Sequential Minimal Optimization A Fast Algorithm for Training

需积分: 0 174 浏览量
更新于2023-03-05
收藏 87KB PDF 举报
Sequential Minimal Optimization (SMO) Algorithm for Training Support Vector Machines
SMO 算法是 John C. Platt 于 1998 年提出的一个快速算法,用于训练支持向量机(Support Vector Machines,SVM)。该算法的提出主要是为了解决传统 SVM 训练算法的两个主要问题:计算时间长和内存需求高。
SMO 算法的主要思想是将大型二次规划(Quadratic Programming,QP)问题分解成一系列小型的 QP 问题,每个小型 QP 问题可以通过解析方法解决,从而避免了使用数值优化方法对大型 QP 问题进行求解。这种方法可以显著减少计算时间和内存需求。
SMO 算法的优点包括:
1. 快速计算:SMO 算法可以显著加速 SVM 训练过程,特别是在处理大规模数据集时。
2. 低内存需求:SMO 算法的内存需求与训练集大小呈线性关系,这使得该算法可以处理非常大的训练集。
3. 简单实现:SMO 算法的实现相对简单,易于理解和实现。
SMO 算法的应用前景非常广泛,包括图像识别、自然语言处理、文本分类、生物信息学等领域。
SMO 算法的实现步骤可以概括为以下几个步骤:
1. 数据预处理:对训练数据进行预处理,包括数据 normalization、特征提取等步骤。
2. 初始化:初始化 SVM 模型的参数,包括惩罚参数、kernel 参数等。
3. SMO 算法:使用 SMO 算法来解决 SVM 训练问题,包括将大型 QP 问题分解成小型 QP 问题、解析解决小型 QP 问题、更新 SVM 模型参数等步骤。
4. 模型评估:对训练好的 SVM 模型进行评估,包括计算准确率、召回率、F1 值等指标。
SMO 算法的优点和缺点:
优点:
* 快速计算
* 低内存需求
* 简单实现
缺点:
* 只适用于训练 SVM 模型
* 对于某些数据集,SMO 算法可能不如其他算法快
SMO 算法是一种快速、简单且高效的 SVM 训练算法,适用于解决大规模 SVM 训练问题。

1
Sequential Minimal Optimization:
A Fast Algorithm for Training Support Vector Machines
John C. Platt
Microsoft Research
jplatt@microsoft.com
Technical Report MSR-TR-98-14
April 21, 1998
© 1998 John Platt
ABSTRACT
This paper proposes a new algorithm for training support vector machines: Sequential
Minimal Optimization, or SMO. Training a support vector machine requires the solution of
a very large quadratic programming (QP) optimization problem. SMO breaks this large
QP problem into a series of smallest possible QP problems. These small QP problems are
solved analytically, which avoids using a time-consuming numerical QP optimization as an
inner loop. The amount of memory required for SMO is linear in the training set size,
which allows SMO to handle very large training sets. Because matrix computation is
avoided, SMO scales somewhere between linear and quadratic in the training set size for
various test problems, while the standard chunking SVM algorithm scales somewhere
between linear and cubic in the training set size. SMO’s computation time is dominated by
SVM evaluation, hence SMO is fastest for linear SVMs and sparse data sets. On real-
world sparse data sets, SMO can be more than 1000 times faster than the chunking
algorithm.
1. INTRODUCTION
In the last few years, there has been a surge of interest in Support Vector Machines (SVMs) [19]
[20] [4]. SVMs have empirically been shown to give good generalization performance on a wide
variety of problems such as handwritten character recognition [12], face detection [15], pedestrian
detection [14], and text categorization [9].
However, the use of SVMs is still limited to a small group of researchers. One possible reason is
that training algorithms for SVMs are slow, especially for large problems. Another explanation is
that SVM training algorithms are complex, subtle, and difficult for an average engineer to
implement.
This paper describes a new SVM learning algorithm that is conceptually simple, easy to
implement, is generally faster, and has better scaling properties for difficult SVM problems than
the standard SVM training algorithm. The new SVM learning algorithm is called Sequential
Minimal Optimization (or SMO). Instead of previous SVM learning algorithms that use
numerical quadratic programming (QP) as an inner loop, SMO uses an analytic QP step.
This paper first provides an overview of SVMs and a review of current SVM training algorithms.
The SMO algorithm is then presented in detail, including the solution to the analytic QP step,
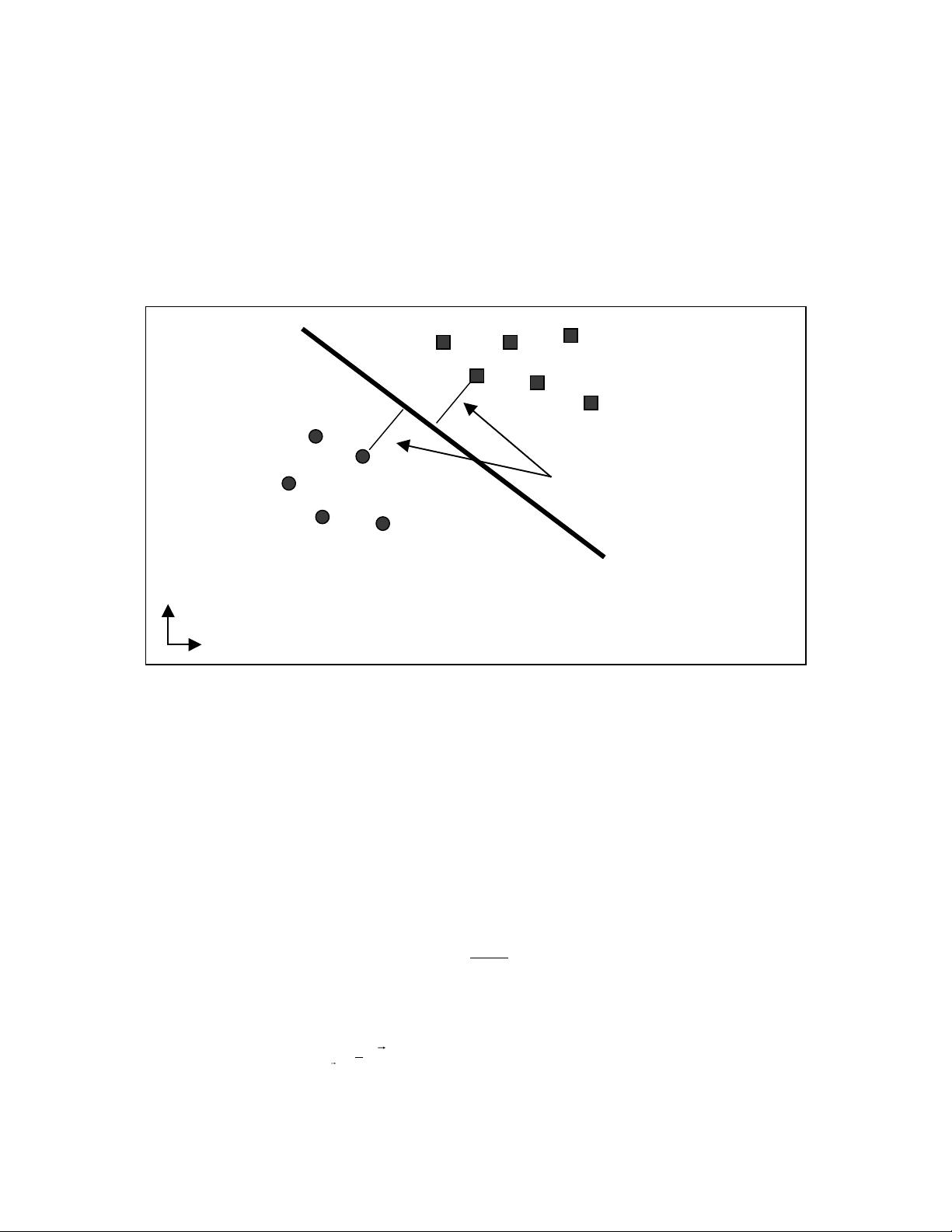


剩余20页未读,继续阅读
101 浏览量
122 浏览量
2021-05-30 上传
141 浏览量
192 浏览量
2019-10-31 上传
2019-08-10 上传
2021-04-11 上传
101 浏览量
120 浏览量
137 浏览量
186 浏览量
2023-08-25 上传
150 浏览量
2022-01-08 上传
2023-08-25 上传
188 浏览量
192 浏览量
130 浏览量
183 浏览量
资源评论



楼兰小石头
- 粉丝: 118
- 资源: 15









最新资源
- 汽车锁(世界锁)全自动检测设备机械设计结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- Docker & Docker-Compose资源获取下载.zip
- 基于HTML、Java、JavaScript、CSS的Flowermall线上花卉商城设计源码
- 基于SSM框架和微信小程序的订餐管理系统点餐功能源码
- 基于freeRTOS和STM32F103x的手机远程控制浴室温度系统设计源码
- 基于Java语言的经典设计模式源码解析与应用
- 桥墩冲刷实验水槽工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- 基于物联网与可视化技术的ECIOT集成设计源码
- 基于Vue和微信小程序的JavaScript广告投放demo设计源码
- 基于layui框架的省市复选框组件设计源码
- 基于HTML、CSS、Python技术的学生先群网(asgnet.cn, efsdw.cn)设计源码
- 基于Vue、TypeScript、CSS、HTML的vite_project废弃Vue项目设计源码
- 基于微信小程序的童书租借系统设计源码
- 基于Python和JavaScript的车辆牌照识别系统设计源码
- 基于Spring Boot和Vue的校园健康管理系统设计源码
- 基于Python的滑动验证码设计源码下载
