
T-SNE 算法随笔
----@Alan 2018.06.16
1. 什么是 t-SNE?
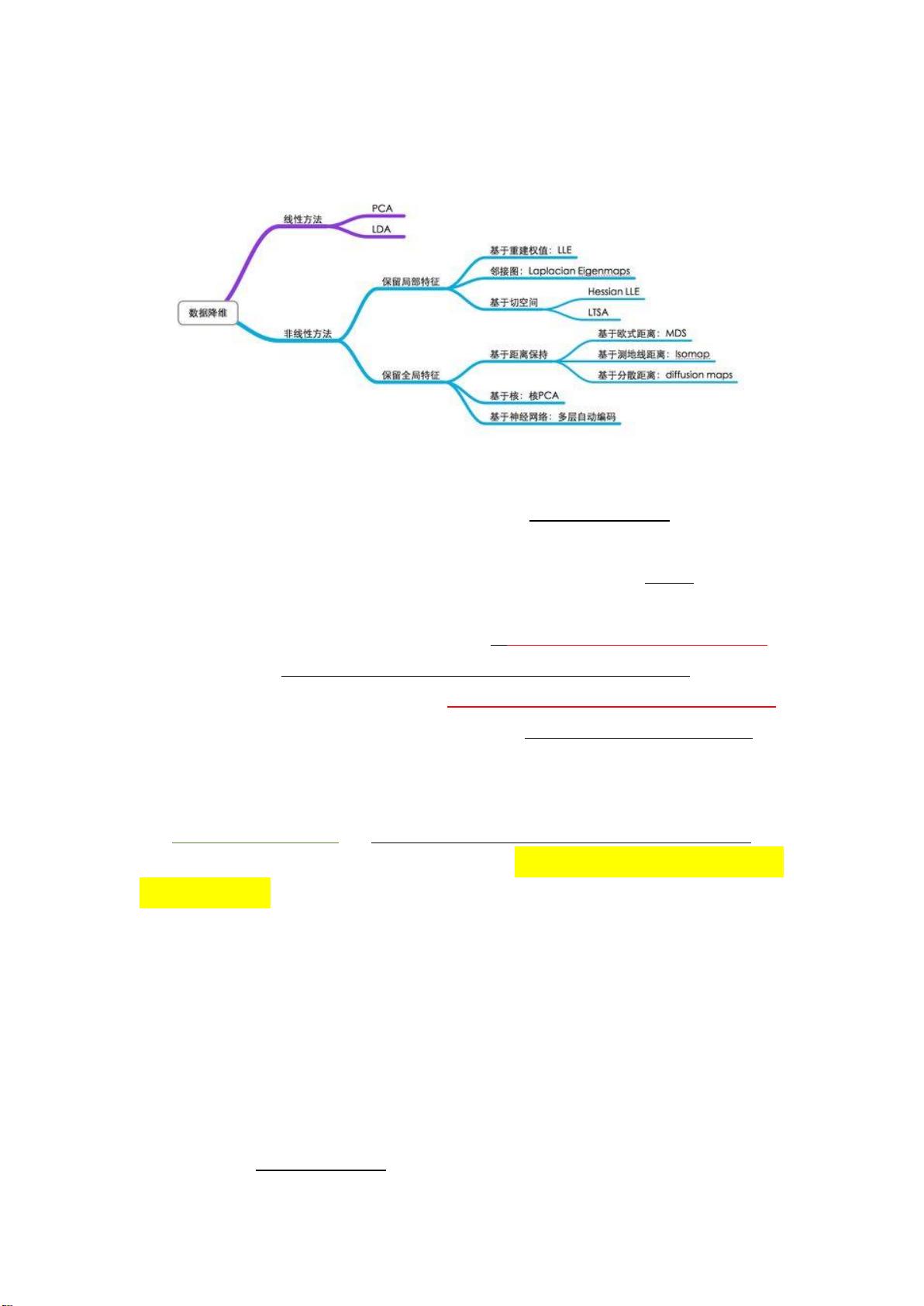
t-SNE(t-distributed stochastic neighbor embedding):t 分布随机邻域嵌入是用于高维数据
的降维算法,是由 Laurens van der Maaten 和 Geoffrey Hinton 在 08 年提出来。此外,t-SNE
是一种非线性降维算法,非常适用于高维数据降到 2 维或者 3 维,进行可视化。
注:
① PCA 的局限性:PCA 是一种线性算法,它不能解释特征之间的复杂多项式关系。
而 t-SNE 是基于在邻域图上随机游走的概率分布来找到数据内的结构。
② 线性降维算法的一个主要问题是:相似的数据点放置在较低维度表示为相距甚远。
但为了在低维度用非线性流形表示高维数据,相似数据点必须表示为非常靠近,这
不是线性降维算法所能做的。
2. t-SNE 可以做什么?
t-SNE 非线性降维算法通过基于具有多个特征的数据点的相似性识别观察到的簇来在
数据中找到模式。本质上是一种降维和可视化技术。另外 t-SNE 的输出可以作为其他分类
算法的输入特征。
3.目前应用领域:t-SNE 几乎可用于所有高维数据集,广泛应用于图像处理,自然语言
处理,基因组数据和语音处理。实例有:面部表情识别、识别肿瘤亚群、使用 wordvec 进行
文本比较等。
t-SNE 是由 SNE(Stochastic Neighbor Embedding, SNE; Hinton and Roweis, 2002)
发展而来。我们先介绍 SNE 的基本原理,再扩展到 t-SNE。
4. SNE 基本原理
SNE 是通过仿射(affinitie)变换将数据点映射到概率分布上,主要包括两个步骤:
资源评论

 普通网友2023-07-24这份文件详尽地介绍了T-SNE算法,简洁易懂,让我对其有了更深入的了解。
普通网友2023-07-24这份文件详尽地介绍了T-SNE算法,简洁易懂,让我对其有了更深入的了解。 余青葭2023-07-24通过对T-SNE算法的介绍,我意识到它在数据可视化方面的优势,这对我的工作很有帮助。
余青葭2023-07-24通过对T-SNE算法的介绍,我意识到它在数据可视化方面的优势,这对我的工作很有帮助。 型爷2023-07-24阅读这篇文件后,我对T-SNE算法的原理和应用有了清晰的认识,受益匪浅。
型爷2023-07-24阅读这篇文件后,我对T-SNE算法的原理和应用有了清晰的认识,受益匪浅。 林书尼2023-07-24这篇文件不仅介绍了T-SNE算法的基本原理,还提到了实际应用中存在的一些挑战,让我对算法的应用有了更全面的认识。
林书尼2023-07-24这篇文件不仅介绍了T-SNE算法的基本原理,还提到了实际应用中存在的一些挑战,让我对算法的应用有了更全面的认识。 仙夜子2023-07-24这篇文章以质朴的语言对T-SNE算法进行了全面阐述,让我对其内部运作有了初步理解。
仙夜子2023-07-24这篇文章以质朴的语言对T-SNE算法进行了全面阐述,让我对其内部运作有了初步理解。

AlanLiked
- 粉丝: 4
- 资源: 9









最新资源
- 证券投资交易分析系统(含源码+项目说明+文档资料+全部资料).zip
- 知识图谱医疗问答系统+前端展示源码(2024毕业设计).zip
- 在线教育培训管理系统(含源码+项目说明+功能模块介绍).zip
- 在线考试系统-基于SpringCloud+Vue3近期开发(遗传算法自动组卷、文本批量导入,含源码+项目说明+设计报告).zip
- 在线流量分类模型-基于CNN+LSTM时空神经网络(含源码+说明文档+设计报告).zip
- 云开发电影院订票小程序(微信小程序源码+项目说明+设计报告).zip
- 云计算实验-利用GitHub进行协作并编写YML测试用例实现持续集成(含文档).zip
- 年度死因数字数据集.zip
- 猜数字游戏,再来一次,点名器,定时器,体彩方案
- 基于Matlab图像识别技术的隐形眼镜镜片边缘缺陷检测源代码
- 在线NFT铸造平台-整合区块链、IPFS与React技术(含源码及设计文档).zip
- 运动想象脑电信号分类-基于Transformer(CNN+局部时间空间特征提取,含源码+项目说明).zip
- 游戏AI强化训练-深度强化学习实战源码(比赛项目).zip
- 游戏空战推演系统源码基于强化学习开发源码(期末大作业).zip
- 期末课设-员工信息管理系统-基于Qt+SQLite数据库(含源码+项目说明+设计报告).zip
- 玉米病害与害虫识别系统源码+农业智能应用报告(课程设计).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


