
elasticsearch基础
一、前言
1.关于搜索引擎的概念
搜索引擎是什么?
关于索引
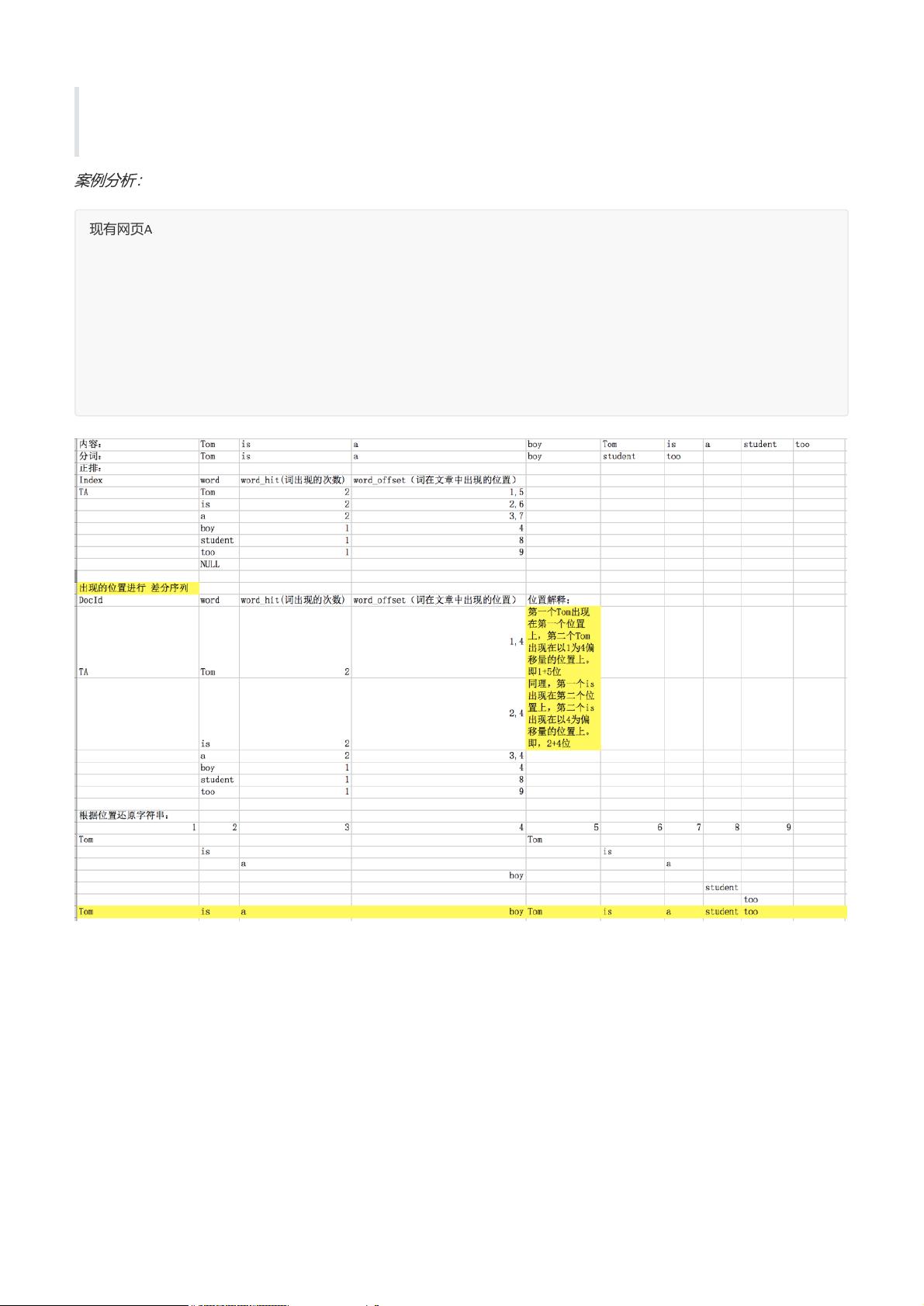
在搜索引擎中数据被找到之后就会建立索引,以方便未来为用户提供快速的搜索。那么在工作中经常会有人问
到你的索引(index)是正排的 还是 倒排的…下面我们来讲解一下索引:
1.1正排索引
正排索引是指文档ID为key,表中记录每个关键词出现的次数,查找时扫描表中的每个文档中字的信息,直到找
到所有包含查询关键字的文档。
1.2倒排索引
搜索引擎(Search engine)是指根据一定的策略、运用特定的计算程序从互联网上搜集信息,在对信息进行组织和
处理后,为用户提供检索服务,将用户检索的信息展示给用户的系统。
一个搜索引擎由搜索器、索引器、检索器、用户接口四个部分组成。
搜索器 在互联网中漫游,发现和搜集信息
索引器 理解搜索器搜索的信息,从中抽取索引项,用于表示文档以及生成文档库的索引表
检索器 根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实
现某种用户相关性反馈机制。
用户接口 输入用户查询、显示查询结果、提供用户相关性反馈机制
全文搜索引擎(全文检索):全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描
文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先
建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。
- 按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字
有不同的含义。 比如英文中字与词实际上是合一的,而中文中字就是字,词都是由多个字组词。
- 按词检索是指对文章中的词(语义单位)建立索引,检索时按词检索,并且可以处理同义项等。
英文等西方文字由于是按照空格切分词,因此实现上与按字处理类似,添加同义处理也很容易。
中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题是当前全文检索技术尤其是中文检索
技术中的难点。
一般来说,全文检索需要具备 建立索引 和 提供查询 的基本功能。

剩余26页未读,继续阅读
资源评论


卷小毛丶
- 粉丝: 0
- 资源: 4









最新资源
- 毕设和企业适用springboot智慧交通平台类及物流管理平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及信息管理系统源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及远程教育平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及虚拟现实体验平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及用户行为分析平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及职业技能培训平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及智能客服系统源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及智能农场管理系统源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及自动化测试平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧教育平台类及AR技术平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧交通平台类及智能图像识别系统源码+论文+视频.zip
- 毕设和企业适用springboot智慧教育平台类及共享经济平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧教育平台类及大数据云平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧教育平台类及电子产品维修平台源码+论文+视频.zip
- 毕设和企业适用springboot智慧教育平台类及健康数据分析系统源码+论文+视频.zip
- 5Pin插针设备工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


