### 大语言模型的低比特计算
#### 一、引言与背景
随着人工智能技术的飞速发展,尤其是自然语言处理领域内的突破性进展,大语言模型(Large Language Models, LLMs)已经成为推动该领域发展的核心力量之一。然而,随着模型规模的不断扩大,其对计算资源的需求也急剧增加,这不仅限制了模型的应用场景,还带来了高昂的成本问题。为了解决这一挑战,低比特计算作为一种有效的方法被提出并广泛研究。
#### 二、大语言模型及其挑战
##### 1. 自回归大语言模型
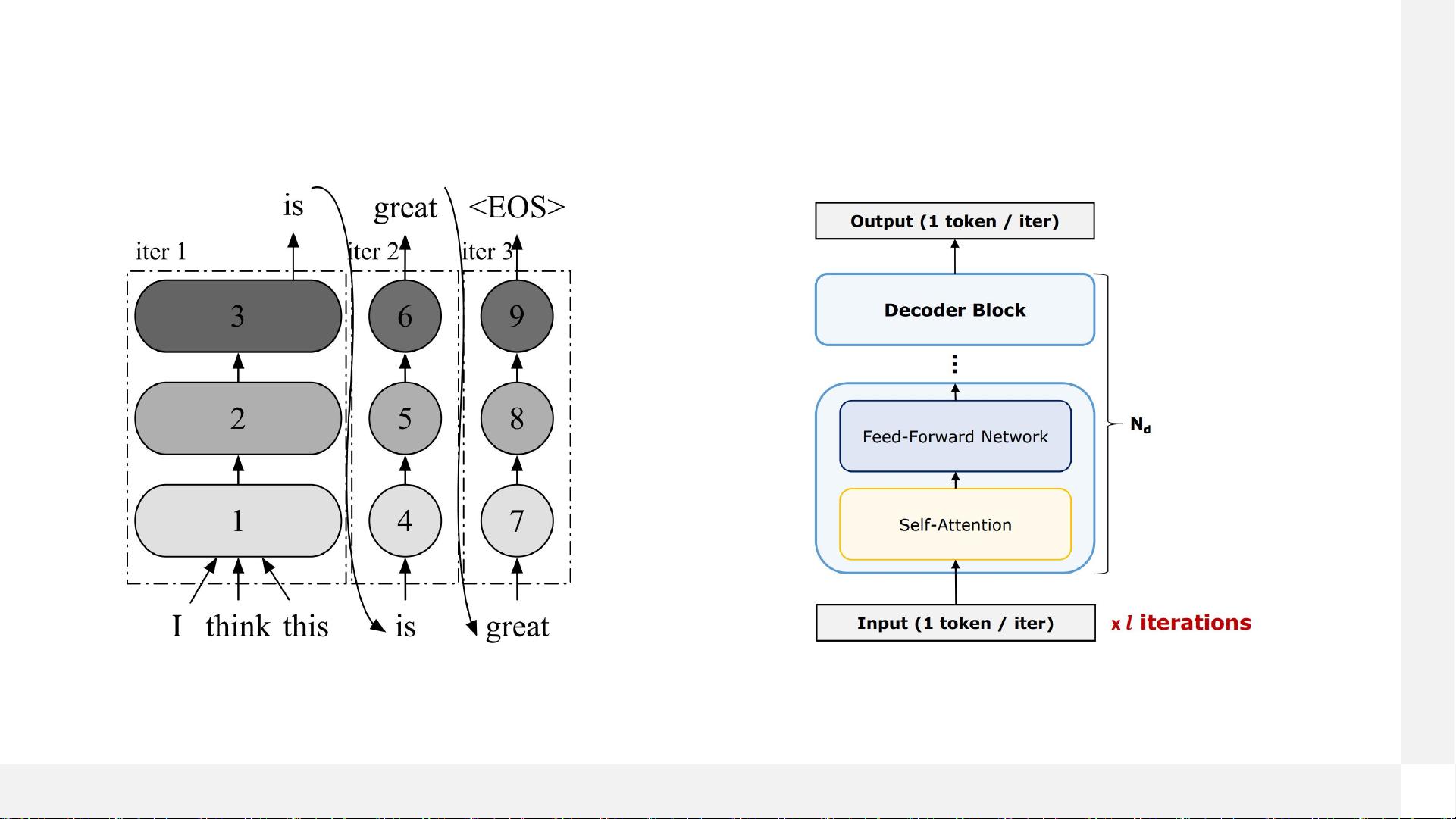
自回归大语言模型是基于Transformer解码器架构的一种模型,其通过预测序列中的下一个词来生成连续文本。这类模型在诸如文本生成、机器翻译等任务中表现出色。
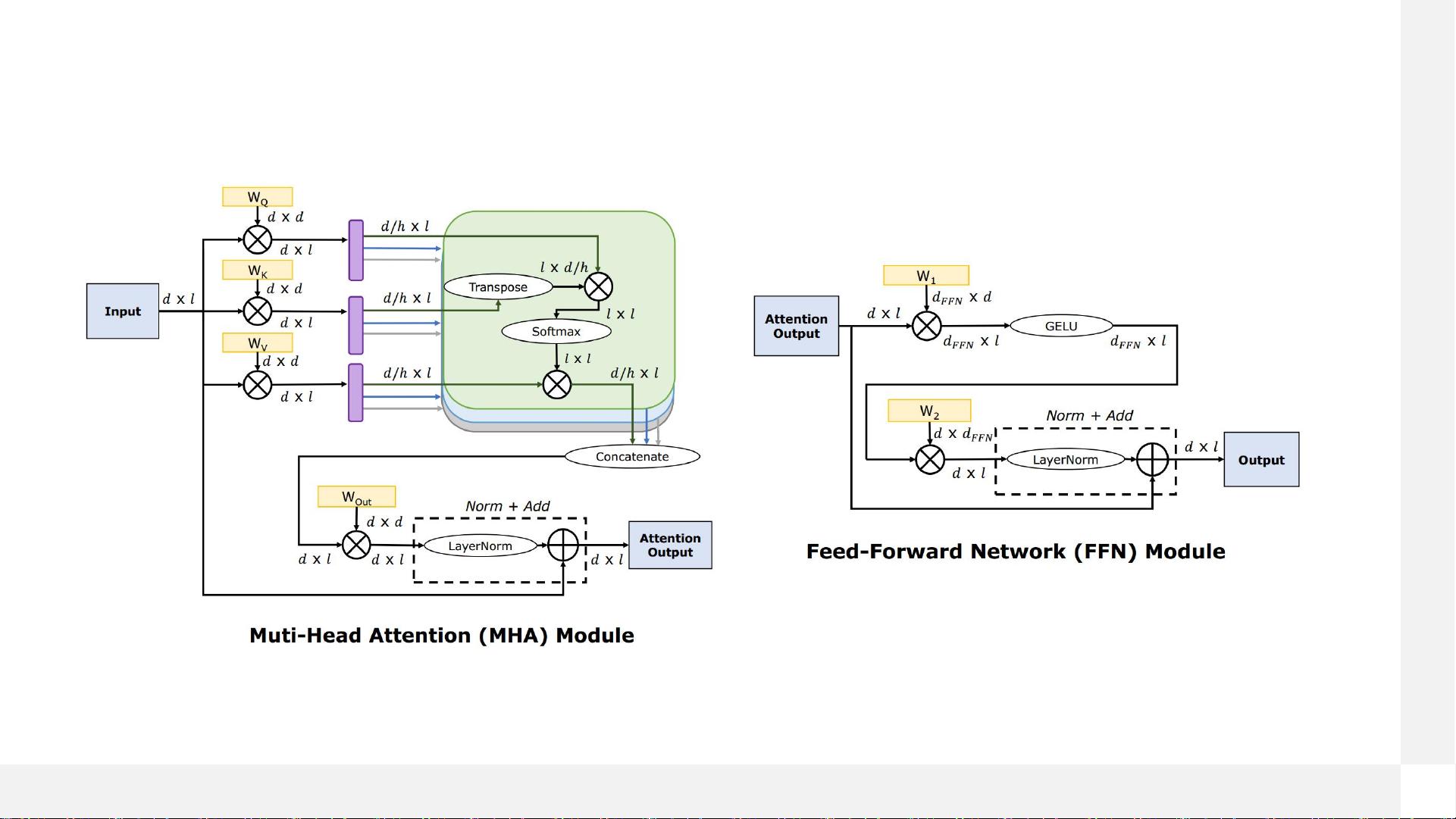
##### 2. Transformer解码器架构
- **训练阶段**:在训练过程中,模型需要处理大量数据,并且每次前向传播都需要计算所有位置的词之间的关系。
- **推理阶段**:
- **第一个token/Prefill**:对于一个新输入的序列,模型需要先进行初始化预测,即“预填充”步骤。
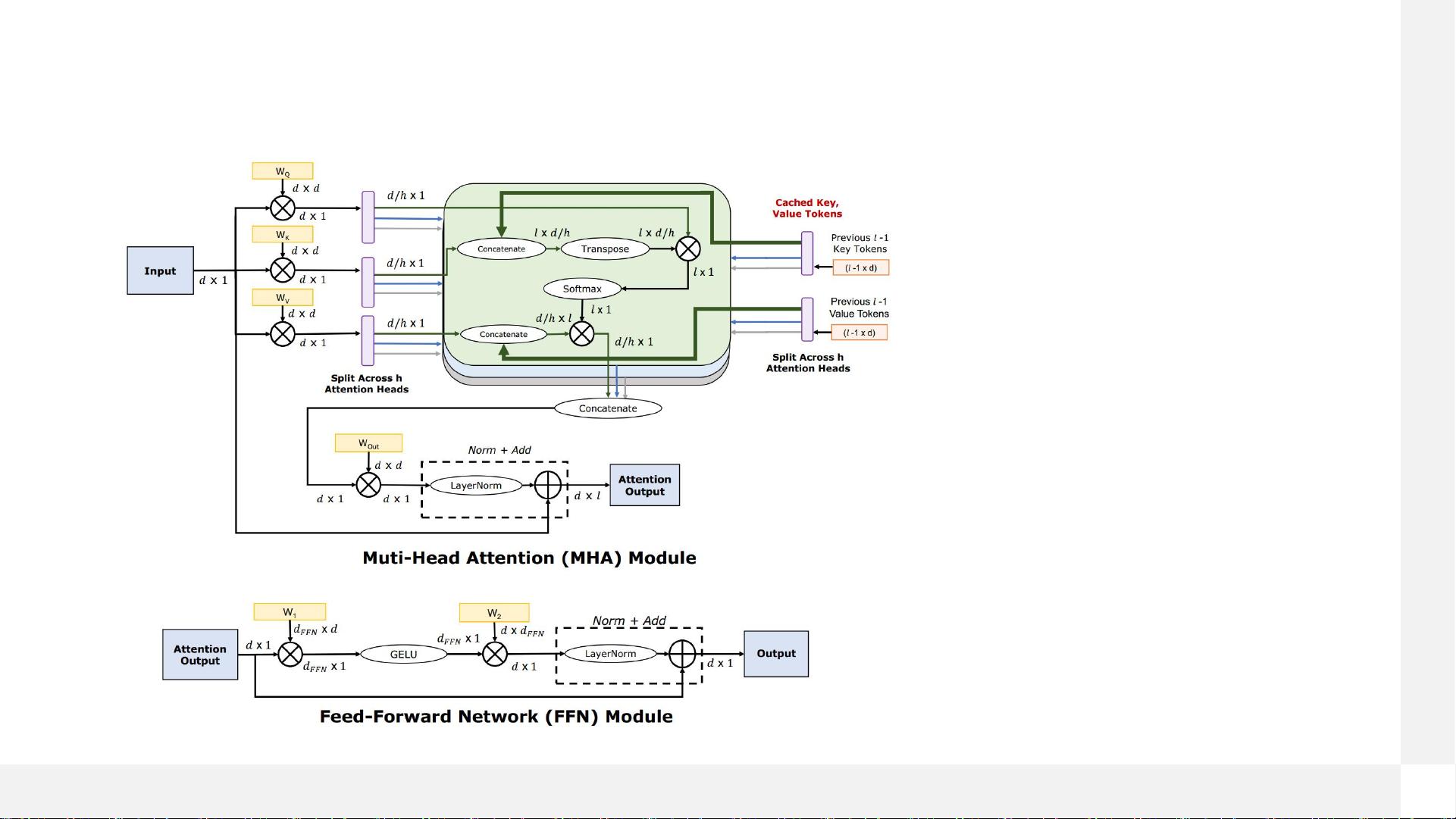
- **下一个token/Decode**:之后,模型根据之前预测的词继续生成新的词。
##### 3. 大语言模型的瓶颈
- **内存带宽**:大型语言模型通常需要大量的内存带宽来进行高效的数据传输。
- **计算能力**:高精度的浮点运算需求增加了计算复杂度。
- **显存大小**:存储庞大的模型参数和中间结果需要大量的显存。
- **分布式计算**:为了处理大规模数据集,通常采用分布式训练方法,但这也带来了通信开销的问题。
#### 三、低比特计算策略
针对上述挑战,低比特计算成为一种有效的解决方案,主要包括以下几个方面:
##### 1. 模型量化/压缩 (WxAy)
- **权重量化**:减少权重表示所需的比特数。
- **激活量化**:减少激活函数输出的比特数。
- **混合精度训练**:结合多种精度的数据类型进行训练,以平衡准确性和计算效率。
##### 2. 数据类型 (INTx, FPx, NFx)
- **整型(INTx)**:如INT8、INT4等,适用于模型量化后的权重存储。
- **浮点型(FPx)**:如FP16、FP32等,提供较高的精度,适合模型训练初期。
- **新型格式(NFx)**:如BF16、FP8等,在保证一定精度的同时减少了存储空间需求。
##### 3. 低比特算子
开发专门针对低比特数据类型的算子,以提高计算效率。
##### 4. 显存使用量
通过减少模型参数和中间结果的存储需求来降低显存消耗。
##### 5. 微调 (QLoRA, QA-LORA, …)
利用特定的微调技术,如QLoRA等,可以在保持模型性能的同时进一步压缩模型大小。
##### 6. 生态系统 (DeepSpeed, vLLM, LangChain, …)
这些工具和框架支持低比特计算,简化了开发流程,提高了开发效率。
#### 四、BigDL-LLM:轻量级大模型开源加速库
BigDL-LLM 是一个基于英特尔 XPU(包括CPU和GPU)平台的开源加速库,它提供了以下特性:
- **支持标准PyTorch模型和API**:使得现有应用可以轻松迁移到BigDL-LLM上。
- **模型压缩**:支持多种压缩技术,如llama.cpp、GPTQ等。
- **低比特优化**:支持多种低比特数据类型,如FP4、INT4等。
- **模型格式**:兼容GGUF、AWQ等多种模型格式。
- **低比特微调**:支持QLoRA、QA-LoRA等技术。
#### 五、案例分析
BigDL-LLM 在不同硬件平台上展现了出色的性能表现:
- **Intel笔记本**:支持在配备12代Intel酷睿处理器的笔记本上运行chatglm2-6B模型。
- **Intel锐炫显卡**:支持在Intel Arc A770显卡上运行LLaMA2-13B等大型语言模型。
- **英特尔至强 CPU**:支持在4代至强可扩展CPU上运行LLaMA2-70B等模型。
- **英特尔 Flex GPU**:支持FastChat等应用。
#### 六、性能评估
通过对不同精度设置下的模型进行评估,可以看出低比特计算在保证较高精度的同时显著提升了计算效率。例如,对于LLaMa模型的不同精度设置:
- **BF16**:较高的精度设置,但在某些任务上的表现略逊于FP16。
- **INT8**:相比于BF16,INT8在大多数任务上仅损失了约1%的准确率,但计算效率更高。
- **INT4**:进一步降低了精度要求,虽然准确率有所下降,但仍然保持了较高的性能水平。
通过上述分析可以看出,低比特计算是一种非常有前景的技术方向,不仅可以大幅度减少计算资源的需求,还能提高计算效率。随着技术的不断发展和完善,未来低比特计算将在大语言模型的训练和部署中发挥更加重要的作用。