2015/7/4 SparkPythonAPI函数学习:pysparkAPI(4)–过往记忆
http://www.iteblog.com/archives/1400 1/12
SparkPythonAPI函数学习:pysparkAPI(4)
Python w397090770 2015-07-0417:13:18 4℃ 0评论 [编辑]
分享
作者:过往记忆|新浪微博:左手牵右手TEL|可以转载,但必须以超链接形式标明文章原始出处和作者信息及版权声明
推酷网禁止转载本博客文章
博客地址:http://www.iteblog.com/
文章标题:《SparkPythonAPI函数学习:pysparkAPI(4)》
本文链接:http://www.iteblog.com/archives/1400
Hadoop、Hive、Hbase、Flume等QQ交流群:138615359(已满),请加入新群:149892483
本博客的微信公共帐号为:iteblog_hadoop,欢迎大家关注。如果你觉得本文对你有帮助,不妨分享一次,你的每次
支持,都是对我最大的鼓励
如果本文的内容对您的学习和工作有所帮助,不妨支付宝赞助(wyphao.2007@163.com)一下
2014Spark亚太峰会会议资料下载、《Hadoop从入门到上
手企业开发视频下载[70集]》、《炼数成金-Spark大数据平
台视频百度网盘免费下载》、《Spark1.X大数据平台V2百
度网盘下载[完整版]》、《深入浅出Hive视频教程百度网盘免
费下载》、累了吧,来这里看小说
《SparkPythonAPI函数学习:pysparkAPI(1)》
《SparkPythonAPI函数学习:pysparkAPI(2)》
《SparkPythonAPI函数学习:pysparkAPI(3)》
《SparkPythonAPI函数学习:pysparkAPI(4)》
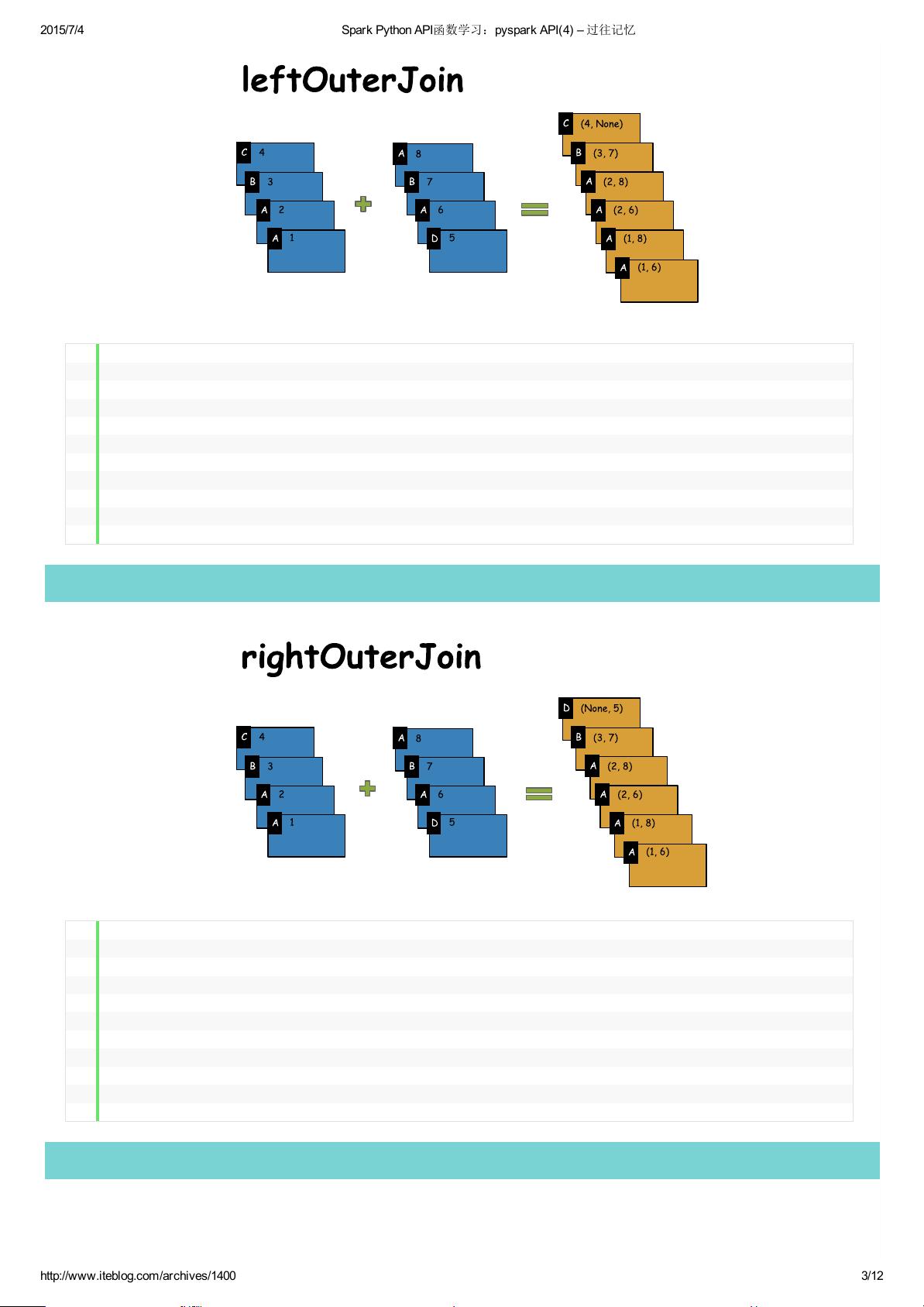
Spark支持Scala、Java以及Python语言,本文将通过图片和简单例子来学习pysparkAPI。