
Bag of Tricks for Image Classification with Convolutional Neural Networks
Tong He Zhi Zhang Hang Zhang Zhongyue Zhang Junyuan Xie Mu Li
Amazon Web Services
{htong,zhiz,hzaws,zhongyue,junyuanx,mli}@amazon.com
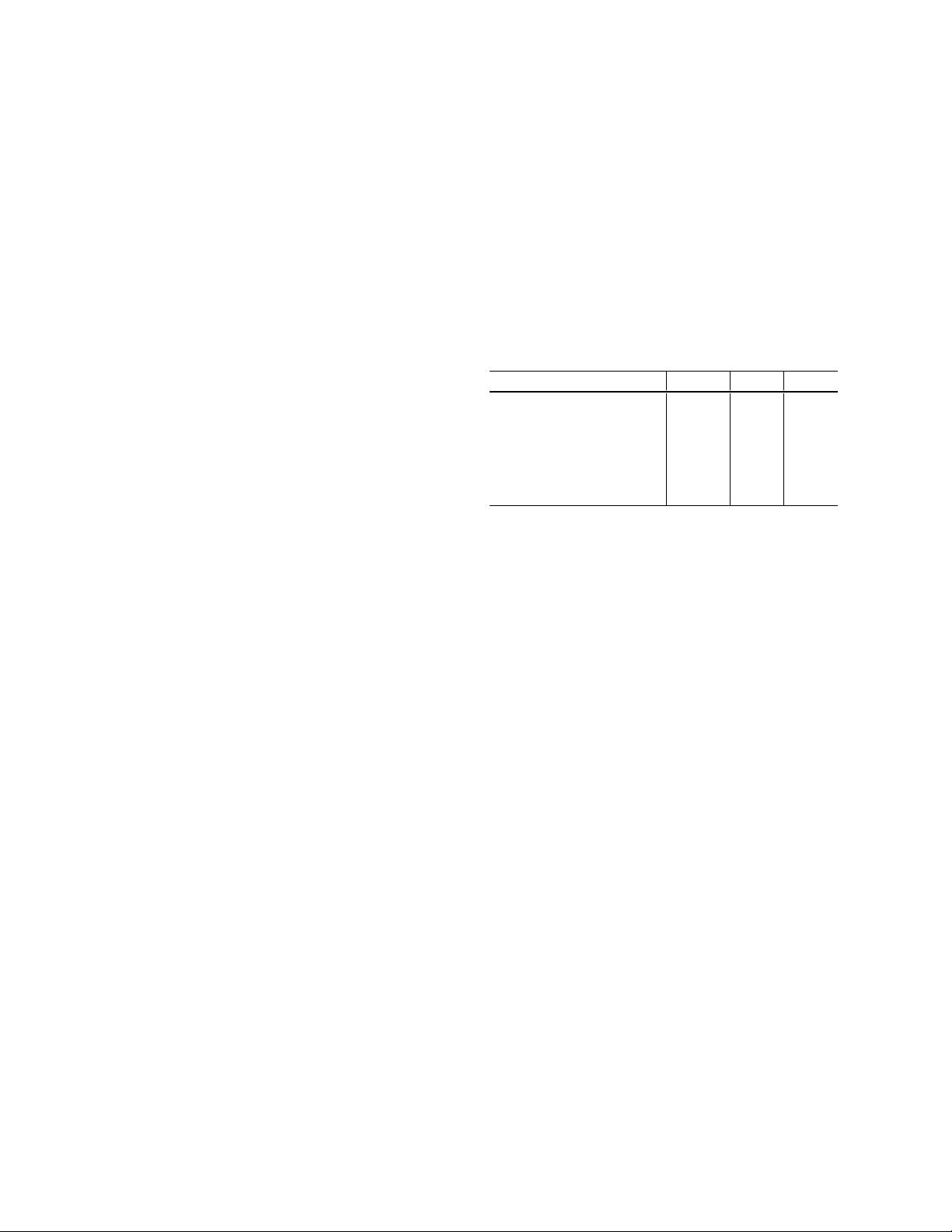
Model FLOPs top-1 top-5
ResNet-50 [9] 3.9 G 75.3 92.2
ResNeXt-50 [27] 4.2 G 77.8 -
SE-ResNet-50 [12] 3.9 G 76.71 93.38
SE-ResNeXt-50 [12] 4.3 G 78.90 94.51
DenseNet-201 [13] 4.3 G 77.42 93.66
ResNet-50 + tricks (ours) 4.3 G 79.29 94.63
Table 1: Computational costs and validation accuracy of
various models. ResNet, trained with our “tricks”, is able
to outperform newer and improved architectures trained
with standard pipeline.
procedure and model architecture refinements that improve
model accuracy but barely change computational complex-
ity. Many of them are minor “tricks” like modifying the
stride size of a particular convolution layer or adjusting
learning rate schedule. Collectively, however, they make a
big difference. We will evaluate them on multiple network
architectures and datasets and report their impact to the final
model accuracy.
Our empirical evaluation shows that several tricks lead
to significant accuracy improvement and combining them
together can further boost the model accuracy. We com-
pare ResNet-50, after applying all tricks, to other related
networks in Table 1. Note that these tricks raises ResNet-
50’s top-1 validation accuracy from 75.3% to 79.29% on
ImageNet. It also outperforms other newer and improved
network architectures, such as SE-ResNeXt-50. In addi-
tion, we show that our approach can generalize to other net-
works (Inception V3 [1] and MobileNet [11]) and datasets
(Place365 [32]). We further show that models trained with
our tricks bring better transfer learning performance in other
application domains such as object detection and semantic
segmentation.
Paper Outline. We first set up a baseline training proce-
dure in Section 2, and then discuss several tricks that are
1
arXiv:1812.01187v2 [cs.CV] 5 Dec 2018
In
this
paper,
we
will
examine
a
collection
of
training
tation
details
while
others
can
only
be
found
in
source
code.
literature,
most
were
only
briefly
mentioned
as
implemen-
past
years,
but
has
received
relatively
less
attention.
In
the
large
number
of
such
refinements
has
been
proposed
in
the
ing,
and
optimization
methods
also
played
a
major
role.
A
ments,
including
changes
in
loss
functions,
data
preprocess-
improved
model
architecture.
Training
procedure
refine-
However,
these
advancements
did
not
solely
come
from
from
62.5%
(AlexNet)
to
82.7%
(NASNet-A).
top-1
validation
accuracy
on
ImageNet
[23]
has
been
raised
trend
of
model
accuracy
improvement.
For
example,
the
NASNet
[34].
At
the
same
time,
we
have
seen
a
steady
NiN
[16],
Inception
[1],
ResNet
[9],
DenseNet
[13],
and
tures
have
been
proposed
since
then,
including
VGG
[24],
ing
approach
for
image
classification.
Various
new
architec-
convolutional
neural
networks
have
become
the
dominat-
Since
the
introduction
of
AlexNet
[15]
in
2012,
deep
1.
Introduction
as
object
detection
and
semantic
segmentation.
learning
performance
in
other
ap-
plication
domains
such
on
image
classification
accuracy
leads
to
better
transfer
ImageNet.
We
will
also
demon-strate
that
improvement
top-1
validation
accuracyfrom75.3%
to
79.29%
on
models
significantly.
Forexample,
we
raise
ResNet-50’s
refinements
together,
weare
ableto
improve
various
CNN
ablation
study.
Wewill
show
that,
by
combining
these
evaluate
their
im-pact
on
the
final
model
accuracy
through
examine
a
collec-tion
of
suchrefinements
and
empirically
details
or
only
vis-ible
in
source
code.
Inthis
paper,
we
will
refinements
are
ei-ther
briefly
mentioned
as
implementation
optimizationmethods.
In
the
literature,
however,
most
refinements,such
as
changes
in
data
augmentations
and
classificationresearch
can
be
credited
to
trainingprocedure
Much
of
the
recent
progress
made
in
image
Abstract

剩余9页未读,继续阅读
资源评论


DeepLearning小舟
- 粉丝: 2431
- 资源: 57









最新资源
- yolox_cfp_s.pth
- CFAR-radar-algorithm-MATLAB-GUI-master.zip
- I2 Localization v2.8.22 f4
- 盒子检测13-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 大黄蜂塔防.exe大黄蜂塔防1.exe大黄蜂塔防2.exe
- 2024大模型在金融行业的落地探索.pptx
- 盒子检测49-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord数据集合集.rar
- IMG_20241224_190113.jpg
- 【安卓源代码】奶牛管理新加功能(完整前后端+mysql+说明文档).zip
- 【安卓源代码】群养猪生长状态远程监测(完整前后端+mysql+说明文档).zip
- 基于分治法的快速排序算法设计与分析报告
- 糖果店冲击.exe糖果店冲击1.exe糖果店冲击2.exe
- 目标靶子检测29-YOLO(v5至v9)、COCO、CreateML、Paligemma、TFRecord数据集合集.rar
- MATLAB优化工具箱使用教程
- simulink-master.zip
- 硬币、塑料、瓶子检测13-YOLO(v7至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


