Elasticsearch(ES)是一种基于Lucene的分布式、RESTful搜索和分析引擎,广泛用于大数据的实时分析和检索。在本讲座中,我们将深入探讨Elasticsearch中的索引概念及其重要性。
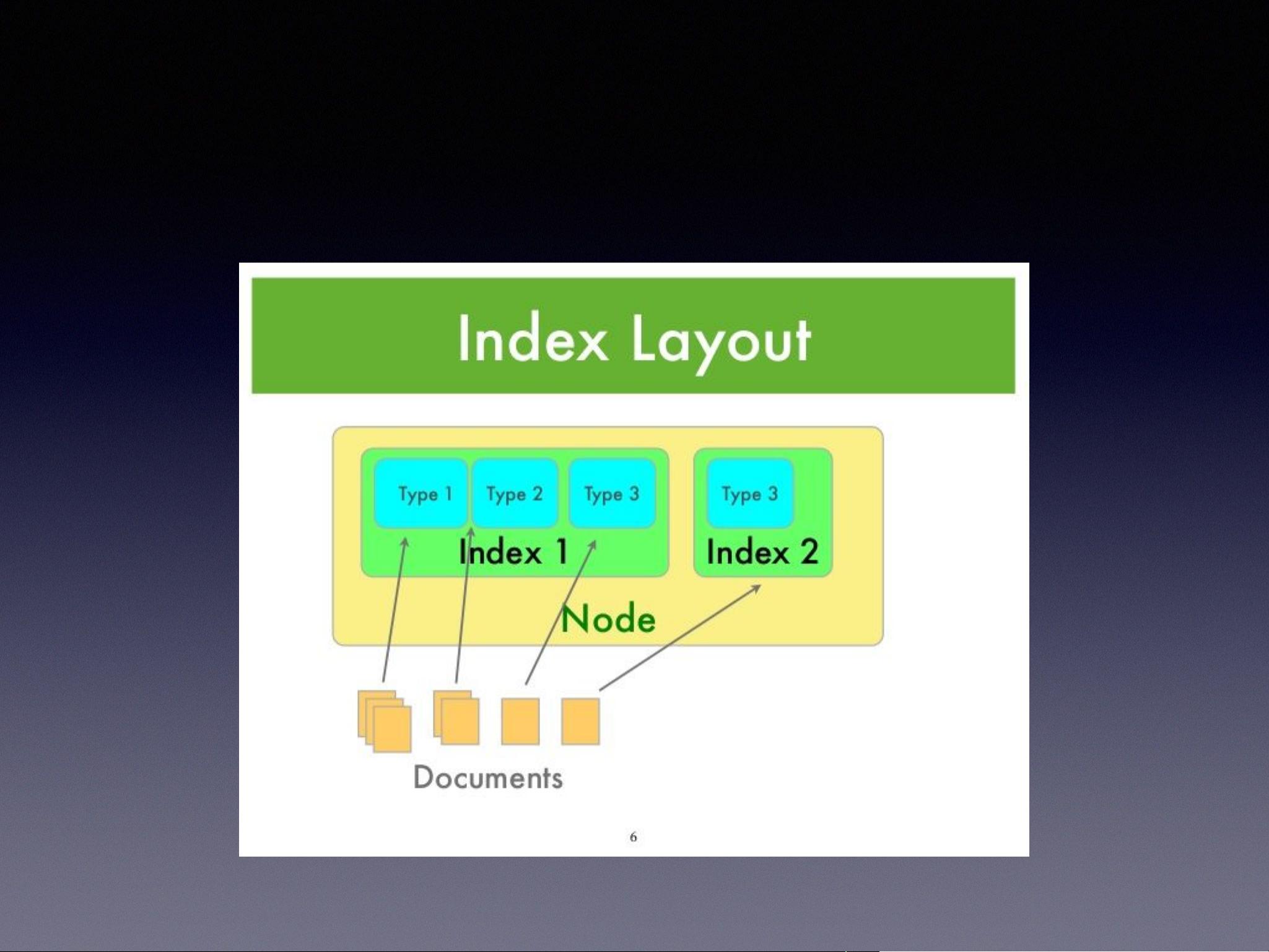
让我们理解一下ES中的“索引”是什么。在MySQL等传统关系型数据库中,索引用于加速查询速度,而在ES中,索引是数据存储和检索的基本单位。每个索引都有一个唯一的名称,如`my_index`,并且可以包含多个类型(在新版本中已被废弃)。索引定义了数据的结构,类似于数据库表的模式。
在ES中,**禁止自动创建索引**可以通过配置`action.auto_create_index`参数来实现。默认情况下,ES允许自动创建索引,但为了更好的管理,可以将其设置为`false`,这样在尝试写入未知索引时,系统将不会自动创建它。这有助于避免意外创建索引或保持索引结构的一致性。
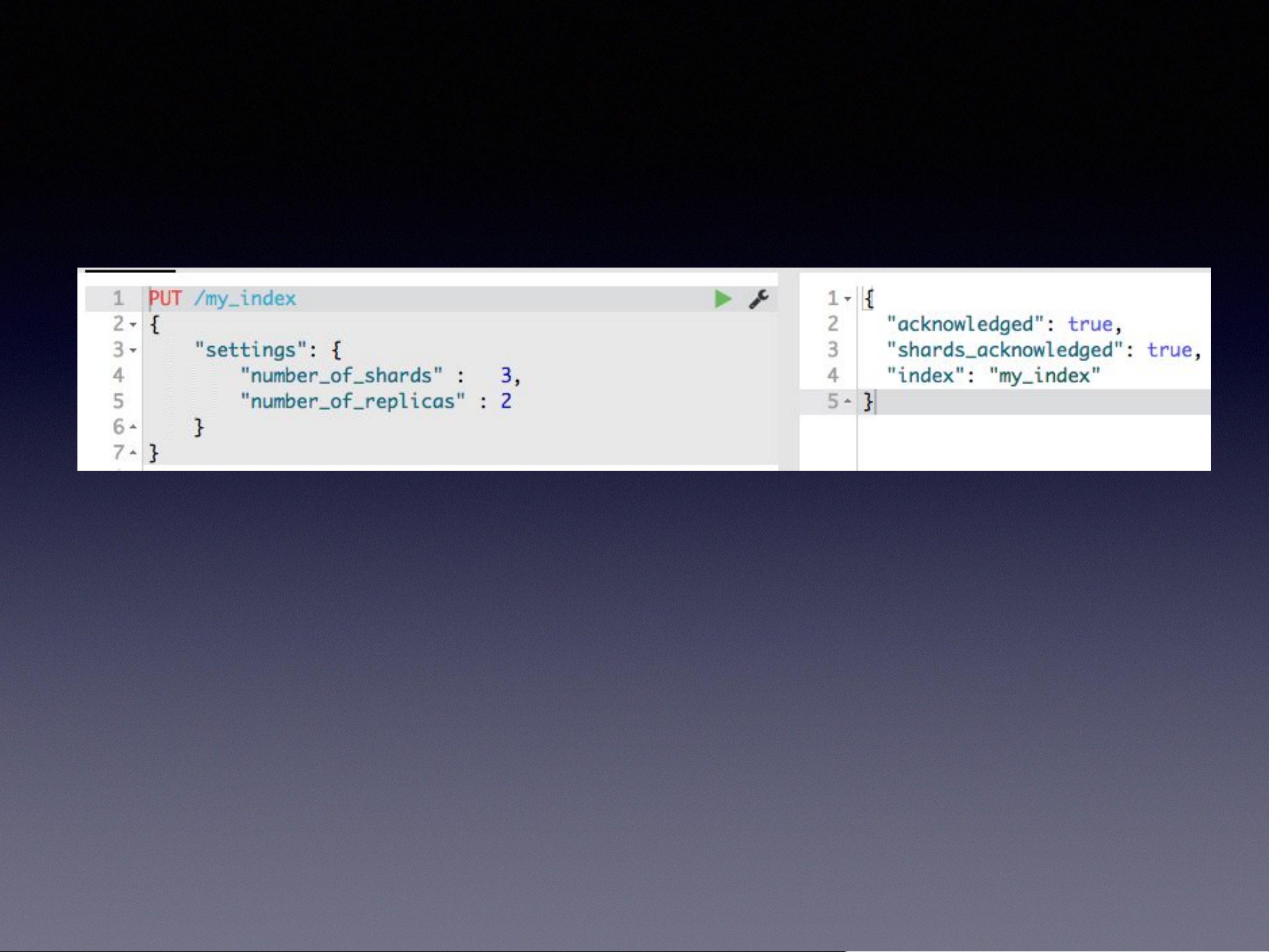
创建索引时,我们需要指定两个关键参数:**number_of_shards**和**number_of_replicas**。**主分片数(number_of_shards)**是数据的初始分割部分,它是不可变的,一旦设定就不能更改。**副本数(number_of_replicas)**则可以动态调整,用于提高容错性和读取性能。每个主分片可以有多个副本,但至少是0。
**查看、创建、删除索引**是基本操作,可以通过相应的API执行。同样,ES中的**类型(Type)**在旧版本中用于组织文档,但在6.x版本后被废弃,所有数据都存储在一个名为`_doc`的隐式类型下。在7.x版本中,完全移除了类型概念。
**创建和搜索文档**是ES的核心功能。文档是ES中的最小数据单元,可以类比为数据库中的记录。当文档被索引时,其内容会被分析并转化为ES可搜索的形式。**字段的索引**决定了它们是否可搜索。如果一个字段被设置为`index=true`,那么它将被索引,可以进行搜索;反之,`index=false`的字段将不会被索引,不能在搜索中使用。
字段类型在ES的新版本中发生了变化,`string`类型被`text`和`keyword`取代。**text**字段用于全文搜索,通常会进行分词处理;而**keyword**字段则用于精确匹配,例如ID或分类,它们不分词,整体进行索引。
**倒排索引**是ES实现快速搜索的关键机制。在索引过程中,每个文档的关键词都会被转换为倒排形式,即关键词指向包含它的文档列表。这种结构使得查找包含特定关键词的文档变得高效。
**自定义分析器**允许我们根据需求调整文本的预处理过程,包括**char_filter**(字符过滤器)、**tokenizer**(分词器)和**filter**(词过滤器)。例如,我们可以创建一个名为`my_analyzer`的分析器,使用内置的`html_strip`字符过滤器去除HTML标签,使用`standard`分词器进行分词,以及`lowercase`过滤器和自定义的`my_stopwords`停用词过滤器,来确保搜索的准确性。
通过以上讲解,你应该对Elasticsearch的索引有了全面的理解。了解并掌握这些基础知识对于在项目中有效利用ES进行数据管理和检索至关重要。在实际应用中,根据具体业务需求定制分析器和调整索引设置,将能更好地优化搜索性能和数据存储。