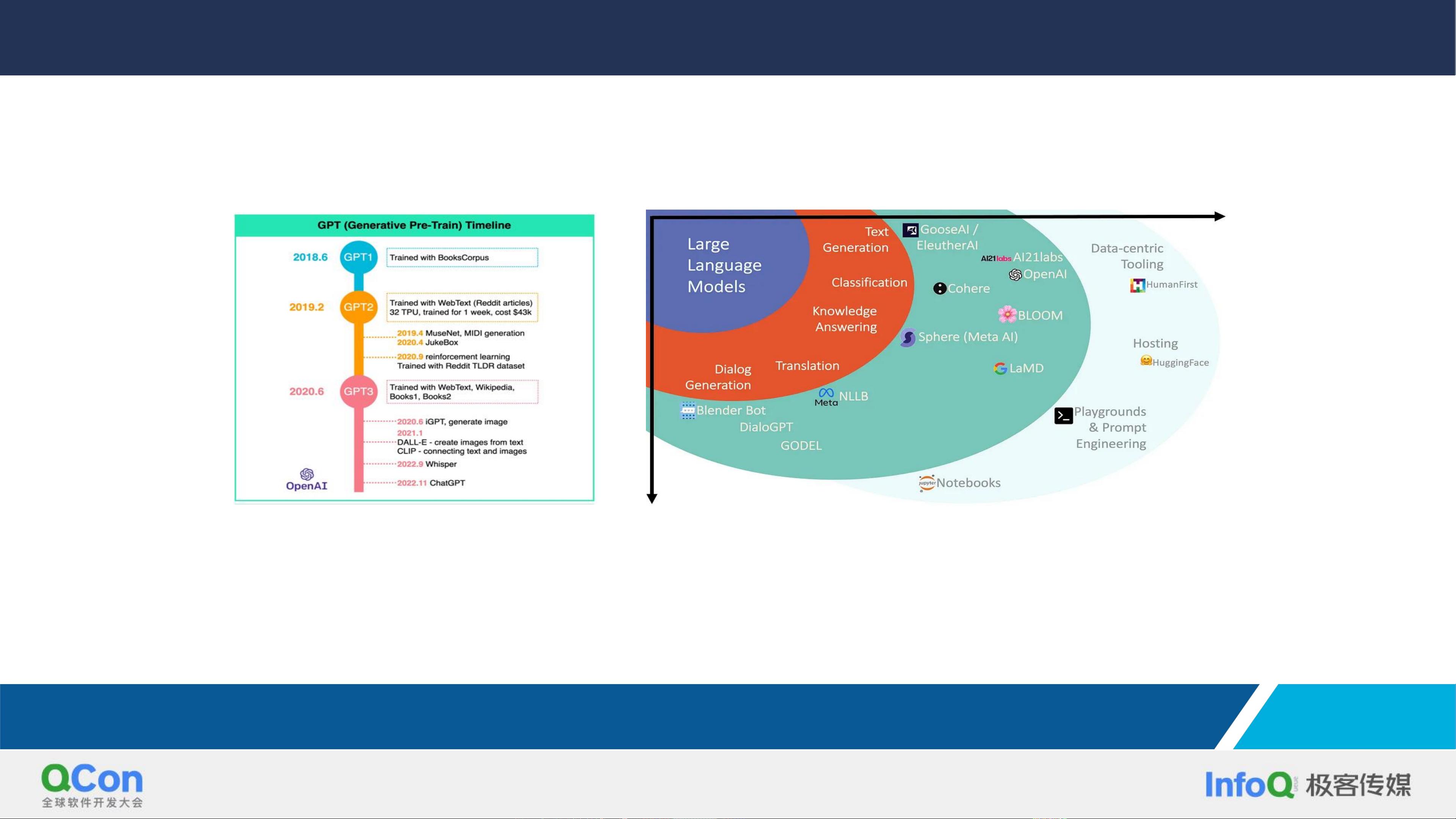
The 5 V’s of Big Data
The study has raised as many questions as it has answered
2
Volume: The size of data grows rapidly and continuously
• China generated 23.9 ZB business data in 2022. It is expected to reach 76.6 ZB in 2027
Velocity: “You cannot afford to make decisions based on yesterday’s data”
• Healthcare, retail, financial services, cyber security, …
Variety: Relational database D, transaction graph G
• Can we write a query across D and G in SQL?
Veracity: The most challenging issue among the 5V’s
• Real-life data is dirty: semantic inconsistencies, duplicates, stale data, missing links
Value : Killer APPs?
• What practical value can we get out of big data?
Big Data: Volume, Variety, Velocity, Veracity, Value