STM32 嵌入式平台上的实现孤立词语音识别系统
摘要:语音识别是机器通过识别和理解过程把人类的语音信号转变为相应文本或命令的技术,其根本目的是研究出一种具有听
觉功能的机器。本设计研究孤立词语音识别系统及其在 STM32 嵌入式平台上的实现。识别流程是:预滤波、ADC、分帧、端点
检测、预加重、加窗、特征提取、特征匹配。端点检测(VAD)采用短时幅度和短时过零率相结合。检测出有效语音后,根据人耳
听觉感知特性,计算每帧语音的 Mel 频率倒谱系数(MFCC)。然后采用动态时间弯折(DTW)算法与特征模板相匹配,最终输出识别结
果。先用 Matlab 对上述算法进行仿真,经多次试验得出算法中所需各系数的最优值。然后将算法移植到 STM32 嵌入式平台,
移植过程中根据嵌入式平台存储空间相对较小、计算能力也相对较弱的实际情况,对算法进行优化。最终设计并制作出基于
STM32 的孤立词语音识别系统。

引 言
从技术上讲,语音识别属于多维模式识别和智能接口的范畴。它是一项集声学、语音学、计算机、信息处理、人工智能等于一
身的综合技术,可广泛应用在信息处理、通信和电子系统、自动控制等领域。
国际上对语音识别的研究始于 20 世纪 50 年代。由于语音识别本身所固有的难度,人们提出了各种条件下的研究任务,并有此
产生了不同的研究领域。这些领域包括:针对说话人,可分为特定说话人语音识别和非特定说话人语音识别;针对词汇量,可
划分为小词汇量、中词汇量和大词汇量的识别,按说话方式,可分为孤立词识别和连续语音等。最简单的研究领域是特定说话
人、小词汇量、孤立词的识别,而最难的研究领域是非特定人、大词汇量、连续语音识别。
在进入新世纪之前,语音识别技术大都只在特定行业或场所中使用或者仅仅停留在实验室,处于探索和试验中。最近十年由于
消费电子行业的兴起和移动互联网技术的爆发。越来越多的自动化和自能化产品走进人们的日常生活。语音识别技术也随之进
入大众的视线,并开始为更多人所了解和使用。例如语音门禁、智能电视上的语音换台、智能手机上的语音拨号、语音控制等
等。语音识别技术正在由过去的实验探索迈入实用化阶段。我们有理由相信会有越来越多的产品用到语音识别技术,它与人工
智能能技术的结合将会是一个重要的发展方向。语音识别技术最终会改变人与机器之间的交互方式,使之更加自然、便捷、轻
松。
本设计的孤立词语音识别是语音识别技术中较为基本的,算法实现也较简单,适合于在嵌入式平台中实现一些简单的语音控制
功能。以往类似系统大都基于 ARM9、ARM11、DSP、SOC 等。这些平台系统规模较大、开发和维护的难度较大、成本也相对较
高。STM32 是意法半导体(ST)公司推出的基于 ARM Cortex-M3 内核的高性能单片机。上市之后,由于其出色的性能、低廉的价
格,很快被运用到众多产品中。经测试,STM32F103VET6 单片机拥有能够满足本系统孤立词语音识别所需的运算和存储能力。
所以在本系统中采用 STM32F103VET6 作为主控制器,采集并识别语音信号。以低廉的成本,高效的算法完成了孤立词语音识
别的设计目标。本系统主要涉及的内容如下述:
语音信号的采集和前端放大、防混叠滤波、模数转换。
语音信号预处理,包括预加重、分帧、加窗。
语音信号端点检测,检测输入信号中有效语音的起始和结束点
语音信号特征提取。提取有效语音中每帧语音信号的 Mel 频率倒谱系数(MFCC)系数。
模板训练,对每个语音指令采集多个语音样本,根据语音样本获取每个语音指令的特征模板。
特征匹配,使用动态时间规整(DWT)算法计算输入语音信号与各模板的匹配距离。识别输入的语音信号。
系统硬件电路设计,人机界面设计。
第一章 方案论证及选择
1.1 系统设计任务要求
本系统利用单片机设计了一个孤立词语音识别系统,能够识别 0~9、 “上”、“下”、“左”、“右”14 个汉语语音指令。系统通过触
摸式 LCD 与用户交互。
本设计的主要要求如下:
1.采集外部声音信号,转换为数字信号并存储。
2.在采集到的声音信号中找出有效语音信号的开始和结束点。
3.分析检测到的有效语音,得出语音信号特征。
4.对每个待识别的语音指令,建立特征模版。
5.比较输入语音信号特征与特征模版,识别输入的语音信号
6.显示系统操作界面,并能够接受用户控制。
1.2 硬件选择
1.2.1 硬件方案总体介绍
系统硬件由音频放大模块、MCU、触摸屏、电源四部分组成。音频放大模块完成对外部声音信号的采集和放大。将声音信号转
化为电信号,并放大到 0~3V。MCU 的 ADC 参考电压为其电源电压 3.3V。音频放大模块的输出信号不超出 MCU ADC 的电压范
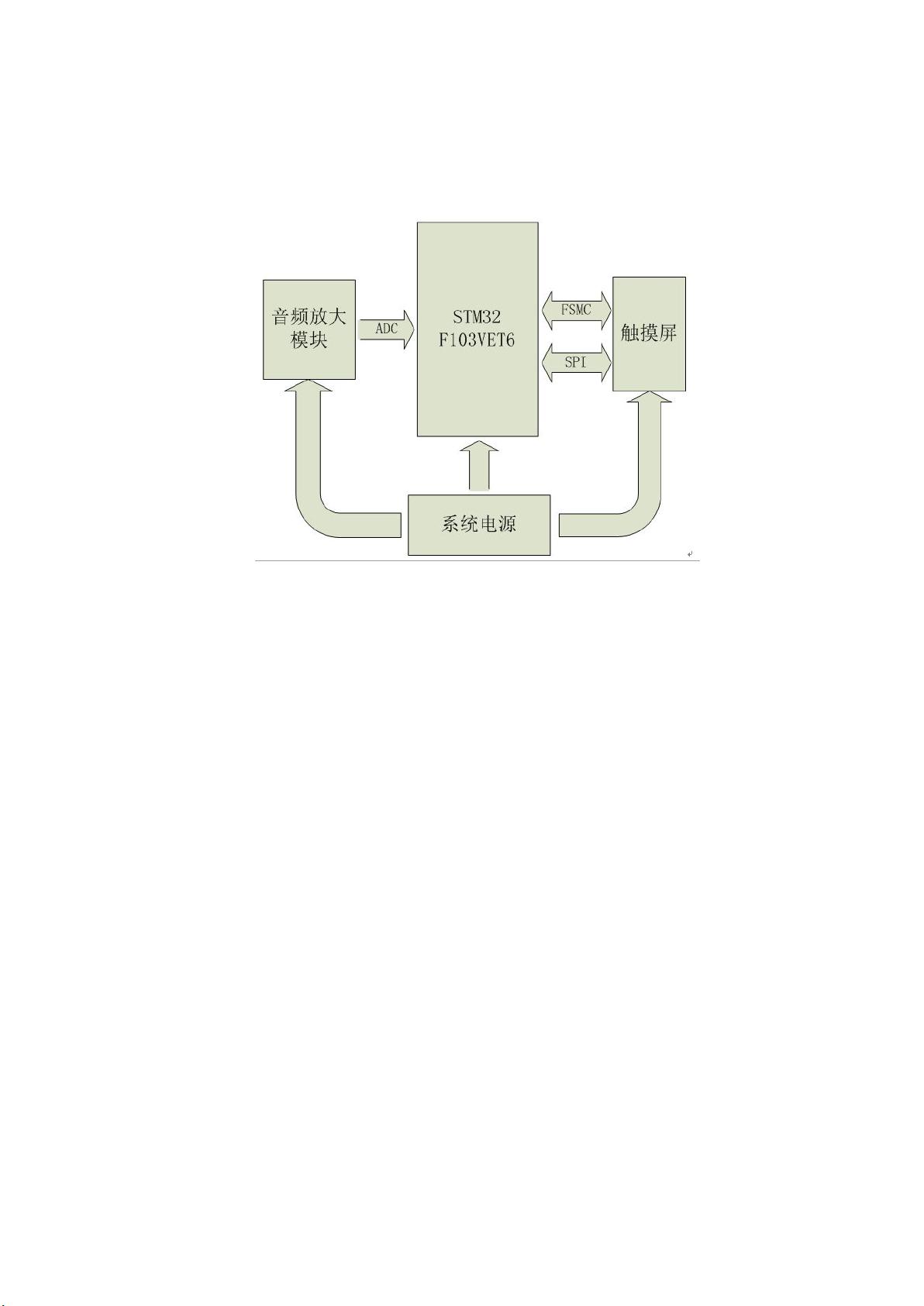
围,并且能够获得最大的量化精度。MCU 对音频放大模块输入的声音信号进行 AD 转换。然后提取并识别信号特征。另外,MCU
还控制触摸屏的显示和读取触摸屏点击位置。触摸屏负责显示操作界面,并接收用户操作。电源为电池供电。
系统硬件结构图如图 1.1 所示。
图 1.1 系统硬件总体结构图
1.2.2 MCU 选择
传统上孤立词语音识别多采用语音识别专用芯片,例如凌阳 SPCE061A、LD3320 等。此种方案设计简单,开发周期较短,但可
拓展性较差,一般只能识别特定的语音,或者识别语音指令的个数有限制。且专用芯片价格一般相对较高,对系统成本控制不
利。
STM32F103VET6 是意法半导体(ST)推出的高性能 32 位 Cortex-M3 内核单片机,带有 ADC、DAC、USB、CAN、SDIO、USART、
SPI、IIC、FSMC、RTC、TIM、GPIO、DMA 等大量片上外设。Cortex-M3 内核属于 ARM 公司推出的最新架构 ARMv7 中的 M 系
列,侧重于低成本、低功耗、高性能。其最高主频可达 72MHz, 1.25 DMIPS/MHz 的运算能力,三级流水线另加分支预测,并
且还带有单周期乘法器和硬件除法器。相比较 ARM7TDMI 内核,Cortex-M3 在性能上有较大的提升。
STM32F103VET6 内置 3 个一共 21 通道的 12 位 ADC,采样频率最高可达 1MHz。12 通道 DMA 控制器,可访问系统 Flash、SRAM、
片上外设,能够处理内存到外设、外设到内存的 DMA 请求。11 个 16 位定时器,其中 T1、T2、T3、T4、T5、T8 可连接到 ADC
控制器,在每次定时器捕获/比较事件到来时自动触发 ADC 开始一次 A/D 转换。A/D 转换完成后可自动触发 DMA 控制器将转换
后的数据依次传送至 SRAM 的数据缓冲区。因此 STM32F103VET6 能够进行精确且高效的 A/D 转换。能够满足音频信号采集的
需求。
STM32F103VET6 的 FSMC(Flexible Static Memory Controller,可变静态存储控制器)能够根据不同的外部存储器类型,发出相应
的数据/地址/控制信号类型以匹配信号的速度。FSMC 连接至 LCD 控制器,可将 LCD 控制器配置为外部 NOR Flash。在系统需要
访问 LCD 时,自动生成满足 LCD 控制器要求的读写时序,能够精确、快速地完成对 LCD 界面显示的控制。内置 3 个最高可达
18Mbit/s 的 SPI 控制器,与触摸屏控制器相连能够实现触摸屏点击位置检测。
本系统中采集一个汉语语音指令。录音时间长度 2s,以 8KHz 16bit 采样率对语音进行采集,所需存储空间为 32KB,另外加上
语音处理、特征提取及特征匹配等中间步骤所需 RAM 空间不会超过 64KB。而 STM32F103VET6 带有 512KB Flash 和 64KB RAM。
所以 STM32F103VET6 在程序空间上能够满足。语音识别中最耗时的部分是特征提取中的快速傅立叶变换换。一般来说,孤立
词语音识别中有效语音时间长度小于 1s。语音信号一般 10~30ms 为一帧,本系统中按 20ms 一帧,帧移(相邻两帧的重叠部分)
10ms,这样一个语音指令不超过 100 帧。在 8KHz 16bit 的采样率下,20ms 为 160 采样点 。STM32 固件库所提供的 16 位、
1024 点 FFT,在内核以 72MHz 运行时每次运算仅需 2.138ms。完成 100 帧数据的 FFT 所需时间为 213.8ms,加上其他处理所

需时间,识别一个语音指令耗时不会超过 0.5s。所以在程序运行时间上 STM32F103VET6 也能够满足需要,能够进行实时的孤
立词语音识别。
基于以上论证,本系统选用 STM32F103VET6 作为主控 MCU。
1.2.3 音频信号采集方案选择
音频信号采集多采用音频编解码芯片,例如 UDA1341、VS1003 等。此类芯片能够提供丰富的功能,且系统一致性较好,但它
们成本较高。本系统是一个低成本解决方案,并且只需要采集音频信号。因此不宜采用那些专用的音频编解码芯片。
在本系统的音频放大模块中使用小型话筒完成声电信号转换,两个 9014 三极管构成两级共基极放大电路。在每一级中加电压负
反馈,稳定放大倍数。
语音信号的频带为 300~3400Hz,根据抽样定理,抽样频率设为 8000Hz 就足以完成对语音信号的采集。在本系统中 TIM1 被设
置为 ADC 触发信号源。TIM 时钟源为系统时钟 72MHz。经 100 分频,变为 720KHz。计数模式为向上递增,自动重载值为 90,
即计数值从 0 递增到 90 再返回 0。比较匹配值设为 0~90 间任意一个数值 ,则每秒可发出 8000 次比较匹配事件。ADC 每秒完
成 8000 次 A/D 转换,即抽样频率为 8KHz。
1.2.4 显示及操作界面选择
触摸屏作为一种新的输入设备,它是目前最简单、方便、自然的一种人机交互方式。LCD 触摸屏是一种可接收触摸点击输入信
号的感应式液晶显示装置。当接触或点击屏幕时,触摸控制器可读取触摸点位置,如此可通过屏幕直接接受用户的操作。相比
较机械式按钮,触摸屏在操作上更加直观生动。综合考虑,本设计中采用 2.5 寸 240×320 分辨率的 LCD 触摸屏实现界面显示和
操作。
1.3 算法选择
1.3.1 软件算法总体介绍
对采集到的音频信号进行预处理、端点检测、特征提取、模板训练、特征匹配的一些列处理,最终识别输入语音。
系统软件流程图如下图所示。
1.3.2 预处理算法选择
语音信号的预处理主要包括: ADC、分帧、数据加窗、预加重。
语音信号的频率范围通常取 100Hz~3400Hz,因为这个频段包含绝大部分的语音信息,对语音识别的意义最大。根据采样定律,
要不失真地对 3400Hz 的信号进行采样,需要的最低采样率是 6800Hz。为了提高精度,常用的 A/D 采样率在 8kHz 到 12kHz。
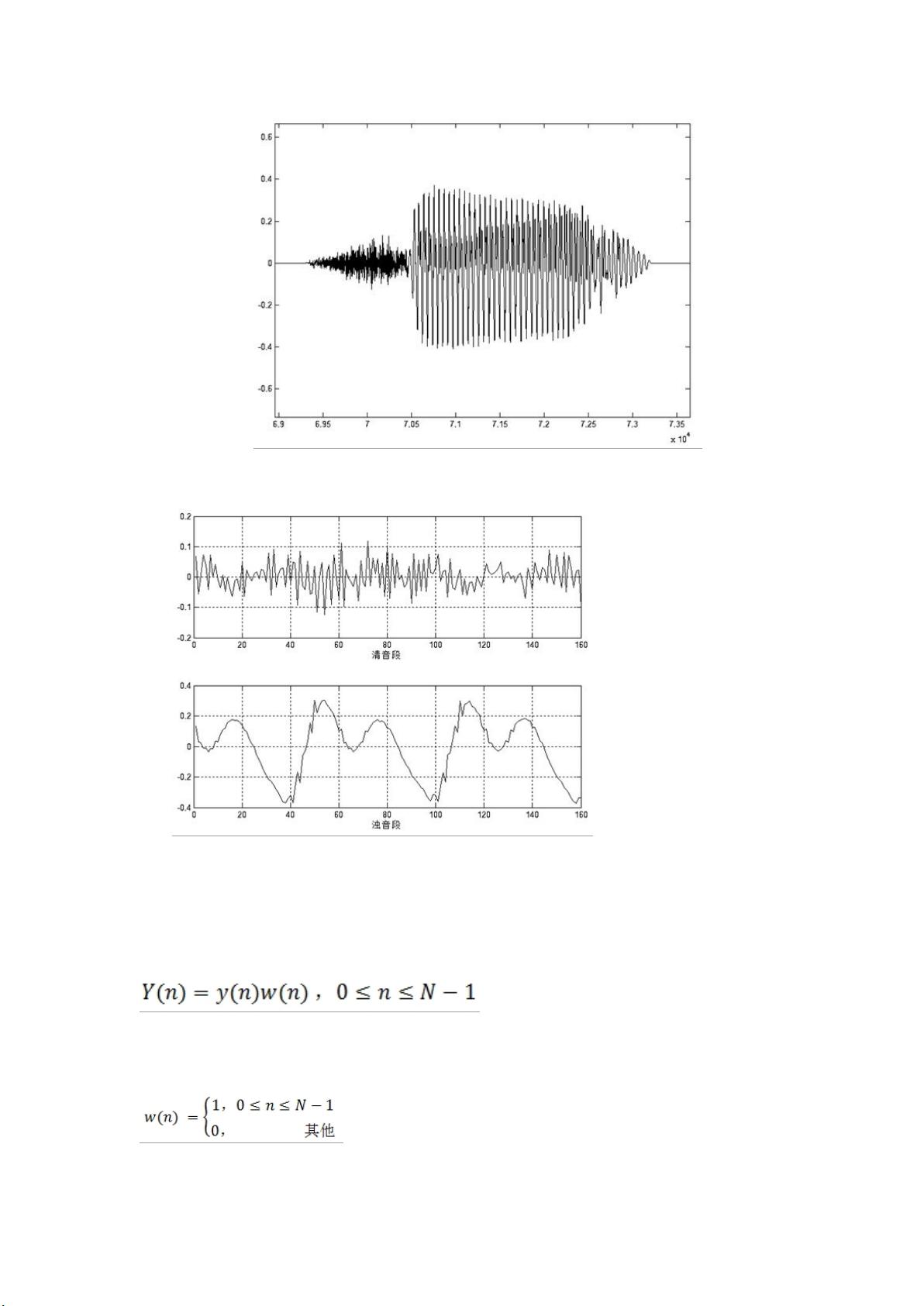
语音信号有一个重要的特性:短时性。由于人在说话中,清音与浊音交替出现,并且每种音通常只延续很短的一段时间。因此,
从波形上看,语音信号具有很强的“时变特性”。在浊音段落中它有很强的周期性,在清音段落中又具有噪声特性,而且浊音和清
音的特征也在不断变化之中。如图 1.4 所示,其特性是随时间变化的,所以它是一个非稳态过程。但从另一方面看,由于语音
的形成过程是与发音器官的运动密切相关的,这种物理性的运动比起声音振动速度来说是缓慢的(如图 1.5 所示)。因此在一
个短时间范围内,其特性变化很小或保持不变,可以将其看做一个准稳态过程。我们可以用平稳过程的分析处理方法来分析处
理语音信号。