数据分析与数据挖掘算法 kmeans算法介绍 K-均值与层次聚类算法 英文版 共24页.pdf
版权申诉
83 浏览量
2022-06-19
15:30:46
上传
评论
收藏 437KB PDF 举报

1
K-means and
Hierarchical
Clustering
K-means and Hierarchical Clustering: Slide 2
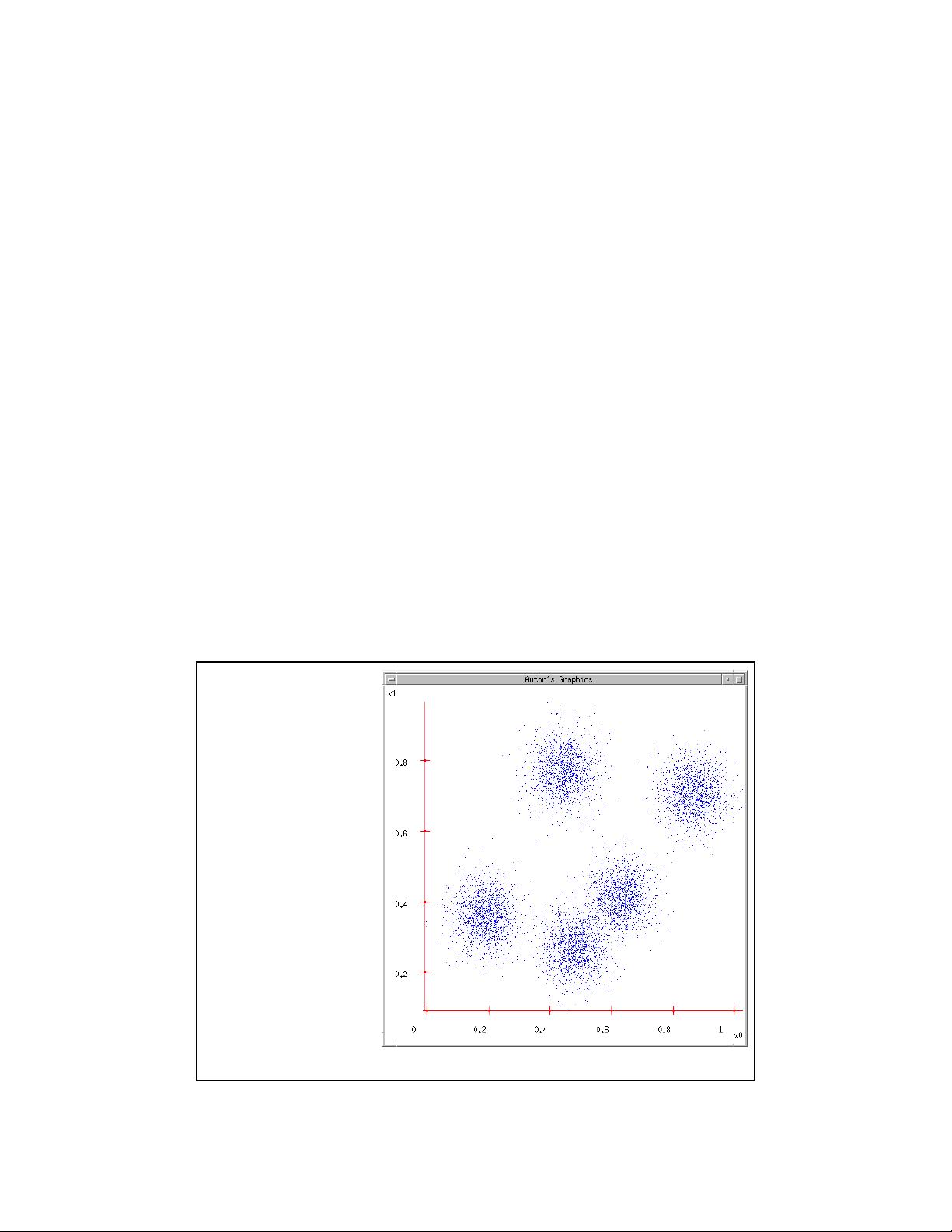
Some
Data
This could easily be
modeled by a
Gaussian Mixture
(with 5 components)
But let’s look at an
satisfying, friendly and
infinitely popular
alternative…
剩余23页未读,继续阅读
资源评论













