ffmpeg470_64.dll 25.02MB model helmet_n_7.onnx 23.05MB helmet_1_25200_n.onnx 23.03MB yolov7-tiny.onnx 23.82MB yolov8s.onnx 42.76MB java cn ck ObjectDetection_1_n_8400.java 11KB ObjectDetection_1_25200_n.java 10KB utils Test2.java 4KB RTSPStreamer.java 8KB Letterbox.java 2KB ImageUtil.java 4KB Test1.java 4KB CameraDetection.java 9KB ObjectDetection_n_7.java 6KB domain Detection.java 1KB ODResult.java 2KB config ODConfig.java 2KB LICENSE 11KB demo
pom.xml 2KB src main resources lib opencv_videoio_ffmpeg470_64.dll 25.02MB model helmet_n_7.onnx 23.05MB helmet_1_25200_n.onnx 23.03MB yolov7-tiny.onnx 23.82MB yolov8s.onnx 42.76MB java cn ck ObjectDetection_1_n_8400.java 11KB ObjectDetection_1_25200_n.java 10KB utils Test2.java 4KB RTSPStreamer.java 8KB Letterbox.java 2KB ImageUtil.java 4KB Test1.java 4KB CameraDetection.java 9KB ObjectDetection_n_7.java 6KB domain Detection.java 1KB ODResult.java 2KB config ODConfig.java 2KB LICENSE 11KB demo  3.png 694KB 1.png 2.79MB
3.png 694KB 1.png 2.79MB 5.gif 18.29MB 6.png 369KB 4.png 516KB 8.png 155KB 7.png 320KB 2.png 330KB .gitignore 395B images 20230731102545.png 1.9MB 20230731211649.png 2.24MB 20230731211708.png 1.07MB hard_hat_workers33.png 151KB
5.gif 18.29MB 6.png 369KB 4.png 516KB 8.png 155KB 7.png 320KB 2.png 330KB .gitignore 395B images 20230731102545.png 1.9MB 20230731211649.png 2.24MB 20230731211708.png 1.07MB hard_hat_workers33.png 151KB bus.jpg 476KB 20230810214652.png 2.32MB hard_hat_workers4603.png 270KB 10230731212230.png 3.79MB video
bus.jpg 476KB 20230810214652.png 2.32MB hard_hat_workers4603.png 270KB 10230731212230.png 3.79MB video  car3.mp4 6.9MB README.md 8KB
car3.mp4 6.9MB README.md 8KB资源评论

 m0_685761402024-04-10资源很好用,有较大的参考价值,资源不错,支持一下。
m0_685761402024-04-10资源很好用,有较大的参考价值,资源不错,支持一下。- 2301_775505922024-04-04资源简直太好了,完美解决了当下遇到的难题,这样的资源很难不支持~













