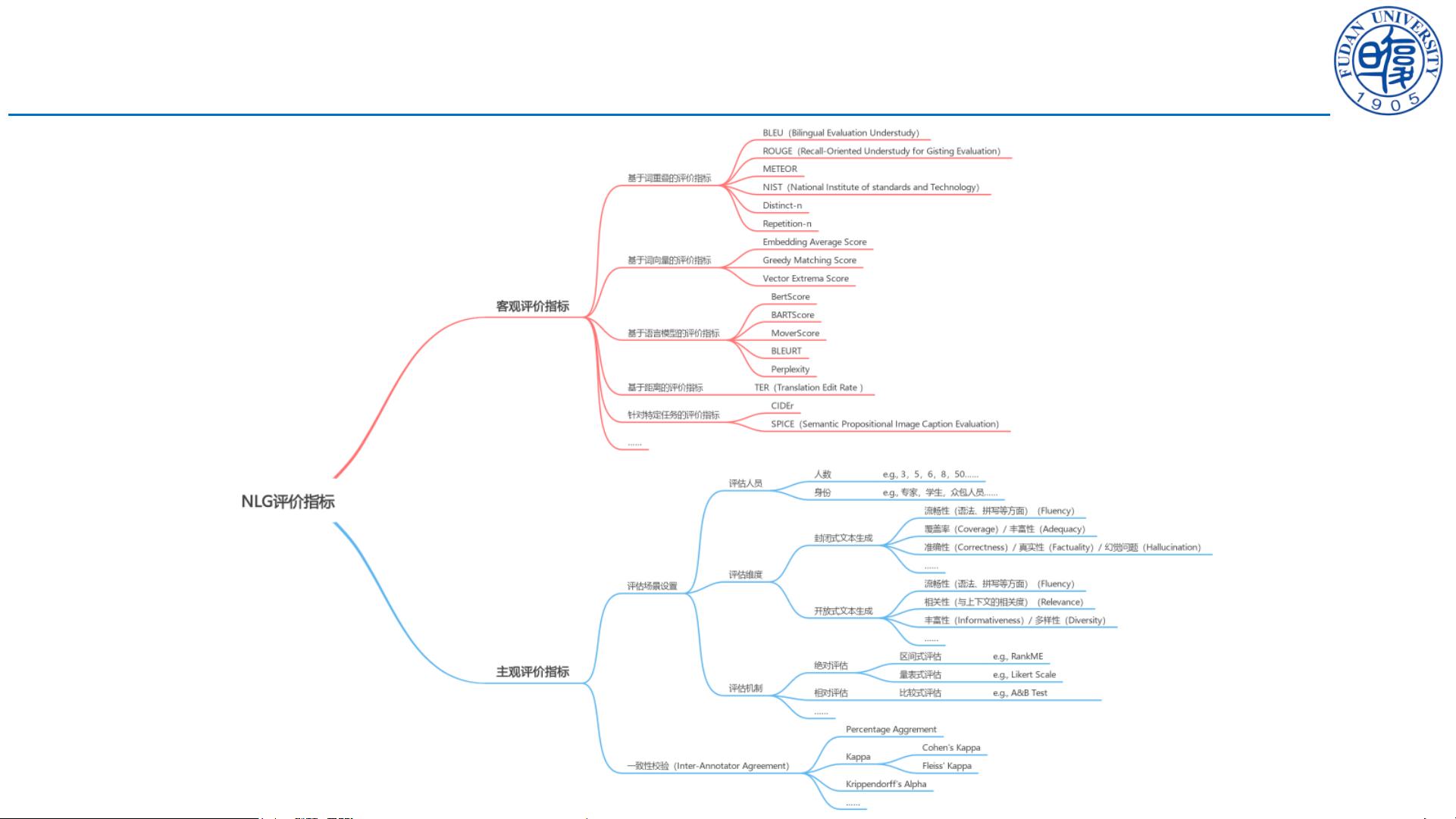
客观评价指标 — 基于词重叠
3
BLEU
关注精确率,计算生成文本中n-gram出现在参照文本中的比例,适用于数据集量级,在句子级表现不佳。
相关论文:Bleu:aMethodforAutomaticEvaluationofMachineTranslation(ACL,2002)
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
是对BLEU的改进,关注召回率,又可细分为ROUGE-N、ROUGE-L、ROUGE-W、ROUGE-S.
相关论文:ROUGE:Recall-orientedunderstudyforgistingevaluation(ACLWorkshp,2004)
METEOR
是对BLEU的改进,考虑了生成文本与参照文本之间的对齐关系,使用WordNet计算特定的序列匹配,同义词,词根和词缀,释义之
间的匹配关系。
相关论文:METEOR:AnAutomaticMetricforMTEvaluationwithImprovedCorrelationwithHumanJudgments(ACLWorkshop,
2005)
NIST(National Institute of standards and Technology)
是对BLEU的改进,引入了每个n-gram的信息量的概念。Tools | NIST