# RecruitmentInformationCollectionAndStorageSystem
# 一、实验题目
**HDFS**应用实战——基于**Python爬虫**和**HDFS**的招聘信息采集与存储系统
# 二、实验描述
在本次实验主要完成了一个基于**Python爬虫**和HDFS的招聘信息采集与存储系统,通过自学爬虫的相关知识,使用Python爬取全国最大的互联网招聘网站拉勾网的相关招聘信息,并将爬取的内容用csv格式以日期为单位保存在本地。然后,基于HDFS使用**JavaWeb MVC**、**BootStrap**和**MySQL数据库**开发了一个功能较为完善的招聘信息存储系统,通过该系统用户可以将爬虫采集得到的数据与HDFS直接进行交互和维护。
该系统的主要功能包括**用户注册、用户登录、新建文件夹、删除文件夹、重命名文件夹、移动文件夹、合并文件夹中的文件、上传文件、下载文件、删除文件、重命名文件、移动文件、定时上传文件等**,其中定时上传文件是每隔24小时将前一天爬取到的数据定时上传至HDFS的指定目录下。
# 三、实验目的
通过学习Hadoop、HDFS、MapReduce和Yarn的基本架构和原理,能够熟练地利用Java中提供的相关API对Hadoop和HDFS进行操控,同时进一步掌握对Linux操作系统的使用,为今后的学习和工作打下坚实的基础。
# 四、实验原理
## 4.1网络爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联数据的多样性和资源的有限性,根据用户需求定向抓取网页并分析已成为如今主流的爬取策略。爬虫的本质是模拟浏览器打开网页,获取网页中我们想要的那部分数据。
网络爬虫分为通用网络爬虫和聚焦网络爬虫。通用网络爬虫常应用于搜索引擎中,爬取的目标是在整个互联网中,以下是搜索引擎的原理图。
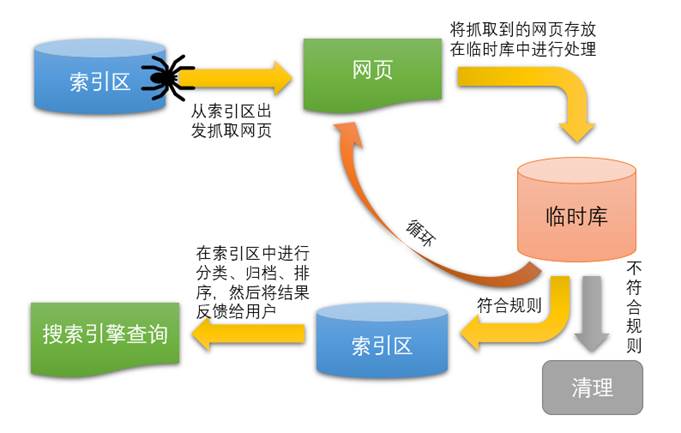
<center>图1 搜索引擎原理图</center>
聚焦网络爬虫是指按照预先定义好的主题有选择地进行网页爬取的一种爬虫,主要应用再对特定信息的抓取中,本次实验采用的就是聚焦网络爬虫。具体流程为

<center>图2 爬虫流程图</center>
## 4.2Hadoop
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范型:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上运行或重新运行。此外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。下图为Hadoop的生态系统。
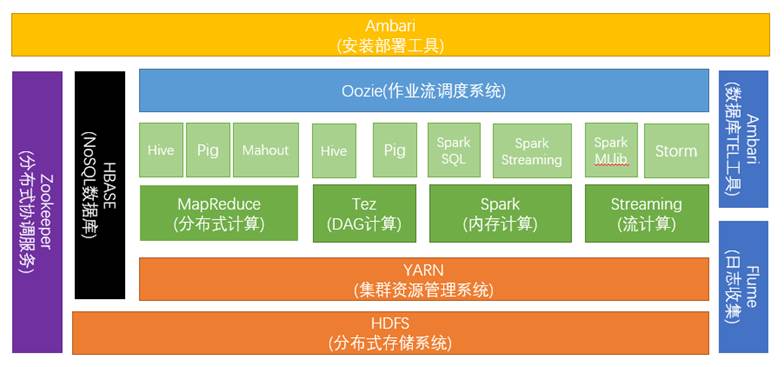
<center>图3 Hadoop生态系统示意图
HDFS,作为Google File System(GFS)的实现,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集的应用处理带来了很多便利。适用、不适用的场景HDFS特点:高容错性、可构建在廉价机器上适合批处理适合大数据处理流式文件访问HDFS局限:不支持低延迟访问不适合小文件存储不支持并发写入不支持修改HDFS架构HDFS由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。下图为HDFS的框架示意图。
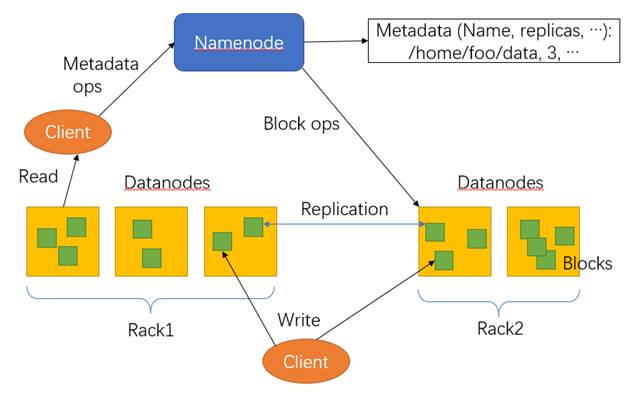
<center>图4 HDFS架构示意图
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于Hadoop 的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,并发运行在一个 Hadoop集群上。MapReduce的有优点包括:易于编程、良好的扩展性、高容错性和适合PB 级以上海量数据的离线处理。缺点包括不擅长实时计算、不擅长流式计算、不擅长DAG(有向无环图)计算。
MapReduce可以拆分为map和reduce两部分,可以简单理解为分久必合。Map:拆分数据先在input split过滤一些没用的东西,剩下的传到Map中,在Map中数据被拆分为一块块,在partition sort 将数据进行排序,然后将所有单元处理好的再简单的合并成一个整体,再将这个整体发送到Reduce。Reduce:合并数据Reduce来计算合并数据,将Map中传过来的相同类型的数据进行一个完整的合并如下图merge,最后输出完整的数据。
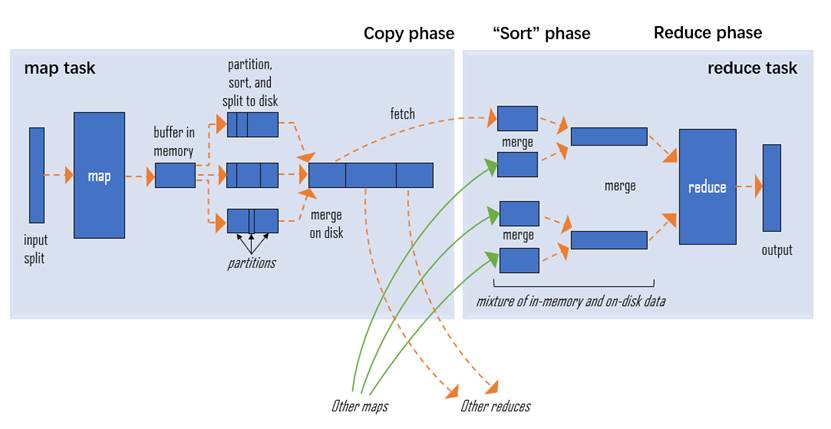
<center>图5 MapReduce流程示意图
YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响,以下是YARN的基础架构示意图。
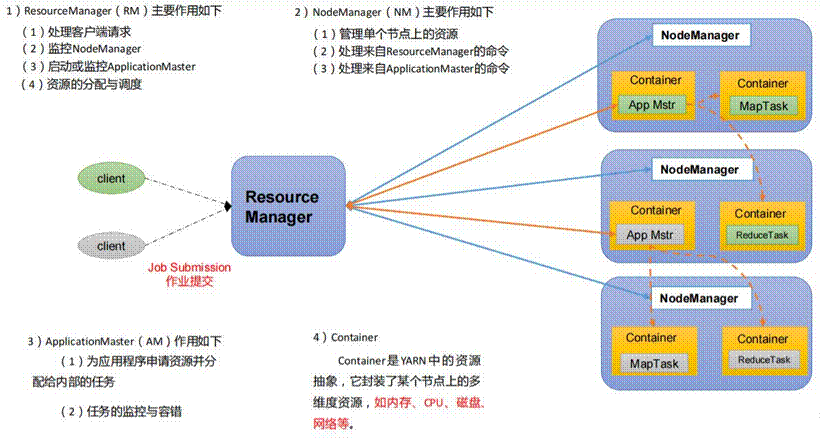
<center>图6 YARN基础架构示意图
## 4.3MVC模式
MVC 模式(Model–View–Controller)是软件工程中的一种软件架构模式,它把软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。MVC 模式的目的是实现一种动态的程序设计,简化后续对程序的修改和扩展,并且使程序某一部分的重复利用成为可能。除此之外,MVC 模式通过对复杂度的简化,使程序的结构更加直观。软件系统在分离了自身的基本部分的同时,也赋予了各个基本部分应有的功能,以下是MVC模式示意图。
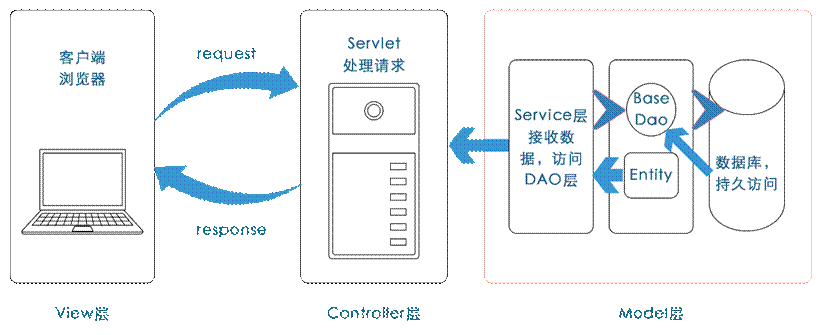
<center>图7 MVC设计模式示意图
## 4.4BootStrap
Bootstrap是美国Twitter公司的设计师Mark Otto和Jacob Thornton合作基于HTML、CSS、JavaScript 开发的简洁、直观、强悍的前端开发框架,使得 We
基于Python爬虫和HDFS的招聘信息采集与存储系统.zip

需积分: 0 104 浏览量
2024-01-10
12:08:33
上传
评论
收藏 119.31MB ZIP 举报
 基于Python爬虫和HDFS的招聘信息采集与存储系统.zip (594个子文件)
基于Python爬虫和HDFS的招聘信息采集与存储系统.zip (594个子文件)  HdfsDaoImpl.class 5KB HdfsDaoImpl.class 5KB UploadServlet.class 3KB UploadServlet.class 3KB LoginServlet.class 3KB LoginServlet.class 3KB BaseDao.class 3KB BaseDao.class 3KB MergeServlet.class 3KB MergeServlet.class 3KB RenameServlet.class 3KB RenameServlet.class 3KB MoveServlet.class 3KB MoveServlet.class 3KB AddDirectoryServlet.class 3KB AddDirectoryServlet.class 3KB DeleteServlet.class 3KB DeleteServlet.class 3KB RegisterServlet.class 3KB RegisterServlet.class 3KB DownloadServlet.class 2KB DownloadServlet.class 2KB TimerUploadServlet.class 2KB TimerUploadServlet.class 2KB UploadFile.class 2KB UploadFile.class 2KB ShowChildDirServlet.class 2KB ShowChildDirServlet.class 2KB HdfsServiceImpl.class 2KB HdfsServiceImpl.class 2KB UserDaoImpl.class 2KB UserDaoImpl.class 2KB User.class 856B User.class 856B UserServiceImpl.class 806B UserServiceImpl.class 806B HdfsService.class 616B HdfsService.class 616B HdfsDao.class 604B HdfsDao.class 604B UserService.class 240B UserService.class 240B UserDao.class 228B UserDao.class 228B bootstrap.css 143KB bootstrap.css 143KB bootstrap.min.css 119KB bootstrap.min.css 119KB bootstrap-theme.css 25KB bootstrap-theme.css 25KB bootstrap-theme.min.css 23KB bootstrap-theme.min.css 23KB bootstrap-admin-theme.css 12KB bootstrap-admin-theme.css 12KB style.css 5KB style.css 5KB data.2021-08-14.csv 5KB data.2021-08-08.csv 3KB data.2021-08-10.csv 3KB data.2021-08-13.csv 3KB data.2021-08-09.csv 3KB data.2021-08-12.csv 3KB data.2021-08-11.csv 3KB glyphicons-halflings-regular.eot 20KB glyphicons-halflings-regular.eot 20KB
HdfsDaoImpl.class 5KB HdfsDaoImpl.class 5KB UploadServlet.class 3KB UploadServlet.class 3KB LoginServlet.class 3KB LoginServlet.class 3KB BaseDao.class 3KB BaseDao.class 3KB MergeServlet.class 3KB MergeServlet.class 3KB RenameServlet.class 3KB RenameServlet.class 3KB MoveServlet.class 3KB MoveServlet.class 3KB AddDirectoryServlet.class 3KB AddDirectoryServlet.class 3KB DeleteServlet.class 3KB DeleteServlet.class 3KB RegisterServlet.class 3KB RegisterServlet.class 3KB DownloadServlet.class 2KB DownloadServlet.class 2KB TimerUploadServlet.class 2KB TimerUploadServlet.class 2KB UploadFile.class 2KB UploadFile.class 2KB ShowChildDirServlet.class 2KB ShowChildDirServlet.class 2KB HdfsServiceImpl.class 2KB HdfsServiceImpl.class 2KB UserDaoImpl.class 2KB UserDaoImpl.class 2KB User.class 856B User.class 856B UserServiceImpl.class 806B UserServiceImpl.class 806B HdfsService.class 616B HdfsService.class 616B HdfsDao.class 604B HdfsDao.class 604B UserService.class 240B UserService.class 240B UserDao.class 228B UserDao.class 228B bootstrap.css 143KB bootstrap.css 143KB bootstrap.min.css 119KB bootstrap.min.css 119KB bootstrap-theme.css 25KB bootstrap-theme.css 25KB bootstrap-theme.min.css 23KB bootstrap-theme.min.css 23KB bootstrap-admin-theme.css 12KB bootstrap-admin-theme.css 12KB style.css 5KB style.css 5KB data.2021-08-14.csv 5KB data.2021-08-08.csv 3KB data.2021-08-10.csv 3KB data.2021-08-13.csv 3KB data.2021-08-09.csv 3KB data.2021-08-12.csv 3KB data.2021-08-11.csv 3KB glyphicons-halflings-regular.eot 20KB glyphicons-halflings-regular.eot 20KB clip_image012.gif 58KB clip_image016.gif 37KB clip_image018.gif 21KB clip_image014.gif 19KB .gitignore 176B hdfstest.iml 3KB 爬虫.ipynb 5KB
clip_image012.gif 58KB clip_image016.gif 37KB clip_image018.gif 21KB clip_image014.gif 19KB .gitignore 176B hdfstest.iml 3KB 爬虫.ipynb 5KB hadoop-hdfs-3.1.3.jar 5.56MB hadoop-hdfs-3.1.3.jar 5.56MB hadoop-hdfs-3.1.3-tests.jar 5.37MB hadoop-hdfs-3.1.3-tests.jar 5.37MB hadoop-hdfs-client-3.1.3.jar 4.83MB hadoop-hdfs-client-3.1.3.jar 4.83MB hadoop-common-3.1.3.jar 3.91MB hadoop-common-3.1.3.jar 3.91MB hadoop-common-3.1.3-tests.jar 2.74MB hadoop-common-3.1.3-tests.jar 2.74MB guava-27.0-jre.jar 2.62MB guava-27.0-jre.jar 2.62MB curator-client-2.13.0.jar 2.31MB curator-client-2.13.0.jar 2.31MB mysql-connector-java-8.0.23.jar 2.3MB mysql-connector-java-8.0.23.jar 2.3MB netty-all-4.0.52.Final.jar 2.17MB netty-all-4.0.52.Final.jar 2.17MB commons-math3-3.1.1.jar 1.53MB commons-math3-3.1.1.jar 1.53MB htrace-core4-4.1.0-incubating.jar 1.43MB htrace-core4-4.1.0-incubating.jar 1.43MB netty-3.10.5.Final.jar 1.27MB netty-3.10.5.Final.jar 1.27MB snappy-java-1.0.5.jar 1.19MB snappy-java-1.0.5.jar 1.19MB jackson-databind-2.7.8.jar 1.15MB jackson-databind-2.7.8.jar 1.15MB
hadoop-hdfs-3.1.3.jar 5.56MB hadoop-hdfs-3.1.3.jar 5.56MB hadoop-hdfs-3.1.3-tests.jar 5.37MB hadoop-hdfs-3.1.3-tests.jar 5.37MB hadoop-hdfs-client-3.1.3.jar 4.83MB hadoop-hdfs-client-3.1.3.jar 4.83MB hadoop-common-3.1.3.jar 3.91MB hadoop-common-3.1.3.jar 3.91MB hadoop-common-3.1.3-tests.jar 2.74MB hadoop-common-3.1.3-tests.jar 2.74MB guava-27.0-jre.jar 2.62MB guava-27.0-jre.jar 2.62MB curator-client-2.13.0.jar 2.31MB curator-client-2.13.0.jar 2.31MB mysql-connector-java-8.0.23.jar 2.3MB mysql-connector-java-8.0.23.jar 2.3MB netty-all-4.0.52.Final.jar 2.17MB netty-all-4.0.52.Final.jar 2.17MB commons-math3-3.1.1.jar 1.53MB commons-math3-3.1.1.jar 1.53MB htrace-core4-4.1.0-incubating.jar 1.43MB htrace-core4-4.1.0-incubating.jar 1.43MB netty-3.10.5.Final.jar 1.27MB netty-3.10.5.Final.jar 1.27MB snappy-java-1.0.5.jar 1.19MB snappy-java-1.0.5.jar 1.19MB jackson-databind-2.7.8.jar 1.15MB jackson-databind-2.7.8.jar 1.15MB共 594 条
- 1
- 2
- 3
- 4
- 5
- 6
资源评论


白话Learning
- 粉丝: 3144
- 资源: 2465









最新资源
- Springboot集成Netflix-ribbon、Enreka实现负载均衡-源码
- 互联网产品项目管理流程-PPT.ppt
- 互联网大数据分析之《用户画像分析》ppt.ppt
- 毕业设计-基于PyQt5、CV、numpy实现的暗通道先验的方法进行图像去雾python源码+文档说明
- 基于暗通道先验的图像去雾算法,可以通过ESP32-CAM进行图像采集python源码+视频(课程设计)
- 基于Pyortch+python+三种卷积神经实现的深度神经网络的交通标志识别算法python源码+文档说明+数据集
- 深度学习课程设计-基于虚拟仿真环境下的自动驾驶交通标志识别python源码+文档说明+数据+模型权重
- 互联网金融第二章——互联网金融支付-PPT.ppt
- 基于OpenCV实现的交通标志识别C++源码+文档说明+测试图片(课程设计)
- 基于虚拟仿真环境下的自动驾驶交通标志识别python源码+文档说明+截图演示+数据集+使用教学(98分高分毕业设计)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


