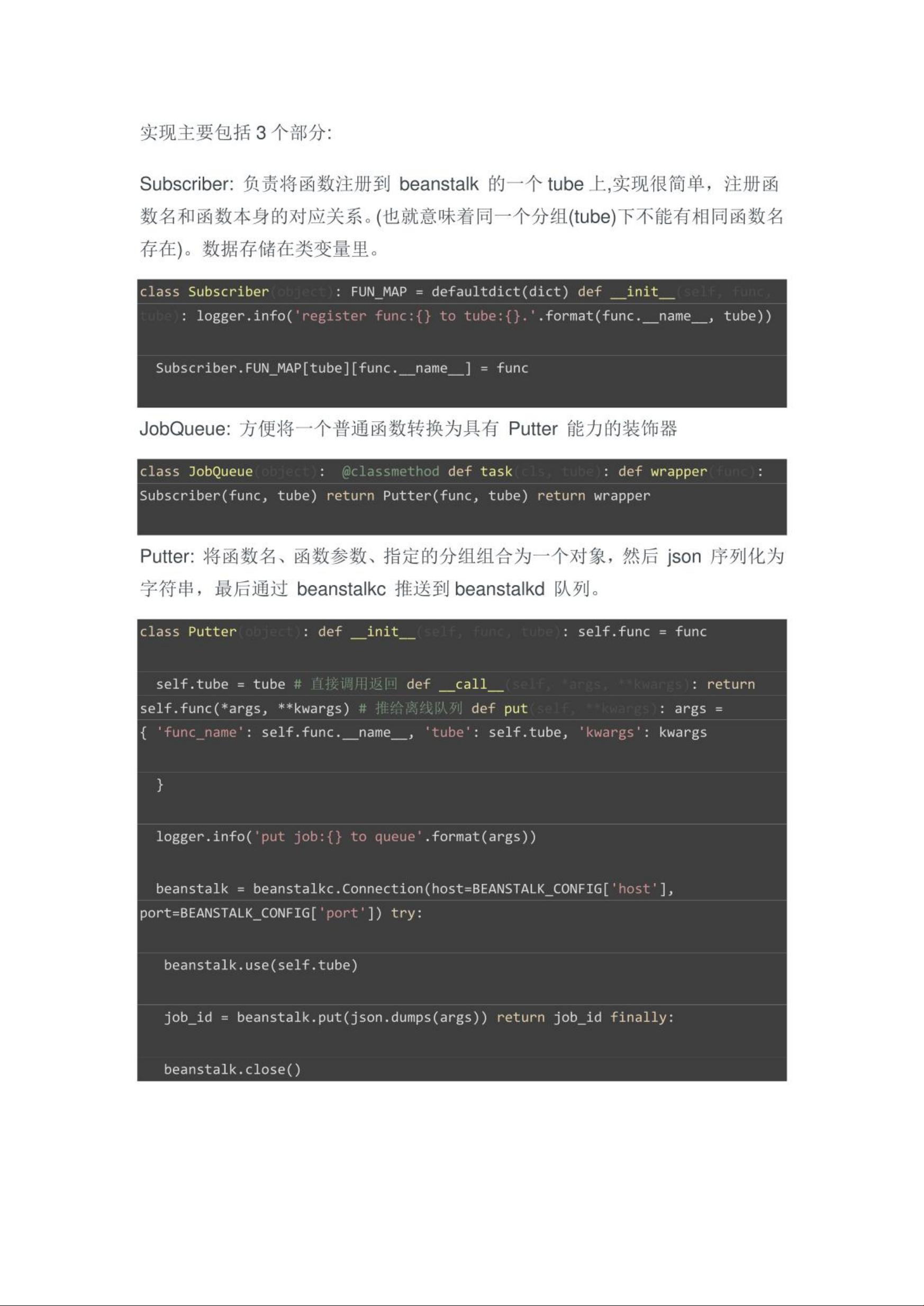
Python使用Beanstalkd进行异步任务处理是一种高效且灵活的策略,尤其在处理大量I/O密集型或计算密集型任务时。Beanstalkd是一个轻量级的、高性能的队列服务器,它专注于速度和简单性,是实现异步任务处理的理想选择。下面将详细介绍如何在Python中使用Beanstalkd。
你需要安装`beanstalkc`,这是一个Python客户端库,用于与Beanstalkd服务器通信。可以使用pip来安装:
```bash
pip install beanstalkc
```
安装完成后,你可以通过以下方式连接到Beanstalkd服务器:
```python
import beanstalkc
conn = beanstalkc.Connection(host='localhost', port=11300)
conn.connect()
```
在Python中使用Beanstalkd的基本流程包括四个步骤:生产者发布任务、Beanstalkd存储任务、消费者从队列中获取任务并处理、以及完成任务后删除任务。
1. **生产者发布任务**:
生产者是创建任务的代码部分,它将任务数据包装成一个字符串或字节,并使用`put`方法将其放入Beanstalkd的tube(管道)中。tube是Beanstalkd中的任务容器,可以看作是一个命名的任务队列。
```python
conn.use('mytube') # 使用名为'mytube'的tube
conn.put(json.dumps({'task': 'do_something'})) # 将任务数据序列化并放入队列
```
2. **Beanstalkd存储任务**:
Beanstalkd接收到任务后,会将其持久化存储并等待消费者处理。你可以设置优先级、延迟时间、TTR(time-to-run)等属性,以便控制任务的执行顺序和超时处理。
3. **消费者获取任务**:
消费者是执行任务的代码部分,它们从Beanstalkd的tube中`reserve`任务,处理完成后执行`delete`操作。
```python
job = conn.reserve() # 获取任务
task_data = json.loads(job.body) # 反序列化任务数据
do_something(task_data) # 执行任务
job.delete() # 完成任务后删除
```
4. **错误处理与任务重试**:
如果消费者在处理任务时遇到问题,可以决定是否让任务重新进入队列。这可以通过抛出异常并捕获,或者在`delete`之前调用`release`来实现。`release`可以设置延迟时间,让任务稍后再被尝试。
```python
try:
do_something(task_data)
except Exception as e:
print(f"Error: {e}")
job.release推迟=5 # 延迟5秒后再次尝试
```
此外,为了实现更复杂的任务调度和负载均衡,可以使用多个消费者实例,甚至结合其他工具如Celery,提供分布式任务处理和任务跟踪功能。
在实际应用中,Python和Beanstalkd的组合可以用于各种场景,如电子邮件发送、数据处理、爬虫任务调度等。通过这种方式,你可以确保即使在高并发的情况下,系统也能保持响应,避免阻塞主线程,提升整体性能。
Python配合Beanstalkd提供了一种强大的异步任务处理机制,允许开发者将耗时操作解耦出来,实现非阻塞的、高效的后台处理,从而提高应用的稳定性和用户体验。了解并熟练掌握这一技术,对于优化Python应用性能至关重要。


 Python使用Beanstalkd做异步任务处理的方法共5页.pdf.zip (1个子文件)
Python使用Beanstalkd做异步任务处理的方法共5页.pdf.zip (1个子文件)  赚钱项目
赚钱项目  Python使用Beanstalkd做异步任务处理的方法共5页.pdf 666KB
Python使用Beanstalkd做异步任务处理的方法共5页.pdf 666KB