个人 2024春节flink总结
需积分: 5 128 浏览量
2024-02-17
06:46:45
上传
评论
收藏 1.48MB DOCX 举报

38
Apache Flink 是一个在
有界
数据流和
无界
数据流上进行有状态计算分布式处理引擎和框架。Flink
设计旨在
所有常见的集群环境
中运行,以
任意规模
和
内存
级速度执行计算。
第 1 章 Flink 快速上手
1.1
Flink vs Spark
1.1.1
数据处理架构
从根本上说,Spark 和 Flink 采用了完全不同的数据处理方式。可以说,两者的世界观是
截然相反的。
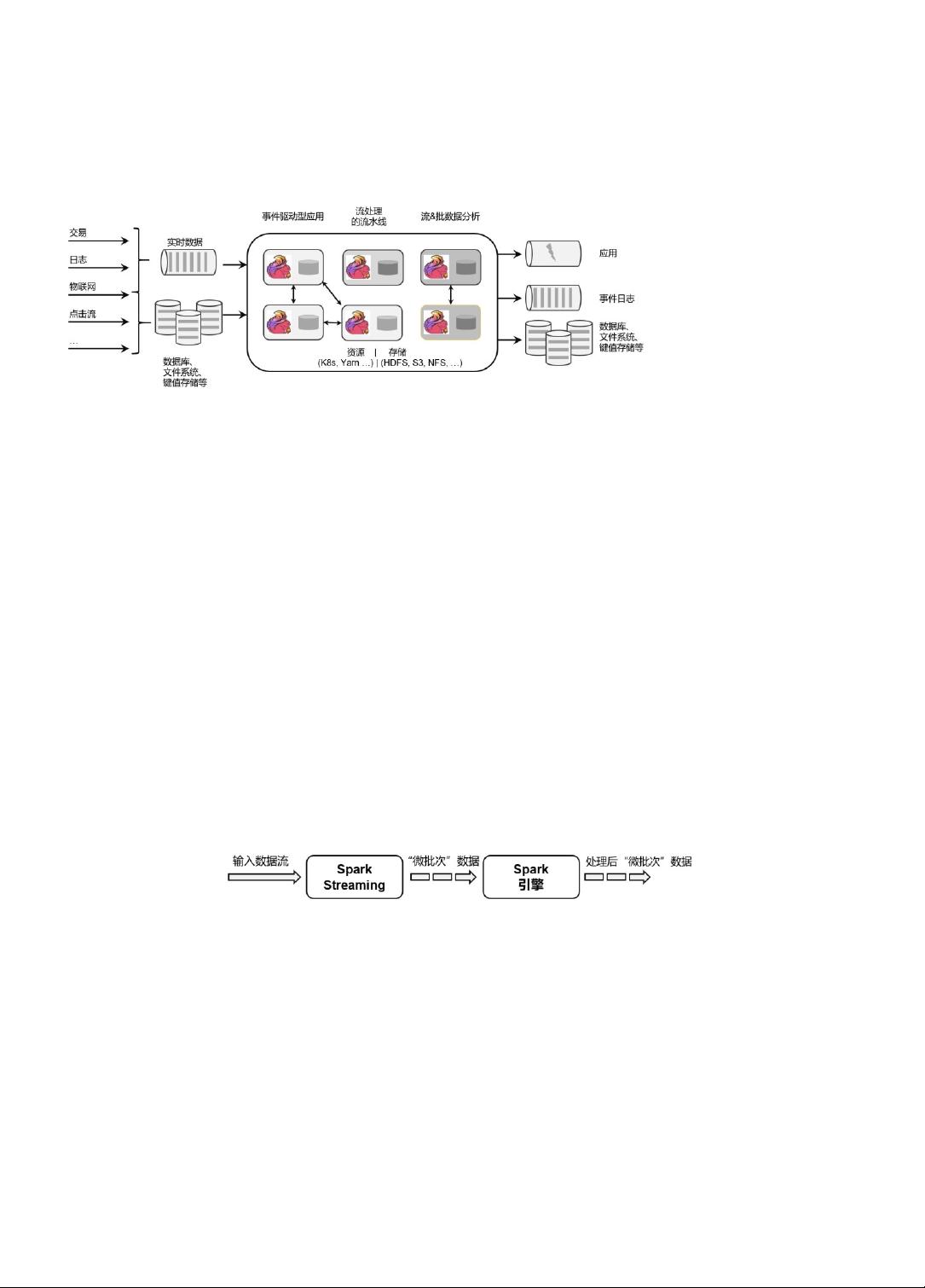
Spark 以批处理为根本,并尝试在批处理之上支持流计算;在 Spark 的世界观中,万物皆
批次,离线数据是一个大批次,而实时数据则是由一个一个无限的小批次组成的。所以对于流处
理框架 Spark Streaming 而言,其实并不是真正意义上的“流”处理,而是“微批次”
(micro-batching)处理,如图 1-8 所示。。
图 1-8 Spark Streaming 流处理示意
而 Flink 则认为,流处理才是最基本的操作,批处理也可以统一为流处理。在 Flink 的世
界观中,万物皆流,实时数据是标准的、没有界限的流,而离线数据则是有界限的流。
1. 无界数据流(Unbounded Data Stream)
所谓无界数据流,就是有头没尾,数据的生成和传递会开始但永远不会结束,如图 1-9 所示。
我们无法等待所有数据都到达,因为输入是无界的,永无止境,数据没有“都到达”的时候。所
以对于无界数据流,必须连续处理,也就是说必须在获取数据后立即处理。在处理无界流时,为
了保证结果的正确性,我们必须能够做到按照顺序处理数据。



剩余40页未读,继续阅读
资源评论













